MySQL Basic
Posted carl_ysz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL Basic相关的知识,希望对你有一定的参考价值。
参考资料:
http://www.jianshu.com/p/91e3af27743f
一、mysql介绍以及安装
1.1 MySQL介绍
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区进行维护,采用GPL授权许可。Oracle在收购MySQL之后,有将MySQL闭源的潜在可能。Google Facebook等在大约2年前基本完全弃用了MySQL转向了MariaDB,而在较新的Linux发行版,例如CentOS7中也把MySQL改为了MariaDB。
MariaDB由MySQL的创始人麦格尔主导研发,直到5.5版本,MariaDB均按照MySQL的版本,而从2012年开始,不再使用MySQL的版本号,10.0.x均以5.5版为基础,进行新特性的开发。
MariaDB的API完全兼容MySQL,因此之后的MySQL均以MariaDB为准使用。
MySQL的架构如下图所示:
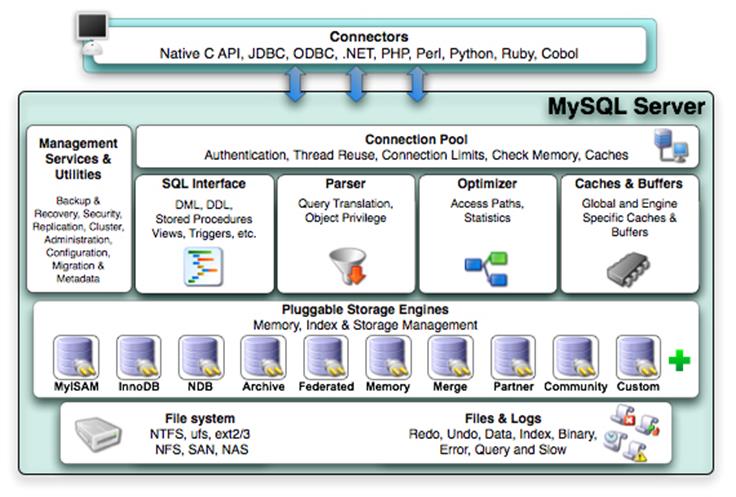
MySQL 组件:
- Connetcion Pool:MySQL的线程池,负责客户端连接的维护,包含连接密码认证,线程重用,连接数控制,内存检测以及连接线程的缓存功能。
- SQL Interface:SQL接口,提供了MySQL的大多数逻辑组件,类似Linux的Shell,包含了DML,DDL,视图,过程等等MySQL中常用的组件。
- Parser:MySQL的Query Translation,将SQL接口接收的语句转换为MySQL内部接口的语句,并提供了权限验证功能。
- Optimizer: SQL语句在查询之前会使用查询优化器对其进行优化,并记录到统计数据中。
- Caches & Buffers: MySQL自我管理的缓存和Buffer
- Pluggable Storeage Engines: MySQL支持插件式的存储引擎,存储引擎是MySQL和文件系统打交道的具体系统。
- File system: 外部的文件系统
- Files & logs: MySQL的物理视图,即MySQL在文件系统中的具体文件,例如事务中的Redo日志,Undo日志,Data数据文件,Index索引文件,错误日志,慢查询日志等等。
MySQL的设计是一个单进程多线程的架构设计,通过线程池来进行管理的每一个用户连接的设计,因此从一开始MySQL对多核心系统的利用就欠佳,直到MySQL5.5开始大规模企业化之后,一直致力于MySQL在多核系统中的表现。但是MySQL在每一个连接中依旧只能利用到单核心,即你的SQL语句哪怕再复杂,也只能用一个CPU去处理。
由于MySQL只有1个进程,而单个进程在Linux系统上能使用的内存是有限制的,因此MySQL没有其他选择,必须使用64位的操作系统,否则内存的限制将是一个无法解决的瓶颈。
1.2 安装
MaraiDB的安装方式多种多样,Centos7自带yum源中的就是MariaDB
yum install -y jemalloc jemalloc-devel #依赖于其中的一个共享库文件 安装方式一般有三种: (1) rpm: OS: 操作系统的yum源中自带 官方: 官网上下载rpm包并且进行安装 (2) 源码包: 需要自己编译,除非有特定需求,不建议这么做 (3) 通用二进制格式的程序包: 下面以CentOS7为例,使用通用二进制格式的程序包安装:准备admin用户mysql,mysql组 (1) 准备数据目录; 以/mydata/data目录为例;(最好是创建一个新的分区专门存放数据) chown -R mysql.mysql /mydata/data/ (2) 安装配置mariadb # useradd -r mysql # tar xf mariadb-VERSION.tar.xz -C /usr/local # cd /usr/local # ln -sv mariadb-VERSION mysql # cd /usr/local/mysql # chown -R root:mysql ./* # scripts/mysql_install_db --user=mysql -datadir=/mydata/data 初始化数据,不能使用绝对路径,只能在这个位置 # cp support-files/mysql.server /etc/init.d/mysqld # chkconfig --add mysqld (3) 提供配置文件 ini格式的配置文件;各程序均可通过此配置文件获取配置信息; [program_name] OS Vendor提供mariadb rpm包安装的服务的配置文件查找次序: /etc/mysql/my.cnf --> /etc/my.cnf --> --default-extra-file=/PATH/TO/CONF_FILE --> ~/.my.cnf 通用二进制格式安装的服务程序其配置文件查找次序: /etc/my.cnf --> /etc/mysql/my.cnf --> --default-extra-file=/PATH/TO/CONF_FILE --> ~/.my.cnf 获取其读取次序的方法: mysqld --verbose --help | less # cp support-files/my-large.cnf /etc/my.cnf 添加三个选项: datadir = /mydata/data innodb_file_per_table = ON skip-name-resolve = ON (4) 启动服务 # service mysqld start 安装完成后,使用mysql_secure_installation进行固化操作: root密码 禁止root远程登录 移除匿名用户
二、MySQL架构
2.1 MySQL逻辑架构
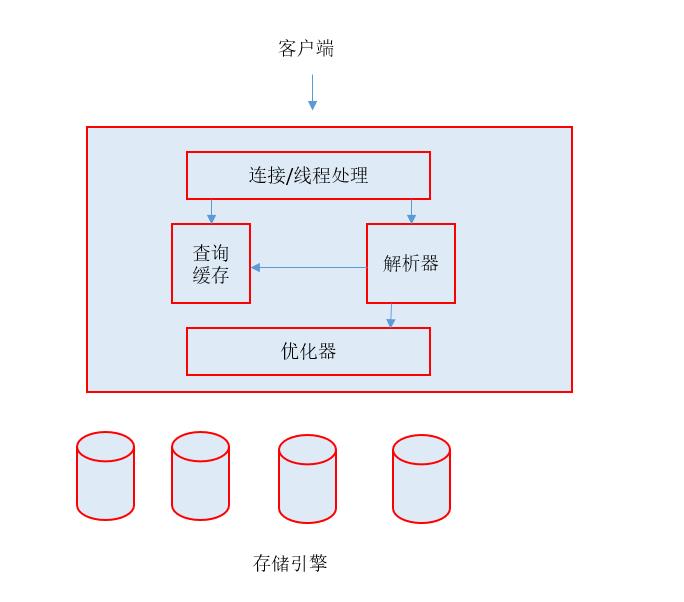
上图为MySQL的逻辑架构图,
第一层架构非常容易理解,大多数基于网络socket进行通信的工具或者服务都有类似的架构。比如连接处理、授权认证、安全等等。
第二层是比较有意思的部分,大多数MySQL的核心服务都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如日期 时间 数学 加密),所有跨存储引擎(即和存储引擎无关)的功能都实现这一层:存储过程、触发器、视图等。
第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。和GUN/Linux中的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信,这些接口屏蔽了不同存储引擎的差异。存储引擎API包含了几十个底层函数,用于执行例如"开始一个事务"或者"根据主键提取一行"记录等。存储引擎不会去解析SQL(InnoDb是一个例外,它会解析外键定义,因为MySQL服务器本身没有实现该功能),不同存储引擎之间不会相互通信,而只是简单地响应上层服务器的请求。
2.2 连接管理和安全性
每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在单独的线程中去执行,该线程只能轮流在某个CPU核心或者CPU中运行。服务器会负责缓存线程,因为不需要为每一个连接创建或者销毁线程。(MySQL5.5或者更新的版本提供了一个API:支持线程池Thread-Pooling插件,可以使用池中的少量线程来服务大量的连接)
当客户端(应用)连接到MySQL服务器时,服务器需要对其进行认证。认证基于用户名、原始主机信息和密码。如果使用了安全套接字(SSL,还支持证书)。一旦连接成功,服务器会继续验证该客户端是否具有执行某个特定查询的权限,例如,是否允许客户端是否对world数据库的Country表执行SELECT语句。
2.3 优化和执行
MySQL会解析查询,并创建内部数据结构(解析树),然后对其各种优化、包括重写查询,决定表的读取顺序,以及选择合适的索引等。用户可以通过特殊的关键字(hint)去提示优化器,影响它的决策 ,
也可以使用explain解析优化过程的各个因数,使用户可以知道服务器如何决策,并提供一个参考基准,以便于用户可以重构查询和schema,修改相关配置,使得应用尽可能高效运行。
优化器不关心表使用的存储引擎是什么,但是存储引擎对性能的影响又很重要。优化器会请求存储引擎提供容量或者某个具体操作的开销信息,以及表数据的统计信息等。例如,某些存储引擎的某种索引特性等。
对于SELECT 语句,在解析查询之前,服务器会先检查查询缓存,如果有缓存直接从缓存中返回。
2.4 并发控制
1. 读写锁:
读锁:共享锁
写锁:排他锁
就是一般的读写锁:读锁与读锁不互斥,写锁比读锁拥有更高的优先级。
2. 锁粒度:
一种提高共享资源并发性的方式就是让锁定对象更有选择性。尽量只锁定需要修改的部分数据,而不是所有的资源,可是问题是加锁也需要消耗资源,粒度越小的锁越需要管理,获取锁,检查锁是否删除,释放等等。
所谓的锁策略:就是在锁的开销和数据的安全性之间取得平衡。
MySQL提供了多种选择,每种存储引擎可以实现自己的锁策略和锁粒度。在存储引擎的设计中,锁管理是一个非常重要的决定,下面介绍2种最重要的锁策略。
表锁(table lock):
最基本的锁策略,并且是开销最小的。尽管存储引擎可以自己管理锁,MySQL本身还是会听各种机制来实现目的。例如,服务器会为诸如ALTER TABLE这样的语句使用表锁,而忽略存储引擎的锁机制
行级别锁(row lock):
行级锁可以最大程度地支持并发处理(同时也带来最大的锁开销)。众所周知,在InnoDB和XtraDB,以及其他一些存储引擎中实现了行级锁。行级锁只在存储引擎层实现,而MySQL服务器层没有实现。
而从用户的角度看又可以分为显示锁,用户可以显示请求调用的锁称为显示锁,是表级锁,而隐式锁则是由存储引擎自动施加的锁,用户不可见,由存储引擎决定。
从锁的粒度来看分为表级锁和行级锁,锁的粒度精细,实现越复杂,因此锁的使用策略就是在粒度和控制上实现一种平衡。
2.5 事务
事务: A transaction is a group of SQL queries that one threated atomically, as a single unit of work.
Atomicity:A transaction must function as a single indivisible unit of work so that the entire transaction is either applied or rolled back
Consistency:The database should always move from one consistent state to the next
Isolation:The results of a transaction are usually invisble to the other transactions until the transaction is complete.
Durability:Once commited, a transaciton\'s changes are permanent.
tx_isolation: 隔离级别
可以使用命令show variables like \'tx_%\';查看事务隔离级别tx_isolation
事务隔离级别:(Isolation Levels)
READ-UNCOMMITED:Transactions can view the results of uncommited transactions
READ-COMMITED:A transaction will see only those changes made by transactions that were already commited when it began, and its change won\'t be visible to other unitl it has commited
REPEATABLE-READ:It gurantees that any rows a transaction read will "look the same" in subsequent reads within the same transaction, but in theory it still allows another tricky problem: phantom reads.
SERIALIZABLE:one by one.
死锁:

看上面的2个事务,如果凑巧,2个事务同时执行了第一条SQL语句,更新了一行数据,同时也锁定了该行数据,接着2个事务去尝试第二条SQL语句,发现被对方锁定,跟Java代码中多线程顺序死锁几乎一样,此时需要外部因素介入才能解除死锁。
为了解决这种问题,数据库系统实现了各种死锁检测和死锁超时机制。越复杂的系统,比如InnoDB存储引擎,越能检测到死锁的循环依赖,并立即返回一个错误,这种方式非常有效,否则出现超慢查询。
还有一种解决方式,当查询时达到等待超时的设定之后放弃锁清秋,这种方式不太友好,而InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚。
前面说过,锁的行为和顺序和存储引擎相关的。也就是说,有些死锁是因为真正的数据冲突,有些则是这个存储引擎的问题。
2.5.1 事务日志
事务日志可以帮助事务的效率。使用事务日志,存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘。事务日志采用的是追加的方式(实际上这种日志追加方式非常常见),因此写日志的方式是一小块区域内的顺序I/O,而不是随机IO,随机IO需要在磁盘上的多个地方移动磁头,所以采用事务日志的方式相对要快的多,注意这里是指在机械硬盘上会快的多,固态硬盘...。事务日志持久后,内存中的数据可以慢慢地刷回到磁盘。目前大多数存储引擎都是这样实现的,我们通常称之为预写式日志(Write-Ahead Logging),修改数据需要写2次磁盘。
如果数据的修改已经记录到事务日志并持久化,但数据本身还没有写回磁盘,此时系统崩溃,存储引擎在重启时能够恢复这部分的数据。具体的恢复方式视存储引擎而定。
InnoDB中查看事务日志
innodb_log_file_size 文件大小
innodb_log_files_in_group 单组文件个数
innodb_log_group_home_dir 文件home目录
可以在MySQL初始化时在配置文件中指定。注意文件大小要适量。
2.5.2 MySQL中的事务
MySQL中提供了2种事务型的存储引擎:InnoDB和NDB Cluster。另外还有一些第三方的存储引擎也支持事务,比较知名的包括XtraDB和PBXT。
MySQL服务器层不管理事务,事务由下层的存储引擎实现的。所以在同一个事务中,使用多种存储引擎是不可靠的~
如果在事务中混合使用了事务型(InnoDB)和非事务型(MyISAM),在正常提交的情况下不会有问题,可是如果要回滚,非事务型的不能回滚,事务的结果将无法确定。
显示锁定和隐式锁定:
在InnoDB引擎中采用的是二阶段锁定协议(two-phase lockiing protocol)。在事务执行过程中,随时都可以执行锁定,锁只有在COMMIT或者ROLLBACK的时候才会释放,并且锁是在同一时刻被释放。前面描述的都是隐式锁定,InnoDB会根据隔离级别在需要的时候自动加锁。另外InnoDB也支持显式锁定,不过这些语句不属于SQL规范
SELECT clase [FOR UPDATE] [WITH READ LOACK]
MySQL也支持LOCK TABLES和UNLOCK TABLES语句,这是在服务层实现的,和存储引擎无关。它们有自己的用途,但是并不能代替事务处理。如果应用需要用到事务,还是应该选择事务型存储引擎。
Syntax:
LOCK TABLES
tbl_name [[AS] alias] lock_type
[, tbl_name [[AS] alias] lock_type] ...
lock_type:
READ [LOCAL]
| [LOW_PRIORITY] WRITE
UNLOCK TABLES
经常可以发现,应用已经将表从MyISAM转换到InnoDB,但还是显示地使用LOCK TABLES语句。这不但没有必要,还会严重影响性能,实际上InnoDB的行级锁工作的更好。
LOCK TABLES和事务之间相互影响的话,情况会变的非常复杂,在某些MySQL版本中甚至会产生无法预料的结果。因此,建议出了事务中禁用了AUTOCOMMIT,可以使用LOCK TABLES外,其他任何时刻都不要显式的执行LOCK TABLES,不管使用的是什么存储引擎!
2.5.3 多版本并发控制
MySQL中的大所数事务型存储引擎实现的都不是简单的行级锁。基于提升性能的考虑,同时实现了MVVC(多版本并发控制)。不仅仅是MySQL,包括Oracle,PostgreSQL等其他数据库系统也都实现了MVCC,但各自实现的机制不尽相同,因为MVCC没有一个统一的实现标准。
可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁操作,incident开销更低。虽然实现机制不同,大都实现了非阻塞的读写操作,写操作也只需要锁定必要的行。
MVCC的实现,是通过保存数据在某个时间点的快照来实现的。也就是说,不管需要执行多长的时间,每个事物看到的数据都是一致的。根据事物开始的时间不同,每个事务对同一张表,同一个时刻看到的数据可能是不一样的。
典型的实现方式:乐观(optimistic)并发控制和悲观(pessimistic)并发机制。下面我们通过InnoDB的简化版行为来说明MVCC是如何工作的
InnoDB的MVCC,是通过在每行记录后面保存2个隐藏的列来实现的。这2个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际时间,而是系统版本号(system version number)。每开始一个新的事务,系统的版本号递增。
事务开始时刻的系统版本号会做为事务的版本号,用来和查询每行记录的版本号对比。下面看在REPEATABLE READ隔离级别下,MVCC具体是如何操作的。
SELECT:
InnoDB根据以下条件检查每行记录:行版本号<事务版本号<删除版本号
a. InnoDB只查找版本号早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,是事务开始之前已经存在的或者是事务自身插入或者修改的。
b. 行的删除版本要么未定义,要么大于当前事务版本号。这样可以保证事务读取到的行,在事务开始之前未被删除。
符合2个条件的记录,才能被作为查询结果。
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
DELETE
InnoDB为删除的每一行保存当前系统的版本号作为行删除标识。
UPDATE
没更新一条记录,保存当前系统的版本号为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
保存着2个系统版本号,使得大多数读操作可以不用加锁。这样设计使得读的性能更好,并且保证只会读取到符合要求的行。不足的是每行记录都需要额外的空间,典型用空间换取时间。
注意:MVCC只有在REPEATABLE READ和READ COMMITED2个隔离级别下工作。其他2个级别不能使用MVVC。READ UNCOMMITED总是读取最新的行,而SERIALIZABLE总是对所有行为加锁。
三、存储引擎
存储引擎说白了就是如何在文件系统上存储数据、建立索引、更新、查询等等,是MySQL的真正实现方案,MySQL是采用一种插件式的存储引擎管理方案,可以通过show engines查看MySQL支持的所有存储引擎,可以使用show table status like [table_name]的方式来查看表的存储引擎。
(1) InnoDB
在mysql5.5之后,InnoDB就被指定为是默认的存储引擎,而MariaDB使用percona提供的XtraDB引擎作为InnoDB的增强版,非常适合大量的短期事务。
为了改善InnoDB的性能,Oracle投入了大量的资源,额外的贡献者也很有帮助。之前的版本在超过4核CPU的系统中InnoDB的表现不佳,现在已经可以很好的扩展到24核,32核系统中。
InnoDB的数据存储在表空间中:
根据配置有2种情况:
第一种所有的InnoDB表中的数据和索引放置于同一表空间中,而表空间文件会放放置datadir指定的目录中,数据文件大致上为ibddata1,ibddata2.....
第二种更为常用,每个表使用独自的表空间,需要在配置文件或者启动参数中设置innodb_file_per_table=ON来启用该功能,此时每个数据文件+索引在tb_name.idb中,表格式定义元数据文件 tb_name.frm,开启这个特性对于后期的扩展是必备条件,例如一个demo的db中存储了一个t1的表,如图所示生成2个文件
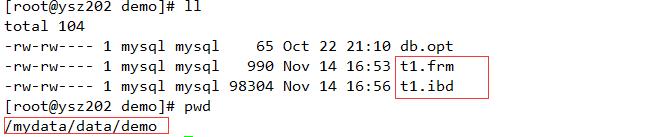
- InnoDB采用MVCC来支持高并发,实现了4个事务隔离级别,默认使用REPEATABLE READ,并且通过间隙锁(next-key locking)策略来防止幻读。
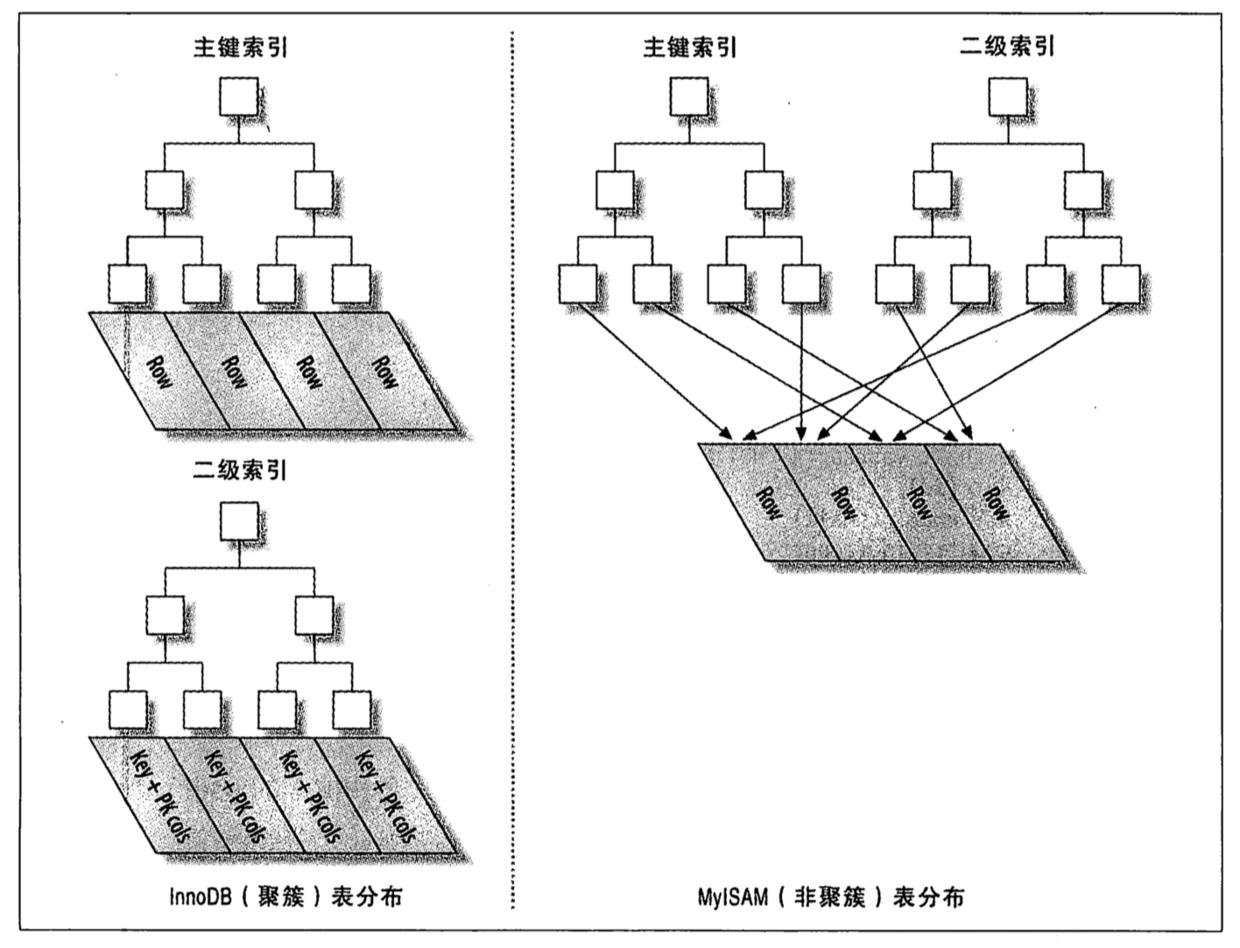
- InnoDB的表示基于聚簇索引。聚簇索引往往是主键索引,因此其主键索引查询有很高的性能。不过它的二级索引,即非主键索引中必须包含主键列,因此如果主键列很大,所有的索引都很大。
- InnoDB的行为非常复杂,官方手册中描述的非常清楚。
- 作为事务型的存储引擎,InnoDB可以实现真正的热备。
(2) MyISAM
MySQL自己研发的一个存储引擎,在MariaDB中使用aira作为增强版实现
表格式文件,数据文件,索引文件单独存放,分别是tb_name.frm,tb_name.myd,tb_name.myi
特性:
最大存储能力为256TB
支持全文索引Full Text
只支持表级锁
不支持事务、外键、数据缓存、不支持MVVC
只能手工修复
索引是非聚集索引
支持延迟更新索引
支持表压缩机制
MySQL中其他常见的存储引擎:
csv:将普通的csv作为MySQL使用
MRG_MYISAM:将多个MyISAM表合成为一个虚拟表
BLACKHOLE:黑洞
MMEORY: 内存,支持hash索引,表级别锁
PERFORMANCE_SCHEMA: 伪存储引擎
FEDERTED: 远程MySQL代理
MariaDB中还支持:
OQGraph:
SpinxSE: 可以和spinx集成
TokuDB:海量数据存储
Cassandra:可以和Cassandra集成
...
总结,如何选择存储引擎:
需要事务?InnoDB
需要外键?InnoDB
需要热备?InnoDB
需要Fulltext?MyISAM
四、查询缓存
从磁盘中读数据会产生磁盘IO,因此在读多写少的场景下,可以使用缓存。
MySQL天然支持查询缓存,在某些情况下还是可以用的,比如说单台服务器,多台服务器一般采用专门的缓存服务器比如Memcached,redis等等服务器实现。
这里的关注重点在MySQL本身的查询缓存,MySQL可以对每次查询做hash键,查询的数据为value进行缓存,而这里的查询key需要考略多方面因数:
查询本身
查询的数据库
客户端使用的协议版本。。。
注意: 查询语句任何的不同,哪怕是一个空格,一个大小写都会引起查询缓存的不同,因此所有程序员保持一定的SQL书写风格还是有必要的。
在前面的MySQL架构中描述了查询缓存实现的组件,而InnoDB,最常见的存储引擎是支持查询缓存的。
在实战中,查询缓存也有可能成为并发热点问题,这往往是由于多核竞争引起的,由于计算机的核心数较多,高并发场景下产生的竞争问题,这也是查询缓存的内存大小默认不会太大的原因,默认是16M.
同时要注意到,不是所有的数据都会缓存,比如我查询一个select now(),这完全不能缓存,一般包含以下内容的都不会缓存,比如用户自定一函数,存储过程,自定义变量,临时表,mysql库中的系统表,不确定值等等。
variables中的相关变量有:
query_cache_min_res_unit: 查询缓存中内存块的最小分配单位;
较小值会减少浪费,但会导致更频繁的内存分配操作;
较大值会带来浪费,会导致碎片过多;
query_cache_limit:能够缓存的最大查询结果;
对于有着较大结果的查询语句,建议在SELECT中使用SQL_NO_CACHE
query_cache_size:查询缓存总共可用的内存空间;单位是字节,必须是1024的整数倍;
query_cache_type: ON, OFF, DEMAND
query_cache_wlock_invalidate:如果某表被其它的连接锁定,是否仍然可以从查询缓存中返回结果;默认值为OFF,表示可以在表被其它连接淘宝的场景中继续从缓存返回数据;ON则表示不允许;
上述参数可以用来对查询缓存进行调优,调优流程图如下:
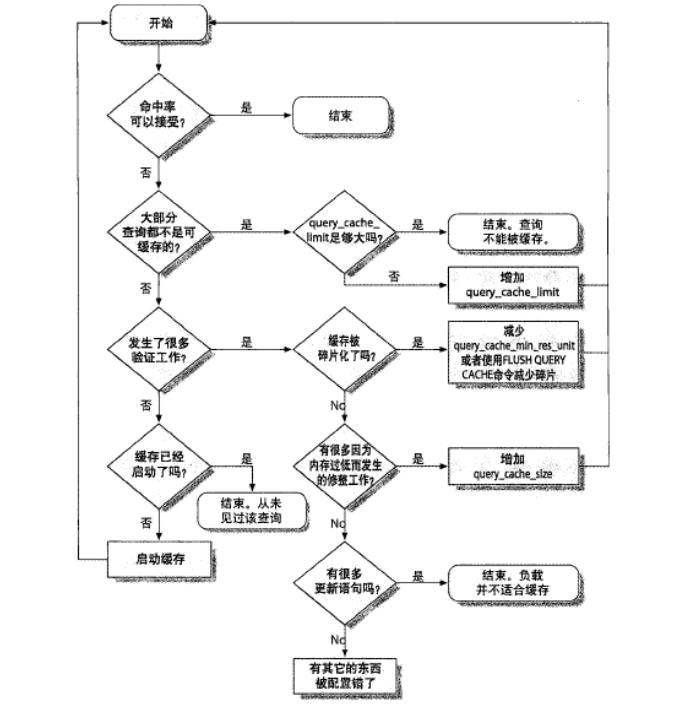
而缓存的命中率可以作为一个参考,注意只是一个参考,因为可能命中率很低,10条语句只有3条,但是如果这3条返回的数据量值得缓存,计算方式是Qcache_hits/(Qcache_hits+Com_select)
以上变量都是variables中的值,而相关变量大概如下:
SHOW GLOBAL STATUS LIKE \'Qcache%\'; +-------------------------+----------+ | Variable_name | Value | +-------------------------+----------+ | Qcache_free_blocks | 1 | | Qcache_free_memory | 16759688 | | Qcache_hits | 0 | | Qcache_inserts | 0 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 0 | | Qcache_queries_in_cache | 0 | | Qcache_total_blocks | 1 | +-------------------------+----------+
五、 索引简介
说起sql优化,大部分都落实在索引优化上,什么是索引,MySQL不可能在每次查询数据时将磁盘的数据全部加载到内存中,需要利用数据结构加载少量数据集到内存中即可,这部分数据集就是索引。索引的优点大致如下:
索引可以降低服务器查询的io次数
索引可以帮助服务器避免排序和使用临时表
索引可以帮助将随机I/O转换为顺序IO(在硬盘非固态的时候还是有用的)
索引功能主要由存储引擎来实现,不同的引擎可以使用不同的索引结构。
(1) B+树索引
B+树是一种常见的数据结构,是B树的变种,相对于B树,(B树是什么?略),增加了以下特性
1. 所有的关键字存储在叶子节点中
2. 为所有叶子节点增加了一个链指针
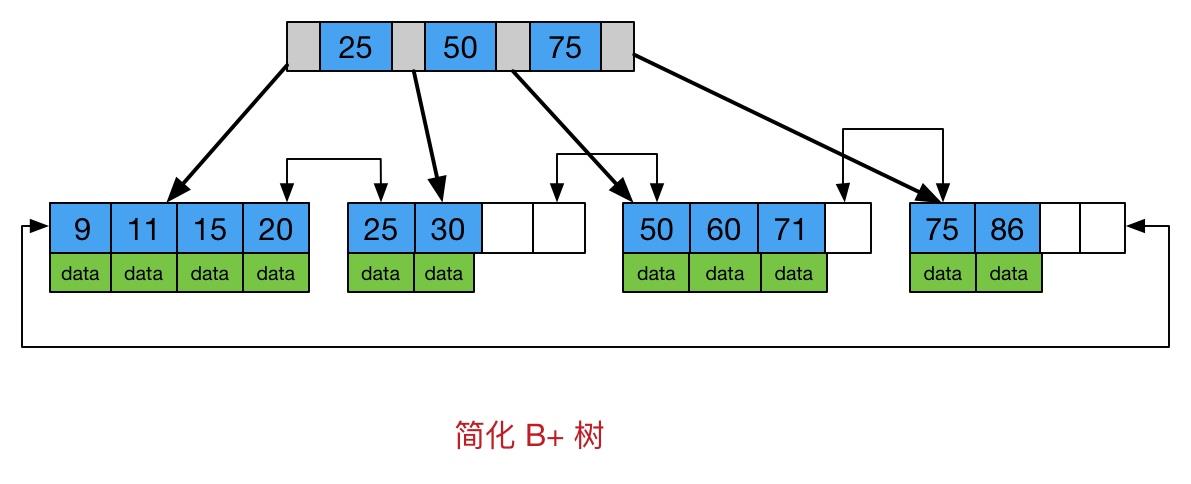
B+树是很适合硬盘读写的数据结构。红黑树等虽然也适合用来实现索引,比如JAVA中的Treemap就是红黑树,适合用来在内存中做索引。
这是由于局部性原理和磁盘预读,什么是局部性原理?时间上,data被用到后,之后的时间很可能再次被用到,空间上,data被用到后,附近的数据很可能被用到,这就是局部性,程序使用的数据在空间上和时间上都是比较集中的。由于磁盘的存取速度很慢,比如在机械硬盘物理上的平均寻址时间,由于linux系统不管什么io模型都必须经历的2个阶段(磁盘->内核空间,内核空间->用户空间)等等...,所以MySQL要尽可能的减少IO的存取次数,而B+树就比较合适,B+树内节点都没有data,只有叶子节点上有data,因此每个节点可以存储更多的数据,范围更大,单次IO的数据量更大,可以直接预读,而且由于新增链指针,可以很方便的进行区间查找,即MySQL中where子句中的between操作。
B+树索引在MySQL中有以下要点:
适用于:
精确值匹配,例如="aa"
最左前缀,例如like "Jin%"
范围匹配,例如 < >
精确匹配之后范围匹配,一般精确匹配都在左侧,而范围适合在右侧,且中间不能跳过其他字段
覆盖索引,索引中就包含要返回信息,不需要查找数据
不适用于:
-
- 不是按照索引的最左列开始查找;
- 不能跳过索引中的列;
- 如果查询中的某个列是范围查询, 则其右边的所有列都无法使用索引;比如like, between
- 索引列上使用函数, 或者算数运算
(2) hash 索引
注意:只有Memory存储引擎支持显式hash索引;
适用场景:
只支持等值比较查询,包括=, IN(), <=>;
不适合使用hash索引的场景:
存储的非为值的顺序,因此,不适用于顺序查询;
不支持模糊匹配;
(3) 空间索引(R-Tree):
MyISAM支持空间索引;
(4) 全文索引(FULLTEXT):
在文本中查找关键词;
上面只是常见索引的数据结构以及用法,索引中还存在着许多的细节问题。比如索引要独立使用,不要参与运算,使用函数等等,在选择索引时候使用左前缀考虑左前缀长度等等,多列索引的陷阱等等。
1. 利用索引排序?
由于索引是有序,因此order中的列存在索引时,可以通过索引来排序,否则有可以使用file sorting,这是很不好的。
2. InndoDB中的聚集索引?
聚族(聚集)索引就是叶子节点保存的就是数据本身,索引和数据在一起,一般主键索引才是聚集索引。
优点:数据访问更快,索引扫描无须来回标
缺点:插入速度严重影响插入顺序,比如InnoDB中按照主键逆序;全表扫描会慢;二级索引会变大,且需要二次查找
六、 explain字段说明
注意explain返回不是精确值,只是估计值
id: 当前查询语句中,每个SELECT语句的编号;
注意:UNION查询的分析结果会出现一外额外匿名临时表;
select_type:
简单查询为SIMPLE
复杂查询:
SUBQUERY: 简单子查询;
DERIVED: 用于FROM中的子查询;
UNION:UNION语句的第一个之后的SELECT语句;
UNION RESULT: 匿名临时表;
table:SELECT语句关联到的表;
type:关联类型,或访问类型,即MySQL决定的如何去查询表中的行的方式;
ALL: 全表扫描;
index:根据索引的次序进行全表扫描;如果在Extra列出现“Using index”表示了使用覆盖索引,而非全表扫描;
range:有范围限制的根据索引实现范围扫描;扫描位置始于索引中的某一点,结束于另一点;
ref: 使用了索引,但是可能返回多行根据索引返回表中匹配某单个值的所有行;
eq_ref:仅返回一个行,但与需要额外与某个参考值做比较;
const, system: 直接返回单个行;
possible_keys:查询可能会用到的索引;
key: 查询中使用了的索引;
key_len: 在索引使用的字节数;
ref: 在利用key字段所表示的索引完成查询时所有的列或某常量值;
rows:MySQL估计为找所有的目标行而需要读取的行数;
Extra:额外信息
Using index:MySQL将会使用覆盖索引,以避免访问表;
Using where:MySQL服务器将在存储引擎检索后,再进行一次过滤;
Using temporary:MySQL对结果排序时会使用临时表;
Using filesort:对结果使用一个外部索引排序;
以上是关于MySQL Basic的主要内容,如果未能解决你的问题,请参考以下文章