Memcache讲解
Posted 培训机构笔记整理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Memcache讲解相关的知识,希望对你有一定的参考价值。
一.大型网站的优化方向
1.PHP+MySql的存储缺点
在大部分的php的网站开发当中,我们往往采用的数据存储方式是php+mysql,因此就会产生如下图所示的请求方式:
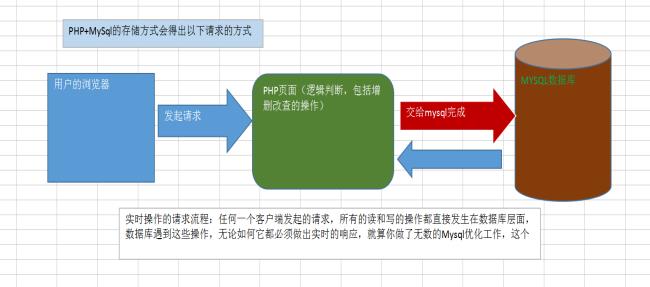
以上的架构对一般对于访问量不大的网站没有任何问题,例如:个人博客网站,小公司的企业网站。然而当网站的数据量和访问量增大之后,即使您的MySql数据库做了非常完美的优化手段,这个架构的请求方式是不会有任何改变的。也就是说,该架构所有的读写操作都是实时发生的,就算你设定了读写分离其实也是把这一切的工作依然是实时的,全部由MySql数据库来承受。所以这种请求方式的架构是有瓶颈的,虽然说理论上你还可以部署更多的数据库读写分离来减轻压力,就算是实时的请求也能扛得过去,但依然存在一个问题,更多的数据库部署意味要添加更多的服务器,这个成本其实是很高的,所以网站优化的另外一个思维就是在当前服务器中减轻数据库的压力,减轻访问(连接)的次数,而并不是不断通过添加服务器来解决。
2.大型网站的优化方向
1.增加服务器,设置读写分离(主从复制)。
2.增加cpu,高速的IO读写硬盘等硬件和网络带宽。
3.在MySql层面做各项优化,如:索引优化,分表等
4.使用反向代理和负载均衡技术(nginx,H3C,F5)
5.聘请可靠的开发技术团队和优秀的运维团队
6.使用NoSql作为缓存中间层
3.NoSql的含义
NoSQL ,(Not Only SQL),泛指非关系型数据库, 它是由一次叫“反Sql运动”的社区讨论而诞生的体系。这个运动的发起最早源自于社区网站 LiveJournal的开发团队,它们的初衷是为了用于减少数据库连接数,减轻数据库的工作压力,但发展至今有着其他不同的应用领域,因此NoSQL处于一种所谓百家争鸣的,各执一词的时期。但我们作为NoSql的学习者和应用者,我们不需要关心和纠结这些NoSql的争论,也不需要参与到这些争论当中。
NoSql的共同特点和优势:
NoSQL 通常是以key-value形式存储的(如:Memcache,Redis,Mongodb)
不支持SQL语句,
没有表结构
配置简单
灵活、高效的操作与数据模型
低廉的学习成本
能很好地作为MySql的中间层
能很好地支持PHP
NoSql的共同的缺点:
没有统一的标准
安全性极差
没有正式的官方支持
各种产品还不算成熟
权威支持的产品价格很高(如:阿里云),但这个其实成本现在很多公司给得起,至少比你设置更多的读写分离的数据库服务器成本还是低了不少.
NoSql的产品分类:
ttServer
redis
mongodb
memcache
Aliyun MQ
KVCache(Memcache)
二.Memcache的概述
1.Memcache的简介
Memcache是国外社区网站 LiveJournal的开发团队二次开发(加入了内置的分布式算法)的 高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态 Web 应用的速度、提高可扩展性。
Memcache的优点:
1.纯内存的存储机制,因此它是所有NoSql产品当中最简单也是速度最快,但是同时也是功能最弱的
2.内置分布式算法,使得开发者不需要自己去实现
3.它能把单项数据缓存的过期时间设置为30天,也能使得单项数据常驻内存当中
4.完美支持PHP的调用
Memcache的缺点:
1.由于memcache使用telnet协议进行传输,没有数据加密的功能,安全性很差
2.Memcache最大的内存存储空间(吞吐量)只有64M,如果64M的内存一旦爆满,Memcache会指定重启,并释放当前所有的内存,在内存数据就是无情的丢失也不会保留。
3.由于Memcache把数据置于内存中,所以服务器进行维护或者重启,那么数据就会丢失
4.数据零散,无法遍历,管理数据完整性非常一般.
Memcache的使用注意事项:
1.不要把安全性,敏感性,具有明文性过高的数据放到memcache当中
2.使用数据时候要注意压缩,尽量使用一些小型的数据进行存储(产品分类,文章栏目,用户登录的信息,计数器的结果,用户属性)
Memcache的存储格式:key=>value(键值对的存储方式)
Memcache在国内职场中的使用场景:
2.PHP + Memcache + MySql的架构图(lanmp):
lanmp = linux + apache + nosql + mysql + php
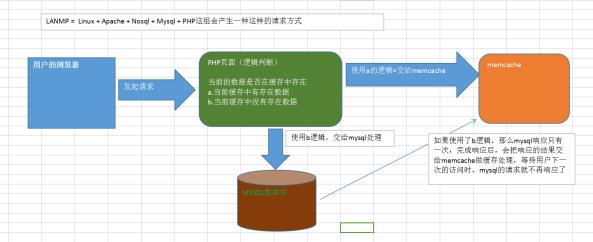
当前方式是客户端(用户浏览器)发起请求,这时这种架构的请求方式,我们称为非实时请求,那么每一次的请求必须通过中间的缓存层面进行,如果缓存中有数据,那么数据库就不会做出任何的响应,如果没有缓存的数据,数据库只会响应一次,并把响应的结果放到内存中等待用户下一次的请求。
三.Memcache的安装
1.安装包介绍
memcached:这个表示memcache的rpm软件包,用于实现memcache服务器安装
telnet:这个表示telnet客户端的rpm软件包,这个包的安装用于实现客户端连接memcache服务器
telnet-server:这个表示telnet的服务器端rpm软件包,这个包的安装用于实现telnet客户端的启动
2.安装说明
安装memcache这3个包必须一起安装,而不能分开安装,否则他们依赖关系你需要自己解决
3.使用yum进行memcache的安装
安装的命令: yum -y install memcached telnet telnet-server
使用(putty)执行命令安装过程如下:
登录完成后输入yum -y install memcached telnet telnet-server

注意事项:putty操作memcache特别的好用,但是不是代表只能使用putty执行以上的安装命令,你也可以使用xshell或者其他工具执行这个命令,然而xshell操作memcache不太好使。
四.启动Memcache的服务器
在memcache服务器中,如果希望能正常的启动memcache,并且可以在客户端正常的连接memcache服务器,那么需要启动memcached和xinetd的服务器。
memcached的说明:memcached是memcache服务器的守护进程,负责memcache服务器的启动,重启,关闭和状态的监控。其管理命令如下:
#启动memcache服务器
service memcached start
#重启memcache服务器
service memcached restart
#停止memcache服务器
service memcached stop
#查看守护进程的状态
service memceched status
#把memcached加入开机脚本
chkconfig memcached on
注意事项:如果重启或者停止memcache服务器,那么在memcache中存储的数据就会马上丢失,无法恢复。
xinetd的说明: xinetd是telnet服务器的守护进程,负责telnet客户端可以正常连接memcache服务器,默认的情况下占据11211端口
#启动telnet服务器
service xinetd start
#重启telnet服务器
service xinetd restart
#停止telnet服务器
service xinetd stop
#查看守护进程的状态
service xinetd status
#把xinetd加入开机脚本
chkconfig xinetd on
注意事项:xinetd重启或者停止,并不会导致memcache的数据丢失,但客户端会无法连接memcache服务器。所以如果想维护memcache服务器,那么可以停止telnet服务器
五.使用telnet连接Memcache
首先要清楚的知道,telnet和memcached一定要处于启动的状态,并且要知道当前的默认端口为11211
第2步:如果没有启动xinetd和memcache需要启动,命令如下;
service memcached start
service xinetd start
第2步:使用telnet客户端进行memcache服务器的连接
命令格式: telnet [memcache的服务器地址] [端口]
注意事项:如果刚打开telnet客户端敲入回车键,那么会出现ERROR,这时并不是代表连接失败,而是因为memcache服务器在等待您输入正确的指令,而回车键并不是一个正确的指令,所以它会报出ERROR的错误
六.Memcache的get,add,set,delete命令
1.get命令
这个命令用于获取memcache内存中的数据
命令格式: get [键名(key)]
比如:如果希望获取一个为name的键名,可以使用命令: get name

如果key不存在那么就会以END结束,如果key存在,那么返回如下所示:

2.add命令
这个命令就是像memcache的内存当中的某一个值添加数据,然而它在现实开发当中很少用,一般我们会用set直接取代它的操作,所以这个命令你只需要了解就可以了,
命令格式:add 键名 标识符 过期时间 字节的大小
说明:
标识符:一般只会填入1,也可以填写2,也可以999,也可以填写888,随便乱填但不可以是负数和0,也不可以是中文和特殊字符,只能是正整数
过期时间:0代表永远不过期,其余请求就是以秒作为单位,如:设为30,代表30秒后过期。
最大秒数可以设置为30*86400=30天
字节大小:就是打算添加的数据有多大,如:设为3,代表输入3个字节
使用add命令一个键名为name的数据,键值为php
命令的运行效果如下图所示:
add name 1 0 3

3.set命令
这个命令在开发当中使用的频率是100%,它作用很特别,如果一个键名已经存在那么set命令会修改该键名的值,如果该键名不存在那么set会创建这个键名的值,所以set既可以添加也可以修改,因此add就意义不大,因为add只能添加而不能够修改。
其命令格式: set 键名 标识符 过期时间 字节的大小
说明:
标识符:一般只会填入1
过期时间:0代表永远不过期,其余请求就是以秒作为单位,如:设为30,代表30秒后过期
字节大小:就是打算添加的数据有多大,如:设为3,代表输入3个字节
命令的运行效果如下图所示:
1.用set修改一个已经存在的键名,如:name

执行结果如下:

如果使用set命令,在memcache中操作一个已经存在的key那么就是修改的行为
set name 1 0 4 : 修改一个已经存在的键名为4个字节并且永远不过期
java : 修改name中的值
STORED : 代表写入成功
2.用set添加一个不存在的键名,如:project

执行结果如下:

发觉set命令如果操作一个不存在的key,那么其就是创建的行为
set project 1 0 6 : 添加不能存在的键名为project,其实大小为6个字节并且永远不过期
lovely : 添加project中的值
STORED : 代表写入成功
面试题:add和set有啥区别?
如果add操作的key已经存在,那么就会报错

而set不会报错,而是修改成功

因此我们使用set几率是100%
4.delete命令
这个命令就是删除 memcache在内存中的键,如果把键名删除了,那么对应的值也删除了,内存所占据大小呢也释放了
命令格式:delete 键名(可以存在也可以不存在)
命令的运行效果如下:
如果删除一个不存在的Key,那么会报出NOT_FOUND

如果删除成功就会释放当前的内存空间大小,并且报出DELETED

总结:以上实现增删查改的命令后,我发觉putty的界面非常饱满,我们能够清屏吗?
另外一个问题,如果我想退出memcache怎么呢?无法退出,所以只能关闭putty.
问题来了:那么putty不可以清屏也不能退出,那么为什么还要使用Putty而不使用xshell,其实xshell比putty更难用,因此我们一般使用putty.
关闭putty数据会被清空吗?因为关闭ssh工具不会关闭memcached的服务,如果希望数据被清空,那么如果我们使用service memcached restart会被清空吗?
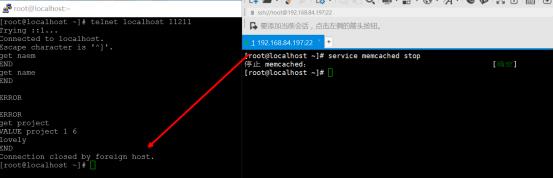
这时,如果重新连接memcache服务器,那么发觉数据就会被清空,如下所示:
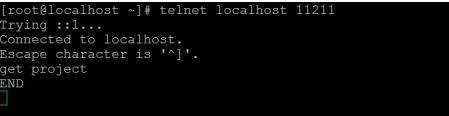
所以重启或停止memcached的服务都会导致数据丢失,因此memcache不能存储敏感且重要的数据
如果我们关闭xinetd服务(telnet协议),那么memcache还会被清空数据吗?
关闭telnet不会导致memcache的数据丢失,因此我们如果希望维护memcache中的数据,我们可以关闭xinetd
5.过期时间
memcache的过期时间一般用于add命令和set命令当中,过期时间以秒作为单位,0表示永远不过期,永远不过期的数据会永远占据着内存的空间,直到删除键名或者memcache重启时才会被释放,因此设置一个永远不过期的键名需要深思熟虑。使用过期时间的设置,可以有效的节省内存的空间。
一般设置过期时间,虽然理论上也可以使用add命令,然而由于set命令具备add命令的功能,且set命令本身具备修改的功能,因此我们在设置过期时间时,使用set命令的几率是最高的。
其命令格式: set 键名 标识符 过期时间 字节的大小
其实这个命令关键点就是过期时间的参数不能设置为0和小数点,必须为正整数
比如说:把一个为project2的键名的值设置为20秒内过期,可以使用以下方式:
set project2 1 20 6


6.set和add的注意事项
在memcache当中,memcache默认的最大存储内存空间为64M,而memcache对单个键名的存储的空间最大为1M,所以设置键名的时候,要合理的分配字节的大小,然后memcache分配字节大小是非常严格的,比如说,你分配了一个为3个字节大小的键名,如果你使用的时候超过3个字节或者有时候不足3个字节那么memcache就会报错。
1.设置一个为project3,字节大小为3,永远不过期的键名,其值为java(超过3个字节),这时由于java的值是4个字节,超过了3个字节的存储空间,这时memcache就会报错,效果如下:

2.设置一个字节的大小为3个字节,但是我们输入的数据为2个字节,如下所示:
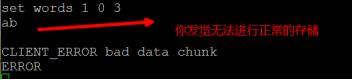
3.设置一个字节的大小为8个字节,但是我们输入的数据为4个字节,如下所示:

以上现象非常的奇葩,不好控制,所以我们在开发中,一般要预估数据的字节大小,输入的字节是多少那么就键入多少,不要造成浪费
思考题:如果我希望把Memcache当中所有的数据清除,释放掉内存,我们应该怎么做呢?
1)暴力关闭或者重启linux或者关闭或者重启memcached服务
2)如果仅仅希望在业务当中放弃所有的key,那么我们可以使用flush_all命令


以上的操作我们全部都是发生在命令行当中,那么如果我们希望在php当中操作memcache,那么我们还需要安装memcache的扩展,但是我们如果从php的官方文档中搜索memcache,你会发觉有两个memcache的相关类一个叫memcache一个叫memcached,这两者有什么区别,我们更应使用哪一个呢?
七.在PHP中安装Memcache的扩展
1.memcache类和memcached类的区别
如果我们打开http://www.php.net搜索memcache关键字会出现以下情况,如图所示:
memcache和memcached是的功能是一样的.
memcache类支持php5.3 - php5.6的单服务器和多服务器的操作但多服务器的操作在Linux操作系统中兼容性会出现bug.为了在Linux中很好地兼容服务器的操作php官方推出了一个叫memcached的类,该类只能运行在Linux操作系统当中支持Linux的单服务器和多服务器操作,如果你使用Linux操作系统作为服务器必须使用Memcached类.
因为Memcached类是基于一个叫libmemcached的库,这个库是用C语言开发的在Linux当中运行的效率最高.
4.安装memcache和memcached两个扩展
您可以同时安装这两个类,如果当前是php5.6那么我们还需要用到memcached的addServer方法来做分布式服务器的连接,安装的命令如下:
yum install -y --enablerepo=remi --enablerepo=remi-php56 libmemcached php-pecl-memcache php-pecl-memcached
第1步:在putty或者xshell当中键入以下命令,进行php扩展安装,命令如下所示:
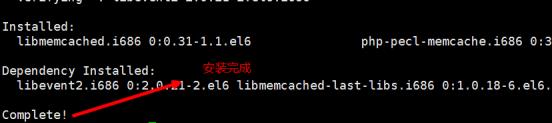
yum install -y --enablerepo=remi --enablerepo=remi-php56 libmemcached php-pecl-memcache php-pecl-memcached

出现以下界面,代表memcache和memcached的扩展库已经完成了安装
第2步:安装完成后,必须重启apache服务器,重启的命令:service httpd restart

第3步:重启apache服务器完成后,需要重新在浏览器端访问phpinfo.php这个文件查在apache的站点目录/var/www/html编写phpinfo.php,运行后如下:
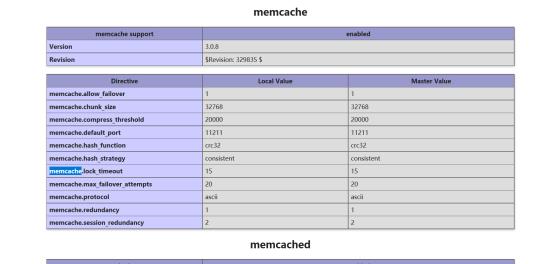
看是否已经存在memcache和memcached的扩展模块,出现以下界面,就代表安装成功:
八.Memcached类的常用方法说明
重要方法:
addServer(host,port):host就是linux服务器的地址,port一般就是11211(memcached的端口),用于连接memcached服务器
set(key,value,exipre) : 用于修改或者添加内存的memcached数据,该方法有3个参数
key键名,value是键值,exipre是过期时间,exipre默认为0,如果设置为秒,最大只能设置为30天秒数
get(key):获取对于键值对
delete(key):删除memcached当中键值对
1.使用addServer方法连接memcache服务器
详细代码参考code/addServer.php,上传代码到/var/www/html中进行测试
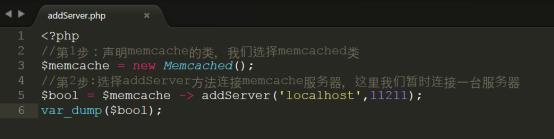
测试结果如下图所示:

2.set方法设置Memcache中的值
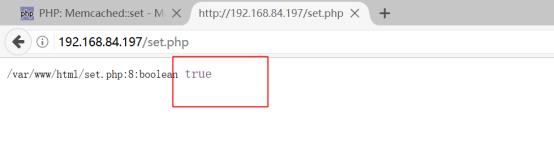
详细代码参考code/set.php,上传代码到/var/www/html中进行测试
在memcache中创建一个叫做phper的键名,值为jimmy
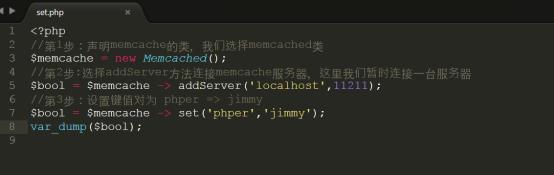
如果该key在15秒后过期,那么我们可以把代码设置为如下:
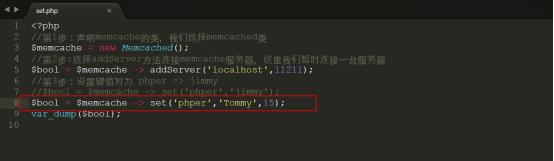
测试结果如下图所示:
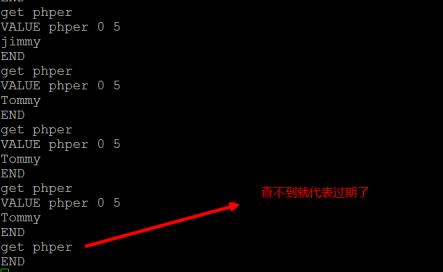
telnet客户端的结果如下:

如果15秒过期后,就查不到结果了:
3.使用get方法获取Memcache中的键值
详细代码参考code/get.php,上传代码到/var/www/html中进行测试
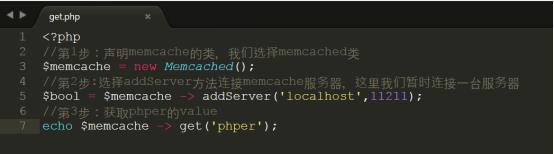
以上操作如果获取的数据在memcached命令行中set的key是没有办法正常获取,会返回 0或者白屏现象,除非把标识符设置为0
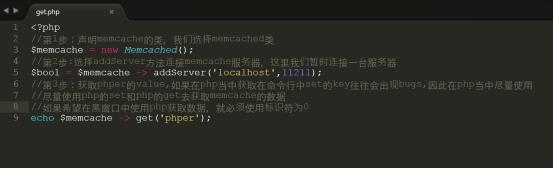
如果使用php去set,然后在同时get那么就不会存在任何的问题
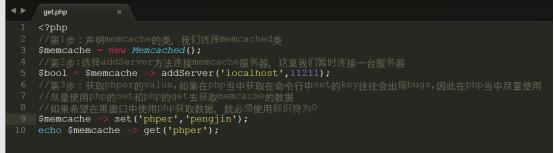
测试结果如下图所示:
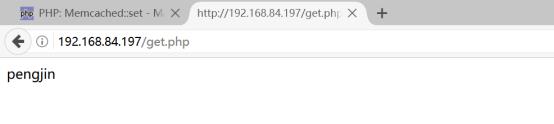
telnet客户端的结果如下:
4.使用delete删除Memcache中的键名
详细代码参考code/delete.php,上传代码到/var/www/html中进行测试
第1步:使用php先set一个key,然后删除
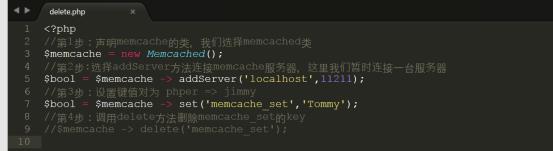
telnet客户端的结果如下:
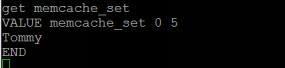
去掉注释进行删除,结果如下:

php自己set的key是可以成功delete的
第2步:使用memcached先set一个key,然后删除

修改delete.php的代码如下:
执行结果如下:

发觉php的delete方法可以删除memcache命令行中set的key,不需要理会这个可以key的标识符
九.Memcache存储PHP各种数据类型
1.php中的9种数据类型回顾
标量类型(4种):string int boolean float
复合类型(2种):array object
特殊类型(3种): 序列化数据resource null
2.存储php中的标量类型
详细代码参考code/biaoliang.php,上传代码到/var/www/html中进行测试
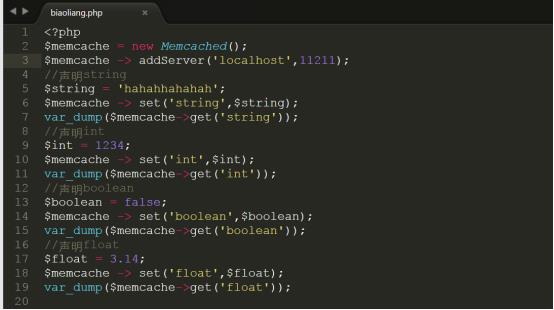
测试结果如下图所示:
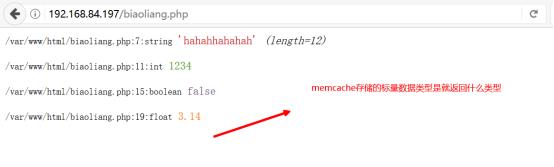
memcache能够实现自动的数据类型转化,查看telnet的结果如下:
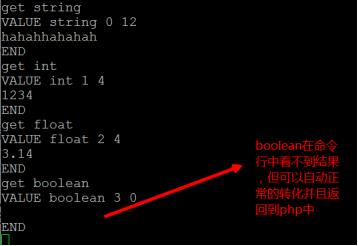
3.存储php中的复合类型(array和object)
①测试复合类型数组的存储,代码如下所示:
详细代码参考code/mix_array.php,上传代码到/var/www/html中进行测试
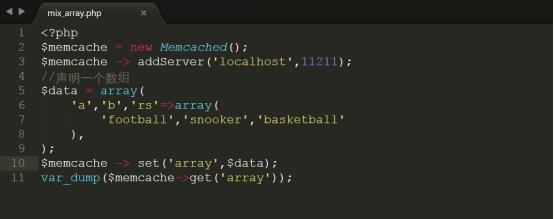
测试结果如下图所示:
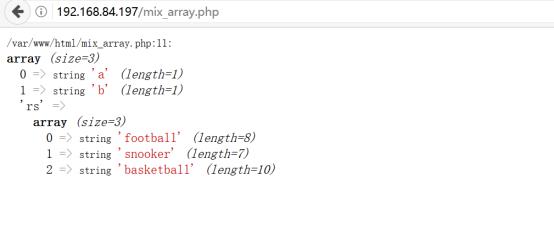
telnet客户端的结果如下:

②测试复合类型对象的存储,代码如下所示:
详细代码参考code/mix_object.php,上传代码到/var/www/html中进行测试
详细代码参考code/mix_object2.php,上传代码到/var/www/html中进行测试
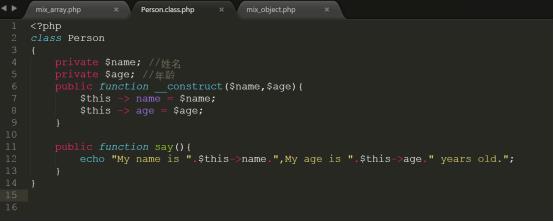
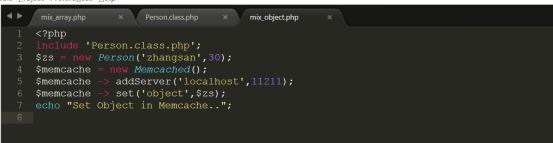
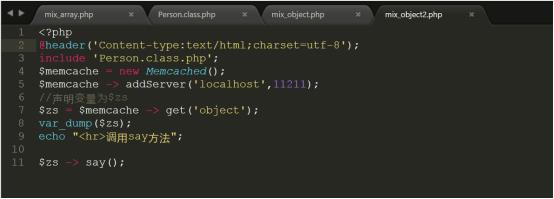
测试结果如下图所示:
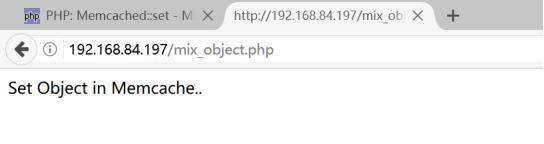
查看php的set结果

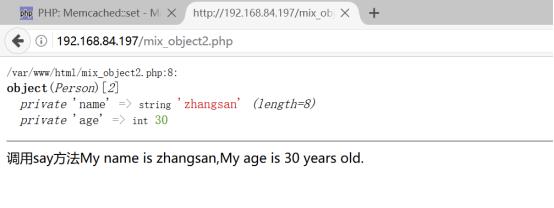
查看php的get结果
4.存储php中的特殊类型
①测试特殊类型序列化的存储,代码如下所示:
详细代码参考code/serialize.php,上传代码到/var/www/html中进行测试
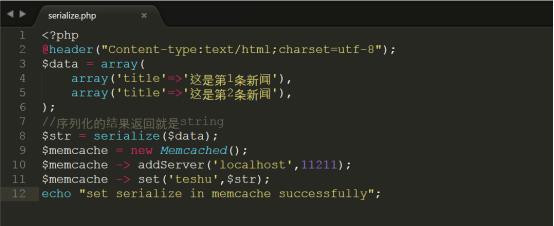
测试结果如下图所示:

由于序列化后的内容是string所以相当于你把序列化内容用标量string进行存储,所以memcache的返回在序列化中就是返回string,因此如果你需要反序列化就可以直接调用unserialize方法:
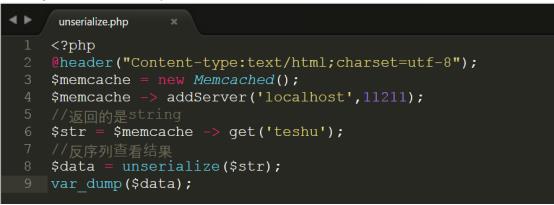
测试结果如下:

说明:在现实开发当中把null值和resource的类型值存放在memcache当中的意义是不大,因此特殊类型的存储只需要关心序列化的存储操作。
十.登录优化
在网站当中我们做登录一般都是读操作,比如有一个用户名为zhangsan登录网站,那么我们通常的语句为select * from users where username=’zhangsan’,于是username我们一般会设置索引字段。这时有2个这样的优化手段:
1)前缀索引
2)使用memcache+前缀索引进行优化
1.什么是前缀索引
在开发的过程中,默认的情况下如果你对一个字段进行索引,那么mysql会根据字段的最大字符的长度进行索引。有如下记录:
zhangsan
lisi
wangwu
假设对这3条数据进行索引我们会使用以下的语句
create index uname on tableName(username),这时uname的长度有多少呢?
长度就是按最大的字符长度zhangsan来取值所以索引的长度等于8个字符,发觉lisi用户8个字符,wangwu也用不上8个字符的索引,因此就造成索引的空间浪费,导致MYI文件增大,因为就有前缀索引的说法,假设有以下用户:
张三
李四
王五
其实对于以上的用户来说,我们只需呼叫其姓氏就能够定位某一个具体用户,所以前缀索引的定义就是如果索引的某一个长度已经足以标识一个记录的所有值,那么我们就把索引成为前缀索引,比如:张可以标识张三,张就是一个前缀索引。如果需要实现前缀索引我们可以参考以下例子:
第1步:把demo.sql文件上传到Linux服务器当中的任意目录,然后使用mysql的导入方式进行数据的导入,如下图所示:

查询结果如下:
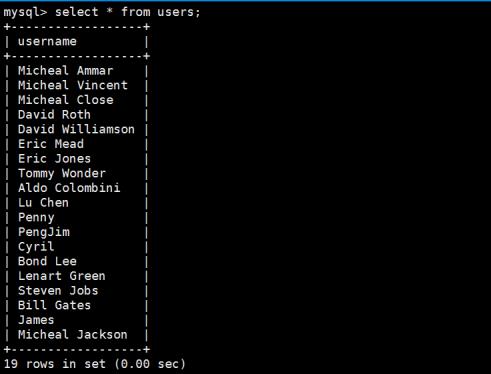
每一条数据都是唯一的,并且该表也没有建立任何的索引,所以需要对该表进行前缀所以的建立以节省索引的空间,因此我们建立前缀,那么前缀索引的长度应该是多少呢?假设不知道我们就需要去求出前缀索引的长度
第2步:用肉眼查看发觉David Williamson是最长的记录,因此我们说如果我们假设用前缀长度5,7,9来对数据进行呼叫那么是否可以成功定位出每条唯一的数据呢?编写select语句如下,分别统计5,7,9这3个数字的前缀:
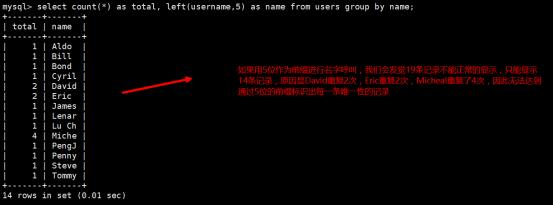
因此5位的长度是不成立的,无法成为前缀索引的长度。
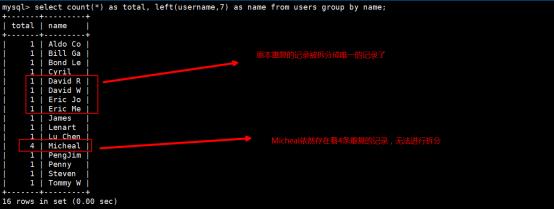
因此7位的长度是不成立的,无法成为前缀索引的长度。
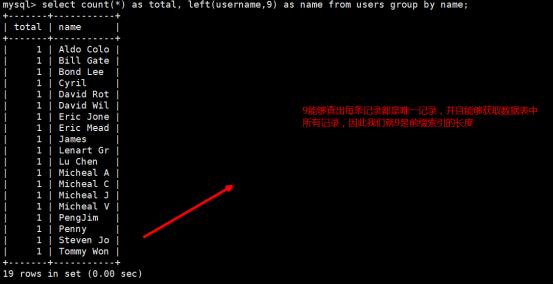
9是索引的长度,如果使用David Williamson来作做索引的长度是16位,9位能够大大节省7个字符的长度,因此我们求出了前缀索引最优的长度是9,所以我们就可以使用9来建立前缀索引.
第3步:使用前缀索引建立语法如下:
alter table 表名 add index 索引名称(字段名称(长度));
执行语句如下所示:

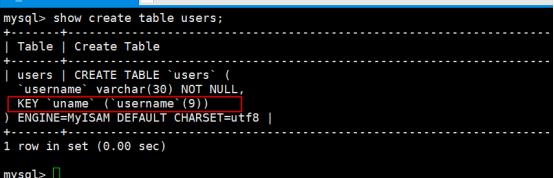
第4步:使用explain查看是否能够使用前缀索引
explain select * from users where username=’David Williamson’

发觉前缀索引是可以被9个长度所使用的,这时其实我们只是在数据库的层面优化了索引,但是无论数据库做了多好优化,如果中间没有一个缓存的层面,那么所有的压力和响应都会发生在数据库当中,数据库一定需要去硬盘当中查找数据,不管数据是否存在,因为我们可以减少数据库压力,令数据库可以得到休息的时间。
2.使用memcache+前缀索引进行登录优化
我们明白前缀索引的原理后,我们可以设计用户表如下:
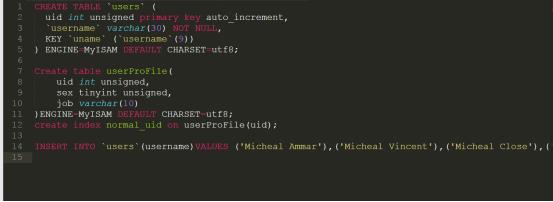
编写php的优化登录代码如下:
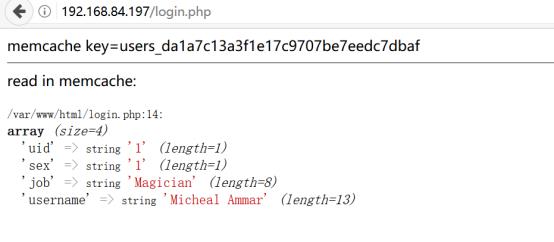
测试如下:
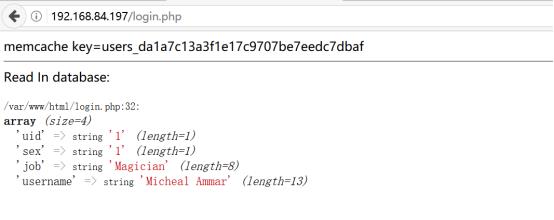
十一.使用memcache实现session入库共享
1.查看session的默认存储方式

session在默认的情况下以文件的方式放在Linux当中,所以session.save_handler为files
每一个session其实就指代一个访问网站的用户,如果网站的访问量很多,那么就会尝试很多的session文件,在session.save_path目录中(/var/lib/php/session),那么文件增多就会导致硬盘的IO读写压力过大,并且会占据服务器很多的硬盘空间,因此我们可以优化session的存储方式为memcache,首先我们先编写代码来查看session的默认存储方式
2.在PHP中修改session的存储到memcache
首先,经过分析我们知道session.save_handler是代表sesession默认存储方式为files,而存储的文件路径记录在session.save_path当中,放置在linux服务器中/var/lib/php/session,在phpinfo当中如下图所示
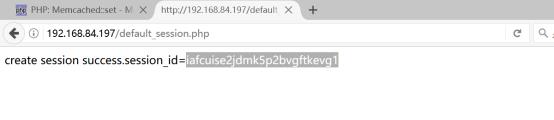
1.编写php文件(code/default_session.php)查看默认的存储结果,代码如下图所示
在浏览器中发觉session_id如下图所示
在linux的putty中切换到/var/lib/php/session中,该目录是session默认的存储目录,进行ls -lh的查看结果如下图所示:
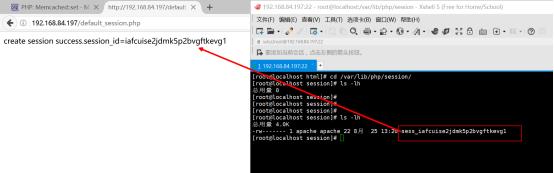
打开该文件,工作目录在/var/lib/php/session下使用vim打开进行查看
内容如下图所示:

因此足以证明session是存放在文件当中的,而这个缺点也是显而易见的。
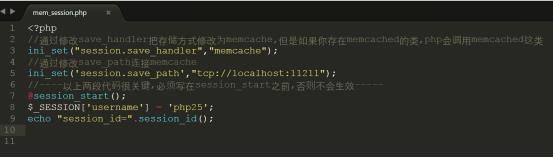
2.由于file的存储读取内容比内存慢,且占据硬盘的空间,所以我们需要 修改session默认存储方式由files变为memcache,如下图所示:
详细代码参考code/mem_session.php,上传代码到/var/www/html中进行测试
修改session存储方式可以通过修改session.save_handler去改变
修改memcache的连接方式可以通过修该session.save_path去改变
把代码上传到/var/www/html下进行测试:
在正式使用浏览器测试之前,首先为了确保实验的正确性那么必须先删除/var/lib/php/session目录下所有的文件,以便于您的观察,如果php代码运行后,该目录不会在产生文件,并且memcache当中会出现session的键名和键值内容,那么就代表session成功的存储到memcache当中去了。所以必须遵循以下步骤
第一步:cd /var/lib/php/session下删除所有的文件

确认工作目录完成后,使用rm -rf *删除所有的文件
第二步:在浏览中访问mem_session.php,结果如下图所示:
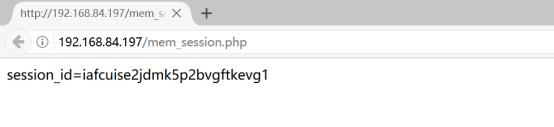
出现以上结果,马上去查看linux中的/var/lib/php/session下是否存在一个文件,使用命令ls -lh

第三步:复制浏览器中的session_id
然后在telnet客户端使用get iafcuise2jdmk5p2bvgftkevg1进行查看
因为session会用session_id作为memcache的键名对 session中的内容进行存储,如下图所示;

出现以上结果,代表session成功的存储到memcache当中,速度会得到大大的提升。
如果用户长时间不操作,默认的情况下大概是30分钟左右,那么memcache就会把session_id的键名删除。
十一.搭建分布式的Memcache服务器
分布式的意思其实就建立1个以上的数据库,分布在不同的服务器当中,所以读写分离和主从复制的MySql数据库服务器又可以称为MySql分布式数据库,但MySql的读写分离你是需要自己实现的,并且你需要清楚的知道哪台服务器是负责写,哪台服务器负责读.
部署分布式的过程,其实就是克隆服务器Slave的过程,因为我们在数据库读写分离的Grant用户授权中已经克隆了一台Slave服务器,所以Slave的克隆我们在这里可以省略了.`然而你依然需要注意以下几点:
第1点:
Master和Slave这时在分布式服务器当中他们属于平级的服务器,没有所以谁只能读谁只能写的区分,Master和Slave服务器在Memcache服务器中是可读可写的,也就是说可以随便的读写,因为Memcache的内置一个分布式的算法,能够清楚的区分数据在哪个服务器当中,所以在Memcache中这个是一个非常方便的,也不需要你配置任何文件更没有什么主从复制的过程,这也是Memcache很特别的一点.其实因为Memcache的数据是缓存数据是临时性的,所以Memcache开发者认为主从复制没意义,所以他们通过分布式算法来管理数据.
第2点:
Master和Slave服务器必须同时都关闭了iptables和selinux,否则分布式是不会成功
第3点:
Master和Slave服务器必须同时都安装了Memcached的服务器并且开启了该服务
并且要确定Master的服务器IP和Slave服务器IP
Master的IP为: 192.168.84.197
Slave的IP为:192.168.84.85
完成上述3点那么memcache的分布式服务器就部署成功了。