python怎么定位富文框textarea的元素?我用xpath定位包找不到元素
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python怎么定位富文框textarea的元素?我用xpath定位包找不到元素相关的知识,希望对你有一定的参考价值。
富文本怎么传值
参考技术A selenium,一个有效的自动化测试工具,我主要介绍下关于如何封装WebDriver,为一个比较轻松上手的自动化测试埋下铺垫工具/原料
selenium-server-standalone-2.39.0.jar软件包
方法/步骤
先了解下什么是WebDriver
熟悉WebDriver的关于JAVA的一些API的使用
介绍一个火狐的插件firepath
我做的自动化测试是在火狐上运行的,因为我找到一个对于自动化测试比较有帮助的插件,那就是firepath,具体用法,就是先安装该插件,它会在firebug那么调试的窗口最右边出现。firepath截图和firepath安装后的截图如下所示。(优点:点哪个元素,哪个元素的xpath路径立马显示,看图吧)
自己封装的WebDriver的API方法
package com.qiang.data;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import org.openqa.selenium.By;
import org.openqa.selenium.NoSuchElementException;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
/**
* WebDriver帮助类
*/
public class WebDriverUtil
/**
* 写在前面的话:
* 我写的这个WebDriver帮助类法仅仅针对于xpath访问的
* 为什么这么写呢?有两点理由
* 其一:xpath获取方便,我用的是firefox浏览器,只要用firepath这个插件,我们就可以正确的定位到每一个节点,并且firepath支持查询功能,值得大家使用
* 其二:使用统一的xpath,给编码带来了一定的规范
*/
/**
* 没有验证码的的登录
* @param wd WebDriver对象
* @param unameXpath 用户名的xpath路径
* @param uname 用户名
* @param pwdXpath 密码xpath路径
* @param pwdValue 密码
* @param loginBtnXpath 登录按钮xpath
*/
public static void login(WebDriver wd,String url,String unameXpath,String uname,String pwdXpath,String pwd,String loginBtnXpath)
wd.get(url);
inputs(wd,unameXpath,uname);
inputs(wd,pwdXpath, pwd);
click(wd,loginBtnXpath);
/**
* 登录可能放在一个frame里了:我是因为遇到过,所以才加了个方法的
* @param wd WebDriver对象
* @param unameXpath 用户名的xpath路径
* @param uname 用户名
* @param pwdXpath 密码xpath路径
* @param pwdValue 密码
* @param loginBtnXpath 登录按钮xpath
* @param frame 第几个框架
*/
public static void loginFrame(WebDriver wd,String url,String unameXpath,String uname,String pwdXpath,String pwd,String loginBtnXpath,int frame)
wd.get(url);
wd.switchTo().frame(frame);
inputs(wd,unameXpath,uname);
inputs(wd,pwdXpath, pwd);
click(wd,loginBtnXpath);
/**
* 有验证码的登录
* @param wd WebDriver对象
* @param unameXpath 用户名的xpath路径
* @param uname 用户名
* @param pwdXpath 密码xpath路径
* @param pwdValue 密码
* @param loginBtnXpath 登录按钮xpath
* @param seconds 输入验证码的间隔
*/
public static void loginVerify(WebDriver wd,String url,String unameXpath,String uname,String pwdXpath,String pwd,String loginBtnXpath,int seconds)
wd.get(url);
inputs(wd,unameXpath,uname);
inputs(wd,pwdXpath, pwd);
try
Thread.sleep(seconds*1000); //这段时间内请输入验证码
catch (InterruptedException e)
e.printStackTrace();
click(wd,loginBtnXpath);
/**
* 获取页面单个元素
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static WebElement getElement(WebDriver wd,String xpath)
return wd.findElement(By.xpath(xpath));
/**
* 获取页面的一组元素
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static List<WebElement> getElements(WebDriver wd,String xpath)
return wd.findElements(By.xpath(xpath));
/**
* 获取元素节点的文本值
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static String getText(WebDriver wd,String xpath)
return wd.findElement(By.xpath(xpath)).getText();
/**
* 获取元素节点的文本值
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return 没有找到该元素时会有个提示,并且不会报错,建议使用
*/
public static String getExistText(WebDriver wd,String xpath)
if(isExist(wd, xpath))
return getText(wd, xpath);
return "-1";
/**
* 获取元素节点的属性值
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @attribute 要获取目标节点的哪个属性
* @return
*/
public static String getAttribute(WebDriver wd,String xpath,String attribute)
return wd.findElement(By.xpath(xpath)).getAttribute(attribute);
/**
* 点击节点
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static void click(WebDriver wd,String xpath)
wd.findElement(By.xpath(xpath)).click();
/**
* 输入文本
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static void inputs(WebDriver wd,String xpath,String value)
wd.findElement(By.xpath(xpath)).sendKeys(value);
/**
* 判断是否选中
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static boolean isChecked(WebDriver wd,String xpath)
return wd.findElement(By.xpath(xpath)).isSelected();
/**
* 判断是否可用
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static boolean isEnabled(WebDriver wd,String xpath)
return wd.findElement(By.xpath(xpath)).isEnabled();
/**
* 判断是否存在元素
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
* @return
*/
public static boolean isExist(WebDriver wd,String xpath)
try
wd.findElement(By.xpath(xpath));
return true;
catch (NoSuchElementException e)
return false;
/**
* 选中复选框,其实和点击一样,只是重新起了个名字
* @param wd WebDriver对象
* @param xpath 目标节点的xpath
*/
public static void check(WebDriver wd,String xpath)
click(wd, xpath);
/**
* 点击那种隐藏的下拉框
* @param wd WebDriver对象
* @param xpath1 事件源节点的xpath
* @param xpath2 目标节点的xpath
*/
public static void clickHidden(WebDriver wd,String xpath1,String xpath2)
click(wd, xpath1);
click(wd, xpath2);
/**
* 获取隐藏的文本,原理同上
* @param wd WebDriver对象
* @param xpath1 事件源节点的xpath
* @param xpath2 目标节点的xpath
*/
public static void getHiddenText(WebDriver wd,String xpath1,String xpath2)
click(wd, xpath1);
getText(wd, xpath2);
/**
* 获取隐藏节点的属性值
* @param wd WebDriver对象
* @param xpath1 事件源节点的xpath
* @param xpath2 目标节点的xpath
* @param attribute 要获取目标节点的哪个属性
*/
public static String getHiddenAttribute(WebDriver wd,String xpath1,String xpath2,String attribute)
click(wd, xpath1);
return getAttribute(wd, xpath2, attribute);
/**
* 切换窗口
* @param wd WebDriver对象
* @param title 要切换窗口的标题
*/
public static void changeWindow(WebDriver wd,String title)
String current = wd.getWindowHandle();
Set<String> all = wd.getWindowHandles();
Iterator<String> iterator = all.iterator();
while (iterator.hasNext())
String handle = iterator.next();
if(handle.equals(current))
continue;
else
wd.switchTo().window(handle);
if(wd.getTitle().contains(title))
System.out.println("窗口成功跳转");
break;
else
continue;
5
个人小结
以上基于WebDriver简单的封装在一定程度上可以减少代码量,封装得太少,看到的你根据自己的需要进行扩充吧,我个人特点是喜欢封装一切可以复用的代码,以便达到高效率的编码,并不是说会编码就够了,多总结总结还是会让自己的编码路不会走的那么崎岖些
富文本粘贴文本去除默认格式
在我们开发过程中,经常用到的文本输入框,常用的是input/textarea。然而在有些情况下,input/textarea可能满足不了我们的业务需求,textarea/input大部分是处理纯文本,不能附加一些自定义样式,文本域内业务操作空间也不怎么大,但是富文本,即可以编辑的HTML,可以针对输入内容做任意自定义处理,因此,在特定业务需求下,富文本编辑更符合我们的实际业务要求。
富文本基本使用:只需要给HTML标签添加一个contenteditable=‘true’即可完成普通HTML与富文本的转换,效果如下:
<section> <h3>富文本编辑器</h3> <div style="height: 300px;width: 300px;background: #eee;" contenteditable="true"></div> </section>

当我们输入的时候,是输入普通的文本,具体样式以我们设置的css为准。当我们复制文本的时候,默认会把所有的样式复制进去,如下所示:
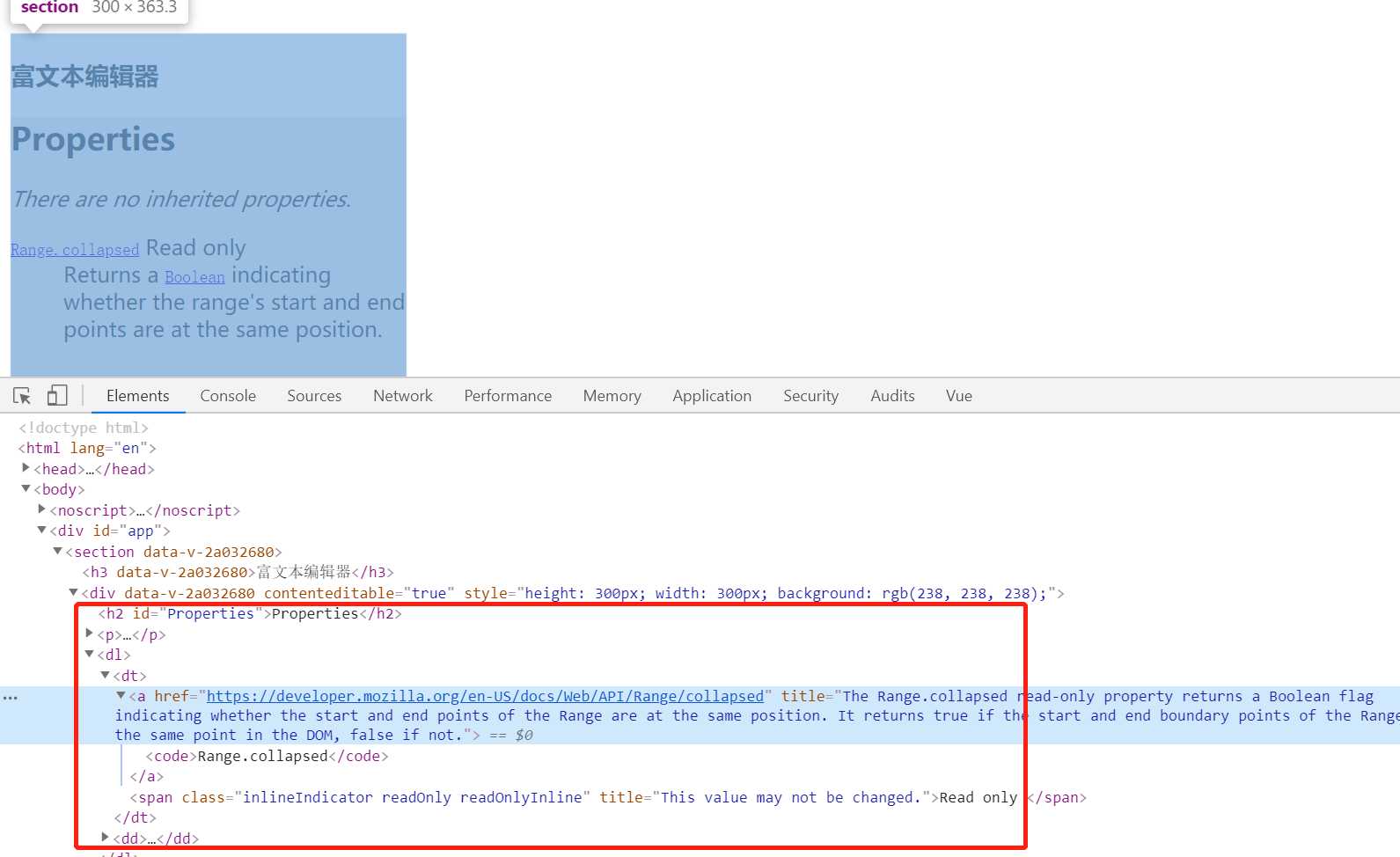
这一点有时候也是比较繁琐的,可能我们并不需要这些默认样式,我们只想要复制的文本,按照我们的要求进行转换,此时可能就要用到强大的Selection和Range对象了,可以解决我们开发中很多常见的问题。下面就简介下Selection 和 Range对象:
借用MDN上的解释:Selection对象表示用户选择的文本范围或插入符号的当前位置。它代表页面中的文本选区,可能横跨多个元素。文本选区由用户拖拽鼠标经过文字而产生。要获取用户检查或修改的Selection对象,请调用window.getSelection()。
Range则是每个具体的选区,对于富文本的复制文本格式过滤,我们主要就是借助Range对象中某些具体的属性和方法,从而来操作选区内容,具体实现代码如下:
1 document.addEventListener(‘paste‘, e => { 2 // 阻止默认的复制事件 3 e.preventDefault() 4 let txt = ‘‘ 5 let range = null 6 // 获取复制的文本 7 txt = e.clipboardData.getData(‘text/plain‘) 8 // 获取页面文本选区 9 range = window.getSelection().getRangeAt(0) 10 // 删除默认选中文本 11 range.deleteContents() 12 // 创建一个文本节点,用于替换选区文本 13 let pasteTxt = document.createTextNode(txt) 14 // 插入文本节点 15 range.insertNode(pasteTxt) 16 // 将焦点移动到复制文本结尾 17 range.collapse(false) 18 })
以上是关于python怎么定位富文框textarea的元素?我用xpath定位包找不到元素的主要内容,如果未能解决你的问题,请参考以下文章