Thinking in Java:容器深入研究
Posted Chouney
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Thinking in Java:容器深入研究相关的知识,希望对你有一定的参考价值。
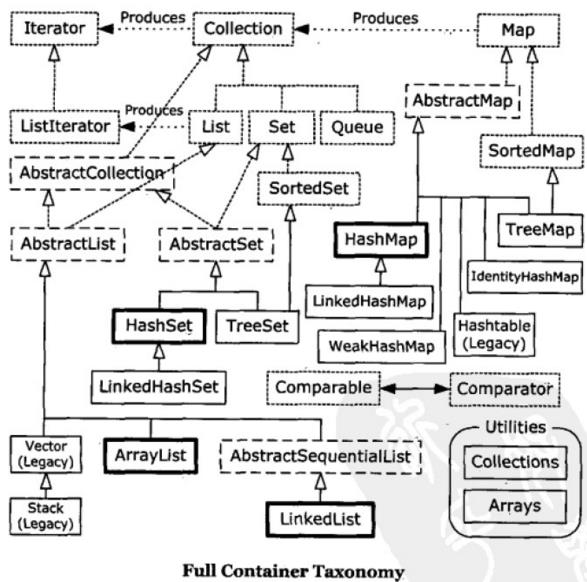
1.虚线框表示Abstract类,图中大量的类的名字都是以Abstract开头的,它们只是部分实现了特定接口的工具,因此创建时可以选择从Abstract继承。
Collections中的实用方法:挑几个常用的:
1. reverse(List):逆转次序
2. rotate(List,int distance)所有元素向后移动distance个位置,将末尾元素循环到前面来(用了三次reverse)
3.sort(List,Comparator) 排序,可按照自己的Comparator
4.copy(List dest,List src) 复制元素(引用)
5.fill(List,T x)同Arrays一样,复制的是同一引用
6.disjoint(Collection,Collection) 两个集合没有任何元素时返回ture
7.frequency(Collection, Object x)返回Collection中等于x的元素个数
8.binarySearch()折半查找(要求有序)
Collection的功能方法:
boolean add(T) 可选方法,若没将参数添加进容器,则false
boolean addAll(Collection )可选方法,只要添加了任意元素就true
void clear() 可选方法
boolean contains(T) 若容器中已经持有具有泛型T参数,true
Boolean containsAll(Collection )
boolean isEmpty()
Iterator iterator()
Boolean remove(Object) 可选方法
boolean removeAll(Collection) 可选方法
Boolean retainAll(Collection) 容器交集,可选方法
int size()
Object[] toArray()
T[] toArray(T[] a)返回包含容器中所有元素的数组
PS:这里不包括随机访问所选择元素的get()方法,因为Collection包括Set,而Set是自己维护内部顺序的(这使得随机访问变得没有意义)
2上述执行各种不同的添加和移出的方法在Collection接口中都是可选操作,意味着实现类并不需要为这些方法提供功能定义
未获得支持的操作
1.Arrays.asList()会生成一个List,它基于一个固定大小的数组,仅支持哪些不会改变数组大小的操作,任何会引起对底层数据结构的尺寸进行修改的方法都会产生一个UnsupportedOperationException异常(这里Arrays.asList返回的是List的代理类)。若想生成循序使用所有的方法的普通容器,可以将其作为参数传入到新的容器中(如addAll,或构造器等)
2Collections类中的“不可修改”方法(unmodified*方法)将容器包装到了一个代理中,该代理类不支持任何试图修改容器的操作
Set和存储顺序:
1:Set(interface):加入Set的元素必须定义equals()方法以确保对象的唯一性,Set接口不保证维护元素的次序
2:HashSet:存入HashSet的元素必须定义hashCode()
3:TreeSet:保证有序,元素必须实现Comparable接口
4:LinkedHashSet 具有HashSet的查询速度,且内部使用链表维护元素的顺序,元素必须定义hashCode()
虽然hashCode不是必须实现的,但是对于良好的编程风格而言,应该在覆盖equals方法时,总是同时覆盖hashCode()方法。
3.如果一个对象被用于任何种类的排序容器中,如SortedSet(TreeSet是其唯一实现),则其必须实现Comparable接口
PS:在接口的实现方法compareTo()中,不应该使用return i-i2这样的形式,错误编程,因为这样没有考虑到i-i2数值溢出的问题,应该
return (arg.i < i ? -1 : (arg.i == i ? 0 : 1))
4若在HashSet容器中元素并没有重新定义hashCode(),将它们放置到任何散列实现中都可能会产生重复值,这甚至不会产生运行时错误。唯一的可靠方法就是写单测。
5.SortedSet的意思为“按照对象的比较函数对元素排序”,而不是“元素插入的次序”。
6.优先级队列,其元素排序顺序也是通过实现Comparable而进行控制的。
理解Map:
1:HashMap : 基于散列表的实现。可以通过构造器设置容量和负载因子调整容器性能。
2:LinkedHashMap :与HashMap却别在于迭代遍历时,取得键值对顺序是插入次序,或是LRU次序。除了迭代访问时其余性能要慢一点
3:TreeMap:基于红黑树的实现。查看“键”或者“键值对”的时候,它们会被排序(按照Comparable方法),其唯一的带有subMap()方法的Map,可以返回一个子树。
4:WeakHashMap:弱键映射,允许释放映射所指向的对象;如果映射之外没有引用指向某个“键”,则此键可以被垃圾收集器回收
5:IdentityHashMap:使用==代替equals()对”键“进行比较的散列映射
PS:任何键都必须具有一个equals方法,如果键被用于散列Map,则还必须有一个恰当的hashCode方法;若键被用于TreeMap,则它必须实现Comparable
7.map中可以直接打印values方法的结果,该方法会产生一个包含Map中所有值得Collection,由于这些Collection背后是由Map支持的,所以对Collection的任何改动都会反映到与之相关联的Map。
8.LinkedHashMap散列化所有的元素,但是在遍历键值对时,却又以元素的插入顺序返回键值对,此外,可以在构造器中设定LinkedHashMap,使之采用基于访问的LRU算法,于是没有被访问过的元素就会出现在队列的前面。对于需要定期清理元素以节省空间的程序来说,此功能使得程序很容易得以实现。
散列与散列码:
1.Object的hashCode()方法生成散列码,而它默认是使用对象的地址计算散列码。
2.可能你会认为,只需编写恰当的hashCode()方法的覆盖版本即可。但是它仍然无法正常运行,除非你同时覆盖equals()方法,他也是Object的一部分。HashMap使用equals()判断当前的键是否与表中存在的键相同。
PS:正确的equals()方法必须满足下列5个条件:
1)自反性:x.equals(x)一定返回true
2)对称性:x.equals(y)返回true当且仅当y.equals(x)
3)传递性:x.equals(y)且y.equals(z),则x.equals(z)为true
4)一致性:若x.equals(y)返回true,则不改变x,y时多次调用x.equals(y)都返回true
5)对于任意的非空引用值x,x.equals(null)一定返回false。
为了速度而散列:
1.由于瓶颈位于键的查询速度,因此解决方案之一就是保持键的排序状态,然后使用Collections。binarySearch()进行查询
2.散列则更进一步,它将键保存在某处,以便能够很快找到。存储一组元素最快的数据结构是数组,所以使用它来表示键的信息。信息就是散列码。
3.通常,冲突由外部链接处理,数组并直接保存至,而是保存值得list,然后对list中的值使用equals方法进行线性查询。
4.进来,Java的散列函数都使用2的整数次方。对现代的处理器来说,除法与求余数是最慢的操作。使用2的整数次方长度的散列表,可用掩码代替除法。因为get是使用最多的操作,求余数的%操作是其开销最大的部分,而是用2的整数次方可以消除此开销。
9.设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该生成同样的值。若你的hashCode()方法依赖于对象中易变的数据,用户就要当心了。同时,也不应该使hashCode()依赖于具有唯一性的对象信息,尤其是使用this的值,这只能产生很糟糕的hashCode()因为这样无法生成一个新的键使之与put中原始的键值对中的键相同。
10.要想使hashCode使用,他必须速度快,并且有意义,也就是说,他必须基于对象的内容生成散列码。散列码不必是独一无二的,但是通过hashCode()和equals,必须能够完全确定对象的身份。
性能:
1.应该避免使用Vector(能正常工作的唯一原因,只是为了向前兼容,被适配成了List)
2TreeSet迭代通常比用HashSet要快;另外,对于插入操作,LinkedHashSet比HashSet代价更高,这是由维护链表所带来额外的开销造成的
3.Hashtable的性能大体上与HashMap相当。因为HashMap是用来替代Hashtable的。因此它们使用了相同的底层存储和查找机制。
4.IdentityHashMap则具有完全不同的性能,因为它使用==而不是equals来比较元素。
HashMap的性能因子:
容量:表中桶位数(slot)
初始容量:表在创建时所拥有的桶位数。HashMap和HashSet都具有允许你只能初始容量的构造器。
尺寸:表中当前存储的项数。
负载因子:尺寸/容量。HashMap和HashSet都具有允许你指定负载因子的构造器,表示负载情况达到该负载因子的水平时,容器将自动添加其容量(桶位数),实现方式是使容量大致加倍,并重新将现有对象分布到新的桶位数集中(这被称为再散列)
Collection或Map的同步控制:
1.Collections类有办法能够自动同步整个容器。其语法与“unmodified*”类似。
List a = Collections.synchronizedList(new ArrayList(data));
最好如上所示,是直接将新生成的容器传递给了适当的“同步”方法,这样做就不会有任何机会会暴漏出不同步的版本。
快速报错:
Java容器有一种保护机制,能够防止多个进程同时修改同一个容器的内容。Java容器类类库采用快速报错(fail fast)机制。它会探查容器上的任何除了你的进程所进行的操作以外的所有变化,一旦发现其他进程改变了容器,就会立刻抛出ConcurrentModificationException异常。如:在容器取得迭代器之后,又有东西呗放入到了该容器中
ConcurrentHashMap,CopyOnWriteArrayList、CopyOnWriteArraySet都使用了可以避免ConcurrentModificationException的技术
持有引用:
1.java.lang.ref类库包含一组类,当存在可能会耗尽内存的大对象的时候,这些类显得特别有用。有SoftReference、WeakReference、PhantomReference。当垃圾回收期正在考察的对象只能通过某个Reference对象才“可获得时”,上述这些不同的派生类为垃圾回收器提供了不同级别的间接性指示
2.如果想继续持有对某个对象的引用,希望以后还能够访问到该对象,但是也希望能够允许垃圾回收器释放它,这时就应该使用Reference对象。这样,你可以继续使用对象,而在内存消耗殆尽的时候又允许释放该对象。
3.以Reference对象作为你和普通引用之间的媒介(代理),另外一定不能有普通的引用指向那个对象,这样就能达到上述目的
4.对于SoftReference、WeakReference、PhantomReference三个引用的区别和功能,详见JVM.
5.使用SoftReference、WeakReference时,可以选择是否要将它们放入ReferenceQueue(用作“回收前清理工作”的工具,见JVM)。而PhantomReference只能依赖于ReferenceQueue。
6.WeakHashMap:见JVM,它被用来保存WeakReference。这该映射中,每个值只保存一份实例以节省存储空间,且WeakHashMap允许垃圾回收器自动清理键和值,所以它显得十分便利。
Java 1.0/1.1容器(了解):
1.Enmuberation:老版本的迭代器,其接口比Iterator小,但是无论如何代码中应该尽量使用Iterator。可以通过使用Collections.enumeration()方法来从Collection生成一个Enumeration
2.Hashtable:如前所说,基本的Hashtable与HashMap很相似。尽量使用HashMap(多线程同步时仍然有很多其他的选择)
3.BisSet:如果想要高效率地存储大量“开/关”信息,BitSet是很好的选择。不过它的效率仅是对空间而言;如果需要高效访问时间,BitSet比本地数组稍慢一些,BitSet最小容量是Long:64位,若存储的内容比较小,如8位,则BitSet浪费了一些空间。BitSet也会想普通容器一样随着元素的加入而扩充其容量。总的来说,若拥有一个可以命名的标志集合,那么EnumSet通常是一种更好的选择,因为EnumSet允许你按照名字而不是数字位的位置进行操作,因此可以减少错误。
以上是关于Thinking in Java:容器深入研究的主要内容,如果未能解决你的问题,请参考以下文章