mysqldump的实现原理
Posted 长城之上是千亿的星空,星空之上是不灭的守望。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysqldump的实现原理相关的知识,希望对你有一定的参考价值。
我们可以通过打开general log,查看mysqldump全库备份时执行的命令来了解mysqldump背后的原理。
打开general log
mysql> set global general_log=on;
其中,general log的存放路径可通过以下命令查看
mysql> show variables like \'%general_log_file%\';
执行全库备份
# mysqldump --master-data=2 -R --single-transaction -A -phello > 3306_20160518.sql
其中
--master-data指定为2指的是会在备份文件中生成CHANGE MASTER的注释。具体在本例中,指的是
-- CHANGE MASTER TO MASTER_LOG_FILE=\'mysql2-bin.000049\', MASTER_LOG_POS=587;
如果该值设置为1,则生成的是CHANGE MASTER的命令,而不是注释。
-R 备份存储过程与函数
--single-transaction 获取InnoDB表的一致性备份。
-A 相当于--all-databases。
下面来看看general log中的内容

160518 11:00:59 14 Connect root@localhost on
14 Query /*!40100 SET @@SQL_MODE=\'\' */
14 Query /*!40103 SET TIME_ZONE=\'+00:00\' */
14 Query FLUSH /*!40101 LOCAL */ TABLES
14 Query FLUSH TABLES WITH READ LOCK
14 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
14 Query START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */
14 Query SHOW VARIABLES LIKE \'gtid\\_mode\'
14 Query SHOW MASTER STATUS
14 Query UNLOCK TABLES
14 Query SELECT LOGFILE_GROUP_NAME, FILE_NAME, TOTAL_EXTENTS, INITIAL_SIZE, ENGINE, EXTRA FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = \'UNDO LOG\' AND FILE_NAME IS NOT NULL GROUP BY LOGFILE_GROUP_NAME, FILE_NAME, ENGINE ORDER BY LOGFILE_GROUP_NAME
14 Query SELECT DISTINCT TABLESPACE_NAME, FILE_NAME, LOGFILE_GROUP_NAME, EXTENT_SIZE, INITIAL_SIZE, ENGINE FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = \'DATAFILE\' ORDER BY TABLESPACE_NAME, LOGFILE_GROUP_NAME
14 Query SHOW DATABASES
14 Query SHOW VARIABLES LIKE \'ndbinfo\\_version\'
其中,比较重要的有以下几点:
1. FLUSH /*!40101 LOCAL */ TABLES
Closes all open tables, forces all tables in use to be closed, and flushes the query cache.
2. FLUSH TABLES WITH READ LOCK
执行flush tables操作,并加一个全局读锁,很多童鞋可能会好奇,这两个命令貌似是重复的,为什么不在第一次执行flush tables操作的时候加上锁呢?
下面看看源码中的解释:
/*
We do first a FLUSH TABLES. If a long update is running, the FLUSH TABLES
will wait but will not stall the whole mysqld, and when the long update is
done the FLUSH TABLES WITH READ LOCK will start and succeed quickly. So,
FLUSH TABLES is to lower the probability of a stage where both mysqldump
and most client connections are stalled. Of course, if a second long
update starts between the two FLUSHes, we have that bad stall.
*/
简而言之,是为了避免较长的事务操作造成FLUSH TABLES WITH READ LOCK操作迟迟得不到锁,但同时又阻塞了其它客户端操作。
3. SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
设置当前会话的事务隔离等级为RR,RR可避免不可重复读和幻读。
4. START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */
获取当前数据库的快照,这个是由mysqldump中--single-transaction决定的。
这个只适用于支持事务的表,在MySQL中,只有Innodb。
注意:START TRANSACTION和START TRANSACTION WITH CONSISTENT SNAPSHOT并不一样,
START TRANSACTION WITH CONSISTENT SNAPSHOT是开启事务的一致性快照。
下面看看官方的说法,
The WITH CONSISTENT SNAPSHOT modifier starts a consistent read for storage engines that are capable of it. This applies only to InnoDB. The effect is the same as issuing a START TRANSACTION followed by a SELECT from any InnoDB table.
如何理解呢?
简而言之,就是开启事务并对所有表执行了一次SELECT操作,这样可保证备份时,在任意时间点执行select * from table得到的数据和执行START TRANSACTION WITH CONSISTENT SNAPSHOT时的数据一致。
注意,WITH CONSISTENT SNAPSHOT只在RR隔离级别下有效。
下面通过实例看看START TRANSACTION WITH CONSISTENT SNAPSHOT和START TRANSACTION的不同
注意:session 2是自动提交
START TRANSACTION WITH CONSISTENT SNAPSHOT

START TRANSACTION

可见,如果仅是START TRANSACTION,事务2的insert操作提交后,session 1可见(注意,可见的前提是session 2的insert操作在session 1的select操作之前)
而如果是START TRANSACTION WITH CONSISTENT SNAPSHOT,则即便session 2的insert操作在session 1的select操作之前,对session 1均不可见。
5. SHOW MASTER STATUS
这个是由--master-data决定的,记录了开始备份时,binlog的状态信息,包括MASTER_LOG_FILE和MASTER_LOG_POS
6. UNLOCK TABLES
释放锁。
因为我的数据库中只有以下四个库
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | +--------------------+ 4 rows in set (0.03 sec)
备份的时候可以发现只备份了mysql和test,并没有备份information_schema和performance_schema。
下面来看看备份mysql和test的日志输出信息,
因日志输出信息太多,在这里,只选择test库的日志信息。test库中一共有两张表test和test1。
14 Init DB test
14 Query SHOW CREATE DATABASE IF NOT EXISTS `test`
14 Query SAVEPOINT sp
14 Query show tables
14 Query show table status like \'test\'
14 Query SET SQL_QUOTE_SHOW_CREATE=1
14 Query SET SESSION character_set_results = \'binary\'
14 Query show create table `test`
14 Query SET SESSION character_set_results = \'utf8\'
14 Query show fields from `test`
14 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `test`
14 Query SET SESSION character_set_results = \'binary\'
14 Query use `test`
14 Query select @@collation_database
14 Query SHOW TRIGGERS LIKE \'test\'
14 Query SET SESSION character_set_results = \'utf8\'
14 Query ROLLBACK TO SAVEPOINT sp
14 Query show table status like \'test1\'
14 Query SET SQL_QUOTE_SHOW_CREATE=1
14 Query SET SESSION character_set_results = \'binary\'
14 Query show create table `test1`
14 Query SET SESSION character_set_results = \'utf8\'
14 Query show fields from `test1`
14 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `test1`
14 Query SET SESSION character_set_results = \'binary\'
14 Query use `test`
14 Query select @@collation_database
14 Query SHOW TRIGGERS LIKE \'test1\'
14 Query SET SESSION character_set_results = \'utf8\'
14 Query ROLLBACK TO SAVEPOINT sp
14 Query RELEASE SAVEPOINT sp
14 Query use `test`
14 Query select @@collation_database
14 Query SET SESSION character_set_results = \'binary\'
14 Query SHOW FUNCTION STATUS WHERE Db = \'test\'
14 Query SHOW CREATE FUNCTION `mycat_seq_currval`
14 Query SHOW PROCEDURE STATUS WHERE Db = \'test\'
14 Query SET SESSION character_set_results = \'utf8\'
14 Quit
从上述输出可以看出:
1. 备份的核心是SELECT /*!40001 SQL_NO_CACHE */ * FROM `test1`语句。
该语句会查询到表test1的所有数据,在备份文件中会生成相应的insert语句。
其中SQL_NO_CACHE的作用是查询的结果并不会缓存到查询缓存中。
2. SHOW CREATE DATABASE IF NOT EXISTS `test`,show create table `test1`
生成创库语句和创表语句。
3. SHOW TRIGGERS LIKE \'test1\'
可以看出,如果不加-R参数,默认是会备份触发器的。
4. SHOW FUNCTION STATUS WHERE Db = \'test\'
SHOW CREATE FUNCTION `mycat_seq_currval`
SHOW PROCEDURE STATUS WHERE Db = \'test\'
用于备份存储过程和函数。
5. 设置SAVEPOINT,然后备份完每个表后再回滚到该SAVEPOINT。
为什么要这么做呢?
前面通过START TRANSACTION WITH CONSISTENT SNAPSHOT开启的事务只能通过commit或者rollback来结束,而不是ROLLBACK TO SAVEPOINT sp。
其实,这样做不会阻塞在备份期间对已经备份表的ddl操作。
/**
ROLLBACK TO SAVEPOINT in --single-transaction mode to release metadata
lock on table which was already dumped. This allows to avoid blocking
concurrent DDL on this table without sacrificing correctness, as we
won\'t access table second time and dumps created by --single-transaction
mode have validity point at the start of transaction anyway.
Note that this doesn\'t make --single-transaction mode with concurrent
DDL safe in general case. It just improves situation for people for whom
it might be working.
*/
下面具体来测试一下:
第一种情况:
会话1发起事务,并查询test表的值,然后会话2进行添加列操作,该操作被hang住。

第二种情况:
会话1发起事务,然后会话2进行添加列操作,发现该操作成功。

第三种情况:
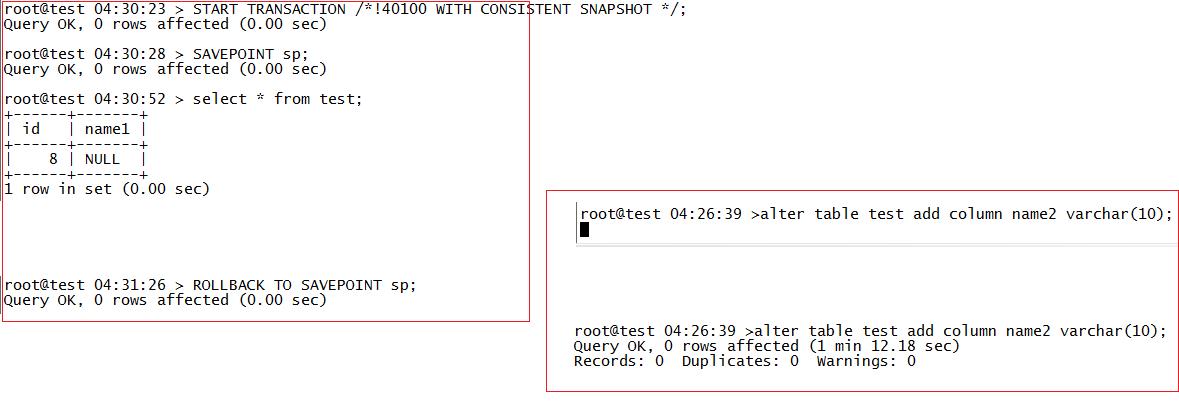
模仿mysqldump的备份原理,设置断点。
注意,DDL操作发起的时间是在执行了select * from test之后,如果是在之前,根据上面第二种情况的测试,是可以进行DDL操作的。
此时,如果不执行ROLLBACK TO SAVEPOINT sp,DDL操作会一直hang下去,执行了该操作后,DDL操作可以继续执行了。
由此可见,ROLLBACK TO SAVEPOINT确实可以提高DDL的并发性。
但还有一点需要注意,如果DDL操作是发生在select * from test之前,正如第二种情况所演示的,DDL操作会成功,此时,查看test表的数据会报以下错误:
root@test 04:32:49 > select * from test; ERROR 1412 (HY000): Table definition has changed, please retry transaction
对应mysqldump,会报如下错误:
mysqldump: Error 1412: Table definition has changed, please retry transaction when dumping table `test` at row: 0
总结:
1. mysqldump的本质是通过select * from tab来获取表的数据的。
2. START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */必须放到FLUSH TABLES WITH READ LOCK和UNLOCK TABLES之间,放到之前会造成START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */和FLUSH TABLES WITH READ LOCK之间执行的DML语句丢失,放到之后,会造成从库重复插入数据。
3. mysqldump只适合放到业务低峰期做,如果备份的过程中数据操作很频繁,会造成Undo表空间越来越大,undo表空间默认是放到共享表空间中的,而ibdata的特性是一旦增大,就不会收缩。
4. mysqldump的效率还是比较低下,START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */只能等到所有表备份完后才结束,其实效率比较高的做法是备份完一张表就提交一次,这样可尽快释放Undo表空间快照占用的空间。但这样做,就无法实现对所有表的一致性备份。
5. 为什么备份完成后没有commit操作
/*
No reason to explicitely COMMIT the transaction, neither to explicitely
UNLOCK TABLES: these will be automatically be done by the server when we
disconnect now. Saves some code here, some network trips, adds nothing to
server.
*/
参考:
http://tencentdba.com/blog/mysqldump-backup-principle/
以上是关于mysqldump的实现原理的主要内容,如果未能解决你的问题,请参考以下文章
mysql mysqldump只导出表结构或只导出数据的实现方法