redis性能调优笔记(can not get Resource from jedis pool和jedis connect time out)
Posted 扎心了老铁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis性能调优笔记(can not get Resource from jedis pool和jedis connect time out)相关的知识,希望对你有一定的参考价值。
对这段时间redis性能调优做一个记录。
1、单进程单线程
redis是单进程单线程实现的,如果你没有特殊的配置,redis内部默认是FIFO排队,即你对redis的访问都是要在redis进行排队,先入先出的串行执行。
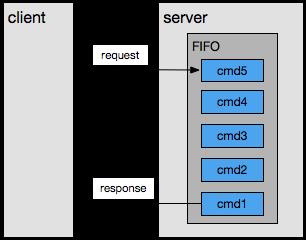
之所以能够保持高性能是因为以下3点:
1)内存操作
2)数据结构简单
3)大多数是hash操作
redis基本的命令耗时都是us级别的,所以及时是单进程单线程,也能保证很高的QPS。
2、can not get Resource from jedis pool和jedis connect time out
如果你对redis访问不正常,表现为抛上面两个异常,基本可以判断你需要对redis使用方式或者性能进行调优了。
你可以尝试使用如下几个办法:
1)修改redis客户端最大链接数
这个配置很简单,默认是10000,一般来说,10000这个数字已经够大了。
################################### LIMITS #################################### # Set the max number of connected clients at the same time. By default # this limit is set to 10000 clients, however if the Redis server is not # able to configure the process file limit to allow for the specified limit # the max number of allowed clients is set to the current file limit # minus 32 (as Redis reserves a few file descriptors for internal uses). # # Once the limit is reached Redis will close all the new connections sending # an error \'max number of clients reached\'. # maxclients 10000
不过,对这个数字的设置你要参考你的linux系统文件打开数。
一般来说,maxclients不能大于linux系统的最大连接数。
当然你可以将使用redis的linux用户对应的最大链接数改大,方式是修改/etc/security/limits.conf,我们这里把arch用户的最大链接数改成了100000
#<domain> <type> <item> <value> arch soft nofile 100000 arch hard nofile 100000
2)安全的释放链接!
一定要安全的释放链接,注意一些异常情况一定要能捕获到,并且释放链接,这里给出一个亲测有效的释放链接的方式,使用jedis set做例子吧
public void set(String key, String value) { Jedis jedis = null; boolean broken = false; try { jedis = jedisPool.getResource(); jedis.set(key, value); } catch (JedisConnectionException ex) { jedisPool.returnBrokenResource(jedis); broken = true; throw ex; }finally { if (jedis != null && !broken) { jedisPool.returnResource(jedis); } } }
3)jedis对超时的配置
一般来说有两个,maxWaitMillis和timeout,前者是链接等待时间,后者是cmd执行时间。
a)maxWaitMillis:客户端尝试与redis建立链接,当达到这个配置值,则抛出异常can not get Resource from jedis pool
b)timeout:客户端读超时时间,当超过这个配置值,抛出异常read timeout。
当然一般来说,如果大规模的爆发这两个异常,那么单纯修改这两个值其实没有什么用!
4)如果你是高并发场景,请注意慢查询
我遇到的慢查询场景有两个:
a)keys *
b)读写很大的数据块100M
如果高并发的有上面两种操作,那么问题就暴露了,回到redis单进程单线程的模式,那么当查询很慢的时候,势必会阻塞后面client的链接和cmd,如果慢查询并发量很高,造成超时和链接失败也就不足为奇了。
遇到这些情况,一般来说,都要改业务代码。方式是:
a)拆key,把key拆小,降低单个cmd的执行时间;
b)横向扩展redis集群,通过分桶将这种类型的操作均衡到多个实例上去。
当然你能通过修改业务实现,不用keys或者不在redis里缓存大量数据,最好了。
3、慢查询分析
如果你需要运维自己的redis,那么定期去查看redis的慢日志会给你一些很好的发现。
慢日志会帮你记录redis的慢查询,慢日志的配置如下。
就两个:
a)slowlog-log-slower-than, 单位是us,超过这个值就会被认为是慢查询了 (负数:禁用慢查询功能,0:记录所有执行命令,也就是所有命令都大于0,正数:大于该值则记录执行命令)
b)slowlog-max-len,单位是条数,这个值是保留最新redis缓存慢日志的条数List,一般你可以设置个1000条,分析够用了。
################################## SLOW LOG ################################### # The Redis Slow Log is a system to log queries that exceeded a specified # execution time. The execution time does not include the I/O operations # like talking with the client, sending the reply and so forth, # but just the time needed to actually execute the command (this is the only # stage of command execution where the thread is blocked and can not serve # other requests in the meantime). # # You can configure the slow log with two parameters: one tells Redis # what is the execution time, in microseconds, to exceed in order for the # command to get logged, and the other parameter is the length of the # slow log. When a new command is logged the oldest one is removed from the # queue of logged commands. # The following time is expressed in microseconds, so 1000000 is equivalent # to one second. Note that a negative number disables the slow log, while # a value of zero forces the logging of every command. slowlog-log-slower-than 10000 # There is no limit to this length. Just be aware that it will consume memory. # You can reclaim memory used by the slow log with SLOWLOG RESET. slowlog-max-len 128
查询慢日志的方式是,通过redis-cli
1、slowlog get [n]
n:条数,可选
10.93.84.53:6379> slowlog get 10 1) 1) (integer) 105142 2) (integer) 1503742342 3) (integer) 66494 4) 1) "KEYS" 2) "prometheus:report:fuse:*" 2) 1) (integer) 105141 2) (integer) 1503742336 3) (integer) 67145 4) 1) "KEYS" 2) "prometheus:report:fuse:*"
4个值,从上到下依次是分日志id、发生时间戳、命令耗时、执行命令和参数。
慢查询功能可以有效地帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
-
slowlog-max-len:线上建议调大慢查询列表,记录慢查询时Redis会对长命令做阶段操作,并不会占用大量内存.增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上. -
slowlog-log-slower-than:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值.由于Redis采用单线程相应命令,对于高流量的场景,如果命令执行时间超过1毫秒以上,那么Redis最多可支撑OPS不到1000因此对于高OPS场景下的Redis建议设置为1毫秒. -
慢查询只记录命令的执行时间,并不包括命令排队和网络传输时间.因此客户端执行命令的时间会大于命令的实际执行时间.因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此客户端出现请求超时时,需要检查该时间点是否有对应的慢查询,从而分析是否为慢查询导致的命令级联阻塞.
-
由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行
slowlog get命令将慢查询日志持久化到其他存储中(例如:mysql、ElasticSearch等),然后可以通过可视化工具进行查询.
4、Linux内存不足
当你启动redis的时候,你可能会看到如下warning
16890:M 21 Aug 12:43:18.354 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add \'vm.overcommit_memory = 1\' to /etc/sysctl.conf and then reboot or run the command \'sysctl vm.overcommit_memory=1\' for this to take effect.
如果overcommit_memory=0,linux的OOM机制在内存不足的情况下,会自动选择性Kill进程点数过高的进程。
如何修改这个值呢
// 修改这个文件 vim /etc/sysctl.conf // 加上下面这个配置 vm.overcommit_memory = 1 // 在不重启机器的情况下生效 sysctl vm.overcommit_memory=1
0:表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2:表示内核允许分配超过所有物理内存和交换空间总和的内存
以上是关于redis性能调优笔记(can not get Resource from jedis pool和jedis connect time out)的主要内容,如果未能解决你的问题,请参考以下文章