Sql Server中百万级数据的查询优化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sql Server中百万级数据的查询优化相关的知识,希望对你有一定的参考价值。
万级别的数据真的算不上什么大数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写方法有着千差万别的性能,都在这个级别中显现出来了,它不仅考核着你sql语句的性能,也考核着程序员的思想。
公司系统的一个查询界面最近非常慢,界面的响应时间在6-8秒钟时间,甚至更长。检查发现问题出现在数据库端,查询比较耗时。该界面涉及到多个表中的数据,基本表有150万数据,关联子表的最多的一个700多万数据,其它表数据也在几十万到几百万之间。其实按这样的数据级别查询响应时间应该在毫秒级内,不应该有这么长时间。那么接下来就该进行问题排查了。
由于这个这界面的功能主要是信息检索,查询比较复杂,太多的条件组合,使用存储过程太多的局限性,因此查询使用的是动态拼接的sql语句。查询方式是最常用的1、获取数据总数2、数据分页。直接上代码(部分条件)。
select numb=count(distinct t1.tlntcode) from ZWOMMAINM0 t1 inner join ZWOMMLIBM0 t2 on t1.tlntcode=t2.tlntcode join ZWOMEXPRM0 cp on t1.tlntcode=cp.tlntcode join ZWOMILBSM0 i on i.tlntcode=t1.tlntcode join ZWOMILBSM0 p on p.tlntcode=i.tlntcode join ZWOMILBSM0 l on l.tlntcode=i.tlntcode where isnull(t2.deletefg,‘0‘)=‘0‘ and cp.companyn like ‘%IBM%‘ and cp.sequence=0 and i. mlbscode in(‘i0100‘,‘i0101‘,‘i0102‘,‘i0103‘,‘i0104‘,‘i0105‘,‘i0106‘) and i.locatype=‘10‘ and p.mlbscode in(‘p0100‘,‘p0102‘,‘p0104‘,‘p0200‘,‘p0600‘) and p.locatype=‘10‘ and l.mlbscode in(‘l030‘) and l.locatype=‘10‘
查看执行时间

根据提示得知,整个查询耗时花费在了分析和编译为4秒,执行为0.7秒。查询语句没有发现什么问题,那么问题出现在了编译,如果让SQL语句执行原有的查询计划,那么跳过编译,只需0.7秒就能得到结果。那么如何做到预编译,或者使用现有的执行计划?
SQL Server有一优化算法,它保存了以往执行sql语句的执行计划,所有的执行计划都会在sys.syscacheobjects表中存储,如果当前sql语句在缓存表中能匹配到,那么它讲执行匹配到的执行计划,而不再进行编译。 那么解决方法我们首先想到的是存储过程(这就是我们面试或者理论中经常说的存储过程有预编译,平时也就是说说,不存在什么深刻印象),是的它能实现预编译,但是由于条件限制,查询太过复杂,如果把没有使用到查询条件的表都关联在一起反而影响到性能。排除存储过程,我们另外想到的就是
EXEC SP_EXECUTESQL @Sql, N‘@p NVARCHAR(50)‘,@p
为什么SP_EXECUTESQL 能复用查询计划而普通sql语句不能,我们从缓存表中查看就能发现问题
select bucketid,cacheobjtype,objtype,objid,sql,sqlbytes from sys.syscacheobjects where cacheobjtype=‘Compiled Plan‘
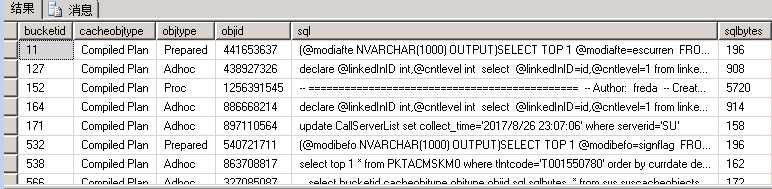
表中sql字段就是历史执行计划的查询语句,如果sql匹配成功那么就会执行匹配的执行计划。普通sql语句很难与之匹配,因为它不但包含了结构还包含了参数,复用率很低。而SP_EXECUTESQL 执行时只存储结构,参数不存储,因此复用率很高。找到了解决方法,那么直接行动。
declare @Sql nvarchar(max),@cpny nvarchar(50)=‘IBM‘
declare @i varchar(1000)=‘i0100,i0101,i0102,i0103,i0104,i0105,i0106,i0107,i0109‘, @p varchar(1000)=‘p0100,p0101,p0102,p0103,p0104,p0107,p0201‘,@l varchar(1000)=‘l030‘ set @Sql=‘select value into #i from f_CSplit(@i,‘‘,‘‘) select value into #p from f_CSplit(@p,‘‘,‘‘) select value into #l from f_CSplit(@l,‘‘,‘‘) select numb=count(distinct t1.tlntcode) from ZWOMMAINM0 t1 inner join ZWOMMLIBM0 t2 on t1.tlntcode=t2.tlntcode join ZWOMILBSM0 i on i.tlntcode=t1.tlntcode join ZWOMILBSM0 p on p.tlntcode=t1.tlntcode join ZWOMILBSM0 l on l.tlntcode=t1.tlntcode join ZWOMEXPRM0 cp on t1.tlntcode=cp.tlntcode where isnull(t2.deletefg,‘‘0‘‘)=‘‘0‘‘ and i.mlbscode in(select value from #i) and i.locatype=‘‘10‘‘ -- and i.mlbstype=‘‘20‘‘ and p.mlbscode in(select value from #p) and p.locatype=‘‘10‘‘ --and p.mlbstype=‘‘40‘‘ and l.mlbscode in(select value from #l) and l.locatype=‘‘10‘‘-- and l.mlbstype=‘‘50‘‘ and cp.companyn like ‘‘%‘‘[email protected]+‘‘%‘‘ and cp.sequence=0 ‘ EXEC SP_EXECUTESQL @Sql, N‘@cpny NVARCHAR(50),@i NVARCHAR(50),@p NVARCHAR(50),@l NVARCHAR(50)‘, @cpny,@i,@p,@l

总耗时0.5秒,无论参数如何改变基本都在0.5秒波动,基本符合了我们的要求,如果想进一步优化还可以进行表分区等其他优化方案。
当我们发现查询速度慢时,有可能是分析和编译占用了你的太多时间,因此简化你的查询语句、复用执行计划能帮你走出困境。
以上是关于Sql Server中百万级数据的查询优化的主要内容,如果未能解决你的问题,请参考以下文章