hadoop IO操作
Posted 张超五
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop IO操作相关的知识,希望对你有一定的参考价值。
1.什么是数据完整性
用户希望存储和处理数据的时候,不会有任何损失或者损坏。
hadoop提供两种校验:
1.校验和(常见循环冗余校验CRC-32)
2.运行后台进程来检测数据块
2.基本的基于文件的数据结构
在处理小文件的时候,为了避免多次打开关闭流耗费计算资源,hdfs提供了两种类型的容器SequenceFile和MapFile。
SequenceFile:
SequenceFile由一系列的二进制key/value组成,key/value必须是可序列化、可持久化的键值对。
key为小文件按名,value为文件内容,则可以将大批小文件合并成一个大文件。
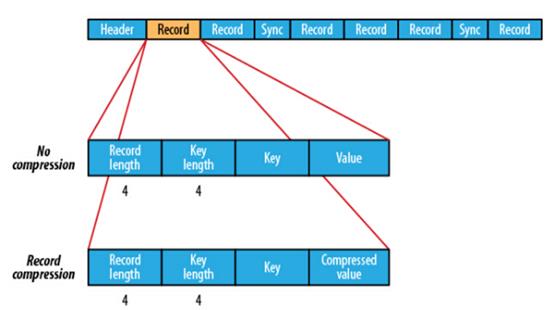
不限制用户和文件的多少,支持Append追加写入,支持三级文档压缩(不压缩,文件级,块级别)。
不压缩写数据:Write
记录级压缩写数据:RecordCompressWriter
块级压缩写数据:BlockCompressWrite
SequenceFile存储结构:
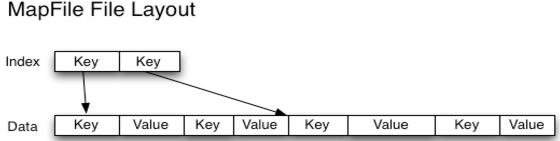
MapFile:
MapFile是排序之后的SequenceFile,由index和data两部分组成。index作为文件的数据索引,主要记录了每个Record的key值,以及该 Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件 位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。另外,MapFile的 KeyClass一定要实现WritableComparable接口,即Key值是可比较的。需注意的是,MapFile并不会把所有Record都记录到index中去,默 认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改。
缺点:
1.文件不支持复写操作,不能向已存在SequenceFile(MapFile)追加存储记录
2.当write流不关闭的时候,没有办法构造read流,也就是说,在执行文件写操作的时候,该文件是不可读的。
SequenceFile转换为MapFile
mapFile既然是排序和索引后的SequenceFile,所以可以把SequenceFile转换为MapFile,使用mapFile.fix()方法即可。
3.hadoop序列化的类型:Writable,Comparable,WritableComparable,RawComparator
Hadoop定义了两个序列化相关接口:Writable和Comparable
另外,还有WritableComparable接口,相当于继承了上述两个接口的新接口。
在hadoop中所有的key/value类型必须实现Writable接口,它有两个方法,分别用于读(反序列化)和写(序列化);
在MapReduce过程中需要基于key进行反复的排序,任意key类型,都必须实现Comparable接口。
WritableComparable继承了Writable和Comparable:所以,一些类型,比如IntWritable实现WritableComparable就可以了
Hadoop提供的一个优化接口是继承自Comparator的RawComparator:该接口允许其实现直接比较数据流的记录,无须先把数据流反序 列化为对象。
4.FileSystem FSDataInputStream
FileSystem 对象
取得FileSystem实例有两种静态方法:
(1)public static FileSystem get(Configuration conf)
//Configuration对象封装了一个客户端或服务器的配置,这是用类路径读取而来的
//返回默认文件系统(在conf/core-site.xml中设置,如果没有设置过,则是默认的本地文件系统)
(2)public static FileSystem get (URI uri,Configuration conf)
//参数URI指定URI方案及决定所用文件系统的权限,如果没有指定方案,则退回默认的文件系统
FSDataInputStream通过FileSystem来打开,例子如下:
- //获取命令行参数
- String uri = args[0];
- Configuration conf = new Configuration();
- conf.set("hadoop.job.ugi", "root,root123");
- //打开一个Hadoop FileSystem ,用FileSystem的静态方法获取之
- FileSystem fs = FileSystem.get(URI.create(uri) ,conf);
- //打开一个InputStream 对象
- FSDataInputStream in = null;
- in =fs.open(new Path (uri));
以上是关于hadoop IO操作的主要内容,如果未能解决你的问题,请参考以下文章