极客时间的下载文件在哪里
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极客时间的下载文件在哪里相关的知识,希望对你有一定的参考价值。
已有极客时间账号,并可以正常访问专栏文章(即已经购买专栏),如没有专栏购买,麻烦三连,文末可分享我已有的下载文章(为了更好的阅读体验,还请支持正版)。随便打开已有的一篇专栏文章
1 打开chrome的开发者工具,选择网络->XHR,按ctrl+R进行网络请求记录(点击某一个请求,鼠标右键保存为har)
2 在XHR的网络请求记录中,有一个articles的post请求,获取了所有专栏文章的摘要信息,所以需要解析该post请求的响应参数,获取到该专栏的所有文章的id,方便后面拼接url地址
#数据收集整理,解析har中的请求
#
import json
def har_file_prase(filename):
with open(filename,'r',encoding='utf-8') as f:
har_logs = json.loads(f.read())
# 获取har中的entries
all_entries = har_logs['log']['entries']
# 当request 的url为该值时,返回所有文章的信息
all_articles_url = "https://time.geekbang.org/serv/v1/column/articles"
#find 对应的url的response
all_articles_resp = None
for x in all_entries:
if x[ 'request']['url'] == all_articles_url:
all_articles_resp = x['response']
break
assert all_articles_resp != None
content_text = all_articles_resp['content']['text']
content = json.loads(content_text)
response_list = content['data']['list']
# 返回所有id 拼接的url地址列表
return list(map(lambda x: "https://time.geekbang.org/column/article/" + str(x['id']), response_list))
import os
#获取当前目录下所有的.har文件
har_filelist = [x for x in os.listdir() if x.endswith('.har')]
#获取所有.har文件中的url,list
all_url_list = list(map(har_file_prase,har_filelist))
# all_url_list
#har_filelist
#har_filelist = [x for x in os.listdir() if x.endswith('.har')]
# 初始环境准备, (chrome 驱动,以及singleFile插件,同时还需要手动操作,登录个人的账号 )
# 通过selenium,访问对应的url地址,
# 然后,点击chrome 插件,singleFile,将文件保存到本地
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://time.geekbang.org/column/article/14256")
# 先启动chrome,同时最大化,驱动窗口,然后,安装插件,以及登录账号
# test 继续看登录是否成功
driver.get("https://time.geekbang.org/column/article/14256")
国内网安装,chrome插件
访问网址:https://www.chromefor.com/
可以搜索到几乎各种chrome的插件,然后点击下载,下载到本地之后,将之前的.crx文件copy到一个新的文件夹,并重命名为.zip后缀,然后解压到当前文件夹。
打开 chrome 开发者模式,可以选择加载已解压插件,然后点选到直接的新的文件夹,即可安装插件
# 使用 pyautogui 自动点击按钮进行下载
import time
import pyautogui
# 正式开始下载前需要调试,找准自己的电脑屏幕上对应的singlefile的按钮在那个位置
pyautogui.position() # 我电脑实际位置在(1797,51)
Point(x=1827, y=62)
# 下面正式开始下载
for i, url_list in enumerate(all_url_list):
for j, url in enumerate(url_list):
if i == 0 and j == 0:
time.sleep(5)
#第一次启动,需要手动将鼠标点击到chrome 驱动控制的窗口,
else:
time.sleep(1)#暂停一秒
driver.get(url)
time.sleep(10)#等待页面加载完
pyautogui.click(543,127, button='left')#需要点击收起左边的目录栏
time.sleep(2)#等待收起
pyautogui.click(1797,51, button='left')# 点击下载
print("save the url : ".format(i,url))
time.sleep(5)#等待保存完成 参考技术A 通常是你指定的地方吧,如果下载前没有指定那应该是在默认的文件夹里面,到quicktime的安装文件夹里面找一下呗
极客时间资料下载,满满干货指导
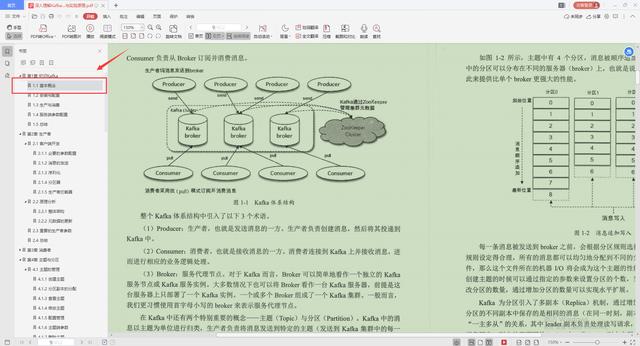
一、对Kafka的认识
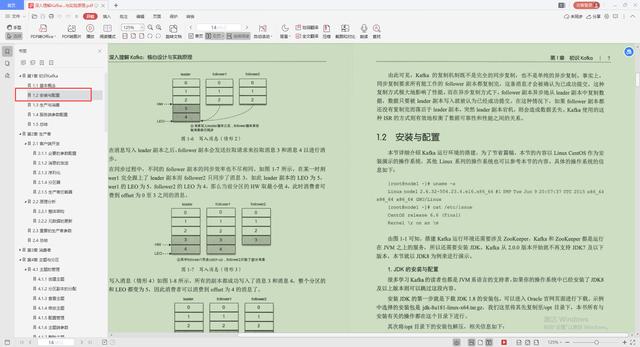
1.Kafka的基本概念
2.安装与配置
3.生产与消费
4.服务端参数配置
二、生产者
1.客户端开发
2.原理分析
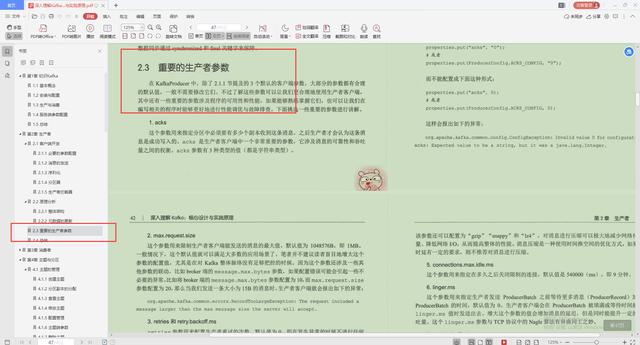
3.重要的生产者参数
三、消费者
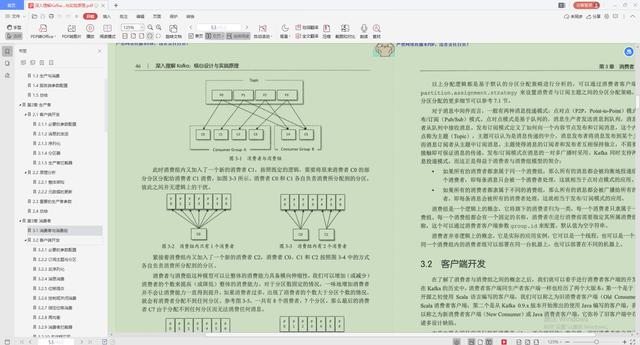
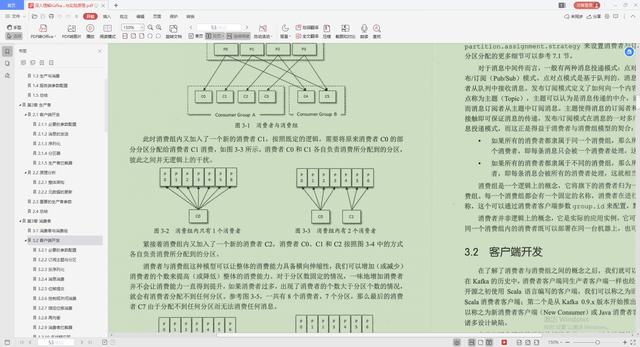
1.消费者与消费组
2.客户端开发

四、主题与分区
1.主题的管理
2.初识KafkaAdminCilent
3.分区的管理
4.如何选择合适的分区数

五、日志存储
1.文件目录布局
2.日志格式的演变
3.日志索引
4.日志清理
5.磁盘存储

六、深入服务端
1.协议设计
2.时间轮
3.延时操作
4.控制器
5.参数解密

七、深入客户端
1.分区分配策略
2.消费者协调器和组协调器
3._consumer_offsets剖析
4.事务

八、可靠性探究
1.副本剖析
2.日志同步机制
3.可靠性分析


九、Kafka应用
1.命令行工具
2.Kafka Connect
3.Kafka Mirror Maker
4.Kafka Streams

十、Kafka监控
1.监控数据的来源
2.消费滞后
3.同步失效分区
4.监控指标说明
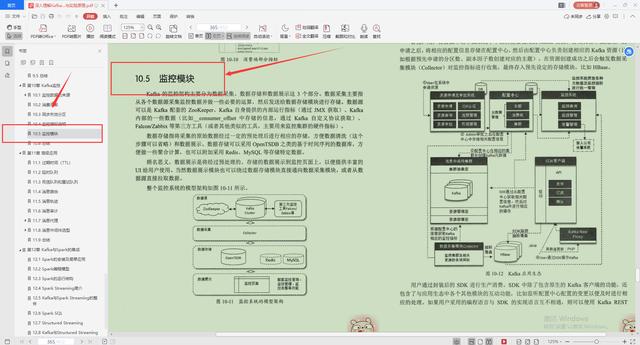
5.监控模块

十一、高级应用
1.过期时间(TTL)
2.延时队列
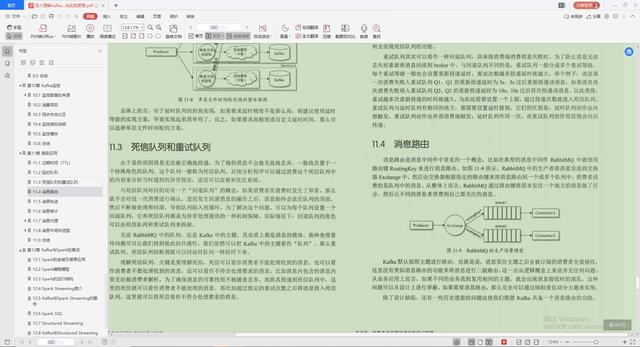
3.死信队列和重试队列
4.消息路由
5.消息轨迹
6.消息审计
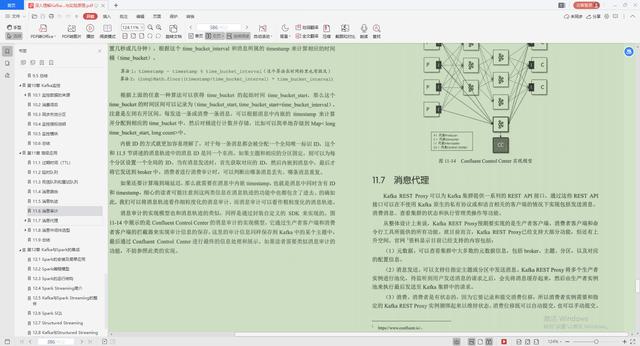
7.消息代理
8.消息中间件选型

十二、Kafka与Spark的集成
1.Spark的安装及简单应用
2.Spark编程模型
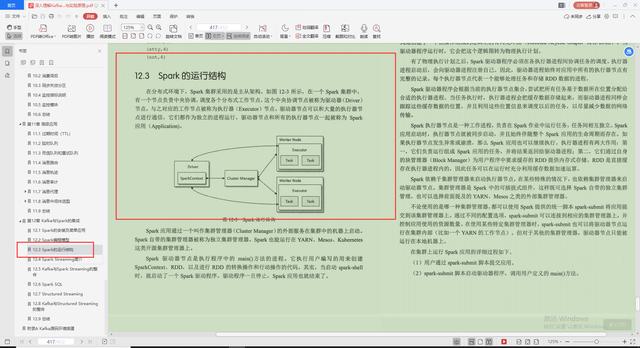
3.Spark的运行结构
4.Spark Streaming简介
5.Kafka与Spark Streaming的整合
6.Spark SQL
7.Structured Streaming
8.Kafka与Structured Streaming的整合

最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
下面的面试题答案都整理成文档笔记。也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图),有需要的可以戳这里免费领取
最新整理电子书
试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
下面的面试题答案都整理成文档笔记。也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图),有需要的可以戳这里免费领取
[外链图片转存中…(img-c04sQWX4-1626946112989)]
最新整理电子书
以上是关于极客时间的下载文件在哪里的主要内容,如果未能解决你的问题,请参考以下文章