机器学习之大数据集
Posted steed
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之大数据集相关的知识,希望对你有一定的参考价值。
前言
以下内容是个人学习之后的感悟,转载请注明出处~
简介
大数据时代已经来临,它将在众多领域掀起变革的巨浪。机器学习对于大数据集的处理也变得越来越重要。大数据
集务必会带来恐怖的计算量,不仅耗费大量资源,而且给数据处理的实时性带来巨大的挑战。
想要解决这个难题,就需要采取以下措施:选择更加适合大数据集的算法、更加好的硬件,采用并行计算等。
本文内容较多,建立以下目录,方便浏览:
- 批量梯度下降法
- 随机梯度下降法
- 微型批量梯度下降法
- 判断收敛
- 选择学习速率α
- 在线学习
- map readuce
批量梯度下降法
以线性回归为例,如果m很大,每次循环都得进行m次求和,计算量非常大,不建议。

随机梯度下降法
以线性回归为例,随机梯度下降法采用单次代价函数cost,每次迭代θ,不需要执行那么多次加法,计算量小很多。
注意:样本需要随机打乱。
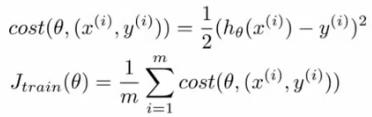

微型批量梯度下降法
以线性回归为例,设样本数量m=1000,小批量数b=10,即每次迭代只需10次叠加,计算量也很少。

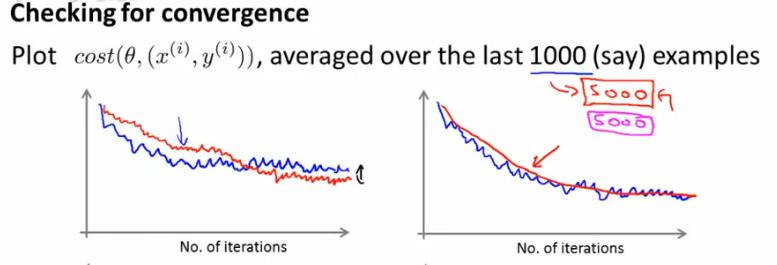
判断收敛
之前数据量很少的时候,我们都是直接判断代价函数J(θ),只要其不再减少则收敛。然后在数据量很大的情况下,如
果实时监控代价函数,必然带来巨大的计算量。其实,我们可以每隔1000次计算一下代价函数cost,将其画成曲线,取其
低谷处为收敛,若出现曲线趋势递增,则表明发散。(图中的细小起伏波纹是噪音导致)
选择学习速率α
我们选择随机梯度下降法来处理大数据,虽然可以达到减小计算量的效果,但是并不能准确地达到极值点,有些人为
了尽量逼近极值点,设置α=常数1/(迭代次数+常数2)。
虽然无法达到极值点,但是也相差不多,所以一般α取常数即可。
在线学习
很多情况下,数据是源源不断地传输过来,而且我们要时常更新一些信息,这时就需要使用在线学习。
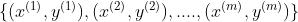 ,
,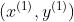 ,然后调整参数,接着再输入
,然后调整参数,接着再输入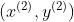 ,再调整参数,这样持续到最后一个样本。这样也就导致了在
,再调整参数,这样持续到最后一个样本。这样也就导致了在- 在线学习容易执行
- 对大规模和困难模式分类问题能提供有效解
map readuce
以批量梯度下降法为例,将m=400的数据集分为4部分,分别由4台电脑处理。如下图所示:
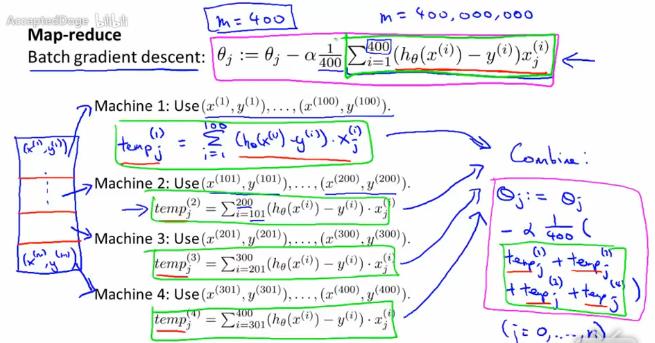
此外,你也可以用多核电脑进行并行计算。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~
以上是关于机器学习之大数据集的主要内容,如果未能解决你的问题,请参考以下文章