Hadoop学习------Hadoop安装方式之:单机部署
Posted 风行__雄关漫道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习------Hadoop安装方式之:单机部署相关的知识,希望对你有一定的参考价值。
Hadoop 默认模式为单机(非分布式模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
1、创建用户
1.1创建hadoop用户组和用户
一般我们不会经常使用root用户运行hadoop,所以需要创建一个平常运行和管理hadoop的用户;
有2种方式,选择任意一种即可
方法1:先创建hadoop用户组 (不同Linux系统命令不同)
sudo groupadd(或者addgroup) hadoop
再创建hadoop用户
sudo useradd(或者 adduser) –g hadoop hadoop
前一个hadoop是用户组,后一个hadoop是用户
修改 hadoop用户的密码
passwd hadoop
方法2:先创建hadoop 用户
sudo useradd(或者 adduser)
passwd hadoop
在创建hadoop用户的同时也创建了hadoop用户组,下面我们把hadoop用户加入到hadoop用户组输入
sudo usermod -a -G hadoop hadoop
1.2给hadoop用户赋予root权限
vi /etc/sudoers
在文件中找到一行文字如下:
# User privilege specification
root ALL=(ALL) ALL
在root下面加上一行
hadoop ALL=(ALL) ALL
然后 保存退出,这样hadoop用户就有了root权限。
2 安装JDK并配置好环境变量
这里不再过多说明,详情见 Linux系统上安装、卸载JAVA、TOMCAT的方法
3 修改机器名
进入/etc/sysconfig/network (ubuntu系统修要修改/etc/hostname)
vi /etc/sysconfig/network 修改主机名为master

4.安装SSH 服务,建立SSH无密码登录本机
4.1 如果本机没有安装SSH
sudo apt-get install ssh
4.2设置本机无密码登录
具体步骤如下:
第一步:产生密钥
$ ssh-keygen -t dsa -P \'\' -f ~/.ssh/id_dsa
第二部:导入authorized_keys
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第二部导入的目的是为了无密码等,这样输入如下命令:
ssh localhost 无需密码直接进入

5安装Hadoop
5.1从官网下载Hadoop最新版2.7.0
进入到 /usr/loca cd /usr/local
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
然后解压缩 tar zxvf /root/hadoop-2.7.0.tar.gz
然后将解压后的文件重命名为hadoop mv hadoop-2.7.0 hadoop
5.2设置环境变量
vi /etc/profile
找到PATH 在最后面添加 :/usr/local/hadoop/bin 或者
export PATH=/usr/local/hadoop-2.7.0/bin:$PATH
使配置生效 source /etc/profile
设置Hadoop的JAVA_HOME
cd /usr/local/hadoop
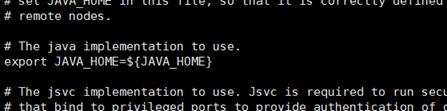
vi etc/hadoop/hadoop-env.sh
找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径
5.3测试是否安装成功 单机模式
cd /usr/local/hadoop
./bin/hadoop version 可以查看hadoop版本信息

现在我们可以执行一些例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoo/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input 创建目录
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output \'dfs[a-z.]+\'
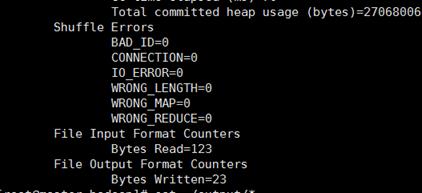
然后我们可以查看运行结果 cat ./output/*
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次

注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。 rm -r ./output
cd /usr/local/hadoop jps
执行 hadoop fs –ls
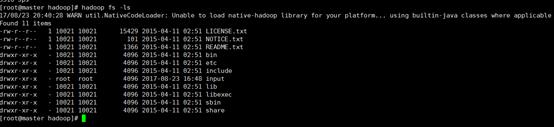
至此 单机模式已经部署完成。
以上是关于Hadoop学习------Hadoop安装方式之:单机部署的主要内容,如果未能解决你的问题,请参考以下文章