SPSS统计分析高级教程的目录
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SPSS统计分析高级教程的目录相关的知识,希望对你有一定的参考价值。
参考技术A第一部分一般线性与混合线性模型.
第1章方差分析模型
1.1模型简介
1.1.1模型入门
1.1.2常用术语
1.1.3方差分析模型的适用条件
1.2简单分析实例
1.2.1模型表达式
1.2.2初步分析结果
1.2.3模型参数的估计值
1.2.4两两比较
1.2.5其他常用选项
1.3两因素方差分析模型
1.3.1分析实例
1.3.2边际均数与轮廓图
1.3.3拟和劣度检验
1.4因素各水平间的精细比较
1.4.1POSTHOC子句
1.4.2EMMEANS子句
1.4.3LMATRIX和KMATRIX子句
1.4.4CONSTRAST子句
1.5随机因素的方差分析模型
1.6其他问题
1.6.1自定义效应检验使用的误差项
1.6.2四类方差分解方法
第2章常用实验设计分析方法
2.1仅研究主效应的实验设计方案
2.1.1完全随机设计(CompletelyRandomDesign)
2.1.2配伍组设计(RandomizedBlockDesign)
2.1.3交叉设计(Cross-overDesign)
2.1.4拉丁方设计(LatinSquareDesign)
2.2考虑交互作用的实验设计方案
2.2.1析因设计(FactorialDesign)
2.2.2正交设计(OrthogonalDesign)
2.2.3均匀设计(UniformDesign)
2.3误差项变动的特殊实验设计方案
2.3.1嵌套设计(NestedDesign)
2.3.2重复测量设计(RepeatedMeasureDesign)
2.3.3裂区设计(Split-plotDesign)
2.4协方差分析(AnalysisofCovariance)
2.4.1协方差分析的必要性
2.4.2平行性假定的检验
2.4.3计算和检验修正均数
第3章多元方差分析与重复测量方差分析
3.1多元方差分析
3.1.1模型简介
3.2.2分析实例
3.3.3检验统计量的计算
3.3.4对引例的进一步分析
3.2重复测量资料的方差分析
3.2.1模型简介
3.2.2分析实例
第4章混合线性模型入门
4.1模型简介
4.1.1问题的提出
4.1.2模型入门
4.2层次聚集性数据分析实例
4.1.1拟合混合线性模型的基本结构
4.1.2在固定效应中加入自变量
4.1.3在随机效应中加入自变量
4.1.4更多解释变量的引入
4.1.5其他常用选项
4.3重复测量数据分析实例
4.3.1对数据的初步分析
4.3.2拟合混合线性模型的基本结构
4.3.3考虑重复测量间的相关性
4.3.4更改对测量间相关性的假定
4.3.5模型中可用的相关阵种类
4.4本章方法小结
4.4.1混合效应模型的用途
4.4.2混合效应模型与一般线性模型的联系
第二部分回归模型
第5章多重线性回归模型
5.1模型简介
5.2简单分析实例
5.2.1对数据的初步分析
5.2.2回归模型的假设检验
5.2.3偏回归系数的假设检验
5.2.4标准化偏回归系数
5.2.5衡量多元线性回归模型优劣的标准
5.3回归预测与残差分析
5.3.1回归预测与区间估计
5.3.2残差分析与模型适用条件的检验
5.4逐步回归
5.4.1筛选自变量的基本原则
5.4.2常用的逐步回归方法
5.4.3分析实例
5.5模型的进一步诊断与修正
5.5.1强影响点的识别与处理
5.5.2多重共线性的识别与处理
5.6本章方法小结
5.6.1回归模型的建立步骤
5.6.2多重线性回归模型结果解释时应注意的问题
第6章线性回归的衍生模型
6.1非直线趋势的处理:曲线直线化
6.1.1方法简介
6.1.2使用Linear过程进行分析
6.1.3使用曲线拟合过程分析
6.2方差不齐的处理:加权最小二乘法
6.2.1方法简介
6.2.2使用Linear过程进行分析
6.2.3使用WLS过程分析
6.3共线性的处理:岭回归
6.3.1方法简介
6.3.2分析实例
6.4分类变量的数值化:最优尺度回归
6.4.1方法简介
6.4.2分析实例
6.4.3最优尺度方法的应用注意事项
第7章路径分析入门
7.1两阶段最小二乘法
7.1.1模型简介
7.1.2 使用Linear过程进行分析
7.1.3使用2SLS过程进行分析
7.2路径分析入门
7.2.1模型简介
7.2.2分析实例
第8章非线性回归模型
8.1模型简介
8.1.1问题的提出
8.1.2模型入门
8.2简单分析实例
8.2.1软件操作与界面说明
8.2.2基本分析结果
8.2.3模型的进一步分析
8.3自定义损失函数:最小一乘法实例
8.3.1分析实例
8.3.3结果解释
8.4分段回归模型的拟合
8.4.1分析实例
8.4.2结果解释
8.4.3模型的进一步分析
8.5其他需要注意的问题
8.5.1参数初始值的设定
8.5.2模型的拟合方法
第9章二分类logistic回归模型
9.1模型简介
9.1.1模型入门
9.1.2一些基本概念
9.2简单分析实例
9.3分类自变量的定义与比较方法
9.3.1使用哑变量的必要性
9.3.2SPSS中预设的哑变量编码方式
9.3.3设置哑变量时要注意的问题
9.4自变量的筛选方法与逐步回归
9.4.1模型中的假设检验方法
9.4.2自变量的筛选方法
9.4.3分析实例
9.5模型拟合效果与拟合优度检验
9.5.1模型效果的判断指标
9.5.2拟合优度检验
9.6模型的诊断与修正
9.6.1残差分析
9.6.2多重共线性的识别及其对回归系数的影响及处理办法
第10章多分类.配对logistic回归与probit回归
10.1有序多分类logistic回归模型
10.1.1模型简介
10.1.2分析实例
10.1.3模型适用条件的检验
10.2无序多分类logistic回归模型
10.2.1模型简介
10.2.2分析实例
10.31:1配对logistic回归
10.3.1模型简介
10.3.2分析实例
10.4probit回归模型
10.4.1模型简介
10.4.2实例一:与logistic模型比较
10.4.3实例二:计算LD50
第三部分多元统计分析方法
第11章主成分分析与因子分析
11.1主成分分析
11.1.1模型入门..
11.1.2简单分析实例
11.1.3对主成分分析的进一步说明
11.2因子分析
11.2.1模型入门
11.2.4简单分析实例
11.3因子分析的进一步讨论
11.3.1不同的因子分析法
11.3.2相关阵和协方差
11.3.3确定公因子数量
11.4因子分析综合案例
11.5主成分分析和因子分析的比较
第12章聚类分析
12.1模型简介
12.1.1问题的提出
12.1.2聚类分析入门
12.1.3聚类分析的方法体系
12.2层次聚类法
12.2.1方法原理
12.2.2分析实例
12.2.3对层次聚类法的进一步讨论
12.3K-均值聚类法
12.3.1方法原理
12.3.2分析实例
12.4两步聚类法简介
12.4.1方法原理
12.4.2分析实例
12.5本章方法小结
第13章判别分析
13.1模型简介
13.1.1典型判别分析的基本原理
13.1.2判别分析的适用条件和违背条件时的处理方法
13.1.3判别效果的评价
13.1.4判别分析的一般步骤
13.2简单分析实例
13.2.1软件操作与界面说明
13.2.2基本分析结果
13.2.3判别结果的图形化展示
13.2.4判别效果的验证
13.2.5适用条件的判断方法
13.3贝叶斯判别分析
13.3.1方法原理
13.3.2软件实现
13.4对判别分析的进一步讨论
13.4.1逐步判别分析
13.4.2判别分析和因子分析的相似性和差异
13.4.3二类判别和多重回归的等价性
第14章典型相关分析
14.1方法介绍
14.1.1典型相关分析的基本思想
14.2.1典型相关分析的数学描述
14.2分析实例
14.2.1两组变量间的相关系数
14.2.2典型相关系数及显著性检验
11.2.3典型变量的系数
14.2.4典型结构分析
14.2.5典型冗余分析
14.3本章方法小结
14.3.1典型相关分析的应用
14.3.2典型相关分析和因子分析
第15章对应分析
15.1模型简介
15.1.1问题的提出
15.1.2模型入门
15.1.3SPSS中的相应功能
15.2简单分析实例
15.2.1对数据的初步分析
15.2.2正式分析
15.2.3对引例的进一步分析
15.3基于均数的对应分析
15.3.1方法原理
15.3.2分析实例
15.4多重对应分析
15.4.1方法原理
15.4.2分析实例
15.5对应分析中的其它问题
15.5.1对应分析结果的正确解释
15.5.2罕见类别和相似类别的处理
15.5.3有序类别的处理
15.6本章方法小结
15.6.1对应分析与其它分析方法的关系
15.6.2对应分析的优势与劣势
第16章多维尺度分析
16.1古典MDS模型
16.1.1方法原理
16.1.2分析实例
16.1.3距离的计算方式
16.2非度量MDS模型
16.2.1数据测量尺度的设定
16.2.2方法原理
16.2.3分析实例
16.3考虑个体差异的MDS模型
16.3.1方法原理
16.3.2分析实例
16.3.3空间定位图的含义解释
16.4基于最优尺度变换的MDS模型
16.4.1方法简介
16.4.2分析实例
16.5本章方法小结
第四部分其他统计分析方法
第17章对数线性模型与Poisson回归
17.1对数线性模型简介
17.1.1问题的提出
17.1.2模型入门
17.1.3SPSS的相应功能
17.2一般对数线性模型分析实例
17.2.1对数据的初步分析
17.2.2正式分析
17.2.3对引例的进一步分析
17.3因果关系明确时的对数线性模型
17.4对数线性模型的选择
17.4.1模型的选择策略
17.4.2分析实例
17.5对数线性模型与其它模型的关系
17.5.1对数线性模型与方差分析模型的关系
17.5.2对数线性模型与Logistic回归的关系
17.6Poisson回归模型
17.6.1模型简介
17.6.2分析实例
第18章信度分析
18.1信度理论入门
18.1.1真分数测量理论
18.1.2信度与效度
18.1.3内在信度与外在信度
18.1.4信度的判断标准
18.2简单分析实例
18.2.1Alpha信度系数
18.2.2对各题目的深入分析
18.2.3对真分数理论假设的考察
18.3其余常用的信度系数
18.3.1重测信度
18.3.2折半信度
18.3.3Guttman系数
18.3.4平行模型的信度系数
18.3.5严格平行模型的信度系数
18.3.6评分者信度
18.3.7信度系数总结
18.4信度理论进阶
18.4.1真分数测量理论的缺限
18.4.2概化理论入门
18.4.3SPSS中相应的分析功能
第19章生存分析
19.1生存分析简介
19.1.1生存分析简史
19.1.2生存分析中的基本概念
19.1.3生存分析的基本步骤
19.1.4SPSS与生存分析
19.2生存函数的估计和检验
19.2.1生存函数的基本估计方法
19.2.2Kaplan-Meier法
19.2.3寿命表法
19.2.4Kaplan-Meier法和寿命表法比较
19.3Cox回归模型
19.3.1Cox模型入门
19.3.2分析实例
19.3.3比例风险性的图形验证
19.4含时间依存性变量的Cox模型
19.4.1时依协变量的种类
19.4.2用时依模型验证比例风险性
19.4.3用时依模型评价处理因素的影响
19.4.4用时依模型评价重复测量因子的影响
19.5关于Cox模型的一些高级话题
19.5.1生存分析中的分层变量
19.5.2用Cox回归过程拟合配伍Logistic回归
19.5.3竞争风险的Cox模型
第20章缺失值分析入门
20.1缺失值理论简介
20.1.1数据的缺失机制
20.1.2SPSS中对缺失值的处理方法
20.2对缺失情况的基本分析
20.2.1缺失值数据的生成
20.2.2对缺失模式的分析
20.2.3缺失情况的统计描述
20.3缺失值填充技术
20.3.1列表输出
20.3.2使用回归算法进行填充
20.3.3使用EM算法进行填充
20.3.4多重填充技术简介
思考与练习
参考文献
附录...

SPSS两配对样本T检验分析详细操作教程(附案例实战)

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
【SPSS】专栏正在不断更新中,感兴趣的小伙伴可以点个订阅支持一下
推断统计与参数检验

推断统计
- 推断统计方法是根据样本数据推断总体特征的方法
- 推断统计包括参数估计 (点估计和区间估计)和假设检验两大类
参数检验 VS 非参数检验
- 参数检验(参数假设检验)
总体分布已知 (如总体为正态分布)的情况下,根据样本数据对总体分布的统计参数(如均值、方差等)进行推断
- 非参数检验(非参数假设检验)
总体分布未知的情况下,根据样本数据对总体的分布形式或数字特征进行推断
假设检验

假设检验的基本思想
1 首先,对总体参数值提出假设
2 然后,利用样本告知的信息去验证先前提出的假设是否成立
- 如果样本数据不能够充分证明和支持假设,则应拒绝假设
- 如果样本数据能够充分证明和支持假设,则不能推翻假设
小概率原理:
- 发生概率很小的随机事件在某一次特定的实验中是几乎不可能发生的
- 小概率原理是假设检验所依据的原理
假设检验的基本步骤
1.提出原假设(记为H0 )和备择假设(记为H1 ) 通常,将希望推翻的假设放在原假设上
2.选择检验统计量:检验统计量服从或近似服从某种已知的理论分布
3.计算概率P值:在认为原假设成立的条件下,根据样本数据和检验统计量计算 概率P值,该概率值间接地给出了样本值(或更极端值)在原假设成 立条件下发生的概率,即:P(拒绝H0|H0为真)
4.给定显著性水平α,并作出统计决策:显著性水平α是在原假设H0正确的前提下却拒绝原假设的概率,即“弃真”概率,一般设定为 0.05或0.01 若概率P值小于等于α,拒绝原假设;否则,不能拒绝原假设
两配对样本t检验

两配对样本t检验介绍
- 配对样本的含义:可以是个案在“前” “后”两种状态下某属性的两种不同特征
- 配对样本的特征
- 两个样本的样本量相同
- 两个样本观测值的先后顺序是一 一对应的,不能随意更改
- 目的:利用来自两个总体的配对样本,推断两个总体的均值是否存在显著差异
例如:为研究某减肥茶是否有显著的减肥效果,需要对抽取的肥胖人群喝茶前与喝茶后的体重进行分析。
两配对样本t检验的基本步骤
两配对样本t检验是通过单样本t检验来实现的,即最终转化成对 差值样本总体均值是否与0有显著差异做检验。
1 提出原假设 H0 :μ1 -μ2=0
2 选择检验统计量
3 计算检验统计量的观测值和概率P值
4 给定显著性水平α,并作出决策
两配对样本t检验的应用

【案例】 为研究某种减肥茶是否具有明显的减肥效果,某机构对35名肥胖志愿者进行了减肥跟踪调研。首先将其喝减肥茶以前的体重记录下来,三个月后再依次将这35名志愿者喝茶后的体重记录下来。通过这两组样本数据的对比分析,推断减肥茶是否具有明显的减肥作用。
操作步骤:
①选择菜单【分析】----> 【比较均值】----> 【配对样本T检验】
②选择配对检验变量到【配对变量(V)】框中
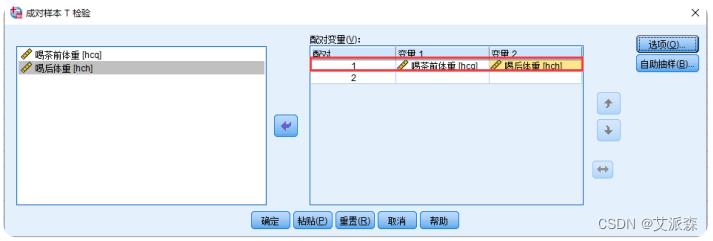
③分析结果如下:

结论:由第一个表可以看出,喝茶前与喝茶后样本的平均值有较大差异,这种差距是由偶然的还是系统性的,还需要进一步检验。
第二个表描述了喝茶前后的线性相关性,说明喝茶前与喝茶后体重的线性相关程度较弱。
第三个表中t检验统计量观测值对应的双侧概率P值接近0,小于显著性水平α,应该拒绝原假设,即认为减肥前后体重差的总体平均值与0有显著不同,意味着喝茶前与喝茶后的体重平均值存在显著差异,可以认为该减肥茶具有显著的减肥效果。
以上是关于SPSS统计分析高级教程的目录的主要内容,如果未能解决你的问题,请参考以下文章