大数据MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
Posted Android Graphics
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据MapReduce(单词计数;二次排序;计数器;join;分布式缓存)相关的知识,希望对你有一定的参考价值。
前言:
根据前面的几篇博客学习,现在可以进行MapReduce学习了。本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分布式缓存)。
一 概述
定义
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。
适用范围:数据量大,但是数据种类小可以放入内存。
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
理解MapReduce和Yarn:在新版Hadoop中,Yarn作为一个资源管理调度框架,是Hadoop下MapReduce程序运行的生存环境。其实MapRuduce除了可以运行Yarn框架下,也可以运行在诸如Mesos,Corona之类的调度框架上,使用不同的调度框架,需要针对Hadoop做不同的适配。(了解YARN见上一篇博客>> http://www.cnblogs.com/1996swg/p/7286490.html )
MapReduce编程
编写在Hadoop中依赖Yarn框架执行的MapReduce程序,并不需要自己开发MRAppMaster和YARNRunner,因为Hadoop已经默认提供通用的YARNRunner和MRAppMaster程序, 大部分情况下只需要编写相应的Map处理和Reduce处理过程的业务程序即可。
编写一个MapReduce程序并不复杂,关键点在于掌握分布式的编程思想和方法,主要将计算过程分为以下五个步骤:
(1)迭代。遍历输入数据,并将之解析成key/value对。
(2)将输入key/value对映射(map)成另外一些key/value对。
(3)依据key对中间数据进行分组(grouping)。
(4)以组为单位对数据进行归约(reduce)。
(5)迭代。将最终产生的key/value对保存到输出文件中。
Java API解析
(1)InputFormat:用于描述输入数据的格式,常用的为TextInputFormat提供如下两个功能:
数据切分: 按照某个策略将输入数据切分成若干个split,以便确定Map Task个数以及对应的split。
为Mapper提供数据:给定某个split,能将其解析成一个个key/value对。
(2)OutputFormat:用于描述输出数据的格式,它能够将用户提供的key/value对写入特定格式的文件中。
(3)Mapper/Reducer: Mapper/Reducer中封装了应用程序的数据处理逻辑。
(4)Writable:Hadoop自定义的序列化接口。实现该类的接口可以用作MapReduce过程中的value数据使用。
(5)WritableComparable:在Writable基础上继承了Comparable接口,实现该类的接口可以用作MapReduce过程中的key数据使用。(因为key包含了比较排序的操作)。
二 单词计数实验
!单词计数文件word
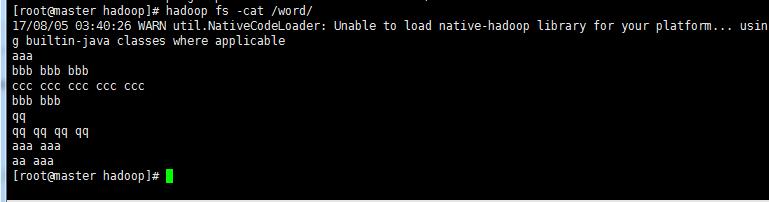
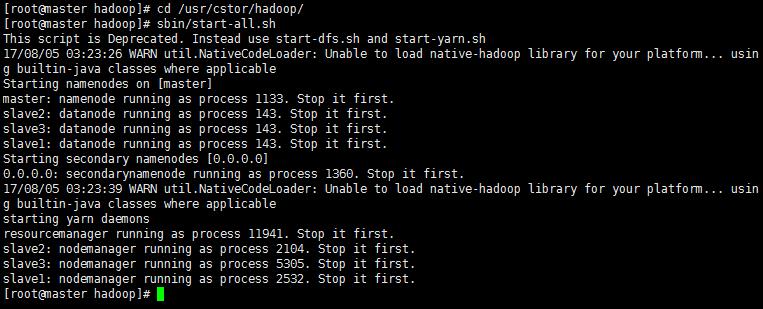
1‘ 启动Hadoop 执行命令启动(前面博客)部署好的Hadoop系统。
命令:
cd /usr/cstor/hadoop/
sbin/start-all.sh
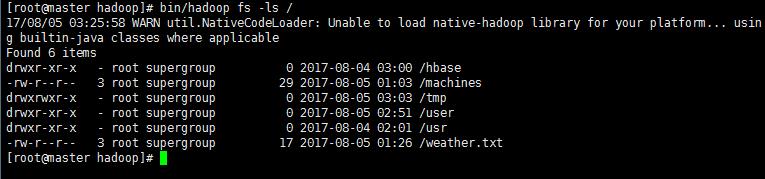
2’ 验证HDFS上没有wordcount的文件夹 此时HDFS上应该是没有wordcount文件夹。
cd /usr/cstor/hadoop/
bin/hadoop fs -ls / #查看HDFS上根目录文件 /
3‘ 上传数据文件到HDFS
cd /usr/cstor/hadoop/
bin/hadoop fs -put /root/data/5/word /

4’ 编写MapReduce程序
在eclipse新建mapreduce项目(方法见博客>> http://www.cnblogs.com/1996swg/p/7286136.html ),新建class类WordCount
主要编写Map和Reduce类,其中Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法;Reduce过程需要继承org.apache.hadoop.mapreduce包中Reduce类,并重写其reduce方法。
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.Mapper; 7 import org.apache.hadoop.mapreduce.Reducer; 8 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 10 import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; 11 12 import java.io.IOException; 13 import java.util.StringTokenizer; 14 15 16 public class WordCount { 17 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { 18 private final static IntWritable one = new IntWritable(1); 19 private Text word = new Text(); 20 //map方法,划分一行文本,读一个单词写出一个<单词,1> 21 public void map(Object key, Text value, Context context)throws IOException, InterruptedException { 22 StringTokenizer itr = new StringTokenizer(value.toString()); 23 while (itr.hasMoreTokens()) { 24 word.set(itr.nextToken()); 25 context.write(word, one);//写出<单词,1> 26 }}} 27 //定义reduce类,对相同的单词,把它们<K,VList>中的VList值全部相加 28 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 29 private IntWritable result = new IntWritable(); 30 public void reduce(Text key, Iterable<IntWritable> values,Context context) 31 throws IOException, InterruptedException { 32 int sum = 0; 33 for (IntWritable val : values) { 34 sum += val.get();//相当于<Hello,1><Hello,1>,将两个1相加 35 } 36 result.set(sum); 37 context.write(key, result);//写出这个单词,和这个单词出现次数<单词,单词出现次数> 38 }} 39 public static void main(String[] args) throws Exception {//主方法,函数入口 40 Configuration conf = new Configuration(); //实例化配置文件类 41 Job job = new Job(conf, "WordCount"); //实例化Job类 42 job.setInputFormatClass(TextInputFormat.class); //指定使用默认输入格式类 43 TextInputFormat.setInputPaths(job, args[0]); //设置待处理文件的位置 44 job.setJarByClass(WordCount.class); //设置主类名 45 job.setMapperClass(TokenizerMapper.class); //指定使用上述自定义Map类 46 job.setCombinerClass(IntSumReducer.class); //指定开启Combiner函数 47 job.setMapOutputKeyClass(Text.class); //指定Map类输出的<K,V>,K类型 48 job.setMapOutputValueClass(IntWritable.class); //指定Map类输出的<K,V>,V类型 49 job.setPartitionerClass(HashPartitioner.class); //指定使用默认的HashPartitioner类 50 job.setReducerClass(IntSumReducer.class); //指定使用上述自定义Reduce类 51 job.setNumReduceTasks(Integer.parseInt(args[2])); //指定Reduce个数 52 job.setOutputKeyClass(Text.class); //指定Reduce类输出的<K,V>,K类型 53 job.setOutputValueClass(Text.class); //指定Reduce类输出的<K,V>,V类型 54 job.setOutputFormatClass(TextOutputFormat.class); //指定使用默认输出格式类 55 TextOutputFormat.setOutputPath(job, new Path(args[1])); //设置输出结果文件位置 56 System.exit(job.waitForCompletion(true) ? 0 : 1); //提交任务并监控任务状态 57 } 58 }
5\' 打包成jar文件上传
假定打包后的文件名为hdpAction.jar,主类WordCount位于包njupt下,则可使用如下命令向YARN集群提交本应用。
./yarn jar hdpAction.jar mapreduce1.WordCount /word /wordcount 1
其中“yarn”为命令,“jar”为命令参数,后面紧跟打包后的代码地址,“mapreduce1”为包名,“WordCount”为主类名,“/word”为输入文件在HDFS中的位置,/wordcount为输出文件在HDFS中的位置。
注意:如果打包时明确了主类,那么在输入命令时,就无需输入mapreduce1.WordCount来确定主类!

结果显示:
1 17/08/05 03:37:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2 17/08/05 03:37:06 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 3 17/08/05 03:37:06 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/08/05 03:37:07 INFO input.FileInputFormat: Total input paths to process : 1 5 17/08/05 03:37:07 INFO mapreduce.JobSubmitter: number of splits:1 6 17/08/05 03:37:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0004 7 17/08/05 03:37:07 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0004 8 17/08/05 03:37:07 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0004/ 9 17/08/05 03:37:07 INFO mapreduce.Job: Running job: job_1501872322130_0004 10 17/08/05 03:37:12 INFO mapreduce.Job: Job job_1501872322130_0004 running in uber mode : false 11 17/08/05 03:37:12 INFO mapreduce.Job: map 0% reduce 0% 12 17/08/05 03:37:16 INFO mapreduce.Job: map 100% reduce 0% 13 17/08/05 03:37:22 INFO mapreduce.Job: map 100% reduce 100% 14 17/08/05 03:37:22 INFO mapreduce.Job: Job job_1501872322130_0004 completed successfully 15 17/08/05 03:37:22 INFO mapreduce.Job: Counters: 49 16 File System Counters 17 FILE: Number of bytes read=54 18 FILE: Number of bytes written=232239 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=166 23 HDFS: Number of bytes written=28 24 HDFS: Number of read operations=6 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=1 29 Launched reduce tasks=1 30 Data-local map tasks=1 31 Total time spent by all maps in occupied slots (ms)=2275 32 Total time spent by all reduces in occupied slots (ms)=2598 33 Total time spent by all map tasks (ms)=2275 34 Total time spent by all reduce tasks (ms)=2598 35 Total vcore-seconds taken by all map tasks=2275 36 Total vcore-seconds taken by all reduce tasks=2598 37 Total megabyte-seconds taken by all map tasks=2329600 38 Total megabyte-seconds taken by all reduce tasks=2660352 39 Map-Reduce Framework 40 Map input records=8 41 Map output records=20 42 Map output bytes=154 43 Map output materialized bytes=54 44 Input split bytes=88 45 Combine input records=20 46 Combine output records=5 47 Reduce input groups=5 48 Reduce shuffle bytes=54 49 Reduce input records=5 50 Reduce output records=5 51 Spilled Records=10 52 Shuffled Maps =1 53 Failed Shuffles=0 54 Merged Map outputs=1 55 GC time elapsed (ms)=47 56 CPU time spent (ms)=1260 57 Physical memory (bytes) snapshot=421257216 58 Virtual memory (bytes) snapshot=1647611904 59 Total committed heap usage (bytes)=402653184 60 Shuffle Errors 61 BAD_ID=0 62 CONNECTION=0 63 IO_ERROR=0 64 WRONG_LENGTH=0 65 WRONG_MAP=0 66 WRONG_REDUCE=0 67 File Input Format Counters 68 Bytes Read=78 69 File Output Format Counters 70 Bytes Written=28
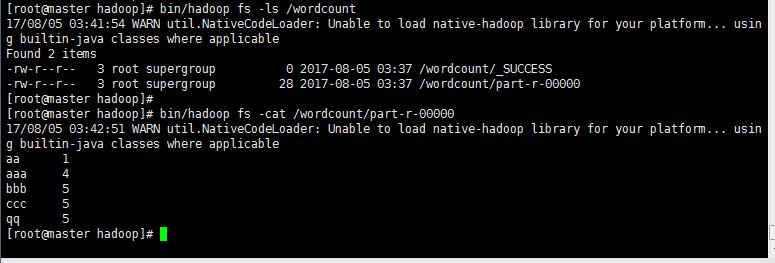
>生成结果文件wordcount目录下的part-r-00000,用hadoop命令查看生成文件
三 二次排序
MR默认会对键进行排序,然而有的时候我们也有对值进行排序的需求。满足这种需求一是可以在reduce阶段排序收集过来的values,但是,如果有数量巨大的values可能就会导致内存溢出等问题,这就是二次排序应用的场景——将对值的排序也安排到MR计算过程之中,而不是单独来做。
二次排序就是首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序,注意不能破坏第一次排序的结果。
!需排序文件secsortdata.txt
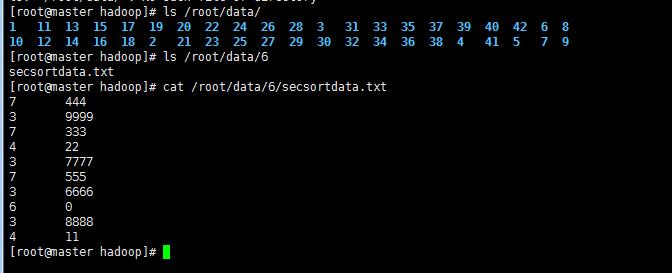
1\' 编写程序IntPair 类和主类 SecondarySort类
同第一个实验在eclipse编程的创建方法!
程序主要难点在于排序和聚合。
对于排序我们需要定义一个IntPair类用于数据的存储,并在IntPair类内部自定义Comparator类以实现第一字段和第二字段的比较。
对于聚合我们需要定义一个FirstPartitioner类,在FirstPartitioner类内部指定聚合规则为第一字段。
此外,我们还需要开启MapReduce框架自定义Partitioner 功能和GroupingComparator功能。
Inpair.java
1 package mr; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.WritableComparable; 9 10 public class IntPair implements WritableComparable<IntPair> { 11 private IntWritable first; 12 private IntWritable second; 13 public void set(IntWritable first, IntWritable second) { 14 this.first = first; 15 this.second = second; 16 } 17 //注意:需要添加无参的构造方法,否则反射时会报错。 18 public IntPair() { 19 set(new IntWritable(), new IntWritable()); 20 } 21 public IntPair(int first, int second) { 22 set(new IntWritable(first), new IntWritable(second)); 23 } 24 public IntPair(IntWritable first, IntWritable second) { 25 set(first, second); 26 } 27 public IntWritable getFirst() { 28 return first; 29 } 30 public void setFirst(IntWritable first) { 31 this.first = first; 32 } 33 public IntWritable getSecond() { 34 return second; 35 } 36 public void setSecond(IntWritable second) { 37 this.second = second; 38 } 39 public void write(DataOutput out) throws IOException { 40 first.write(out); 41 second.write(out); 42 } 43 public void readFields(DataInput in) throws IOException { 44 first.readFields(in); 45 second.readFields(in); 46 } 47 public int hashCode() { 48 return first.hashCode() * 163 + second.hashCode(); 49 } 50 public boolean equals(Object o) { 51 if (o instanceof IntPair) { 52 IntPair tp = (IntPair) o; 53 return first.equals(tp.first) && second.equals(tp.second); 54 } 55 return false; 56 } 57 public String toString() { 58 return first + "\\t" + second; 59 } 60 public int compareTo(IntPair tp) { 61 int cmp = first.compareTo(tp.first); 62 if (cmp != 0) { 63 return cmp; 64 } 65 return second.compareTo(tp.second); 66 } 67 }
secsortdata.java
1 package mr; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.NullWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.io.WritableComparable; 11 import org.apache.hadoop.io.WritableComparator; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.Mapper; 14 import org.apache.hadoop.mapreduce.Partitioner; 15 import org.apache.hadoop.mapreduce.Reducer; 16 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 17 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 18 19 public class SecondarySort { 20 static class TheMapper extends Mapper<LongWritable, Text, IntPair, NullWritable> { 21 @Override 22 protected void map(LongWritable key, Text value, Context context) 23 throws IOException, InterruptedException { 24 String[] fields = value.toString().split("\\t"); 25 int field1 = Integer.parseInt(fields[0]); 26 int field2 = Integer.parseInt(fields[1]); 27 context.write(new IntPair(field1,field2), NullWritable.get()); 28 } 29 } 30 static class TheReducer extends Reducer<IntPair, NullWritable,IntPair, NullWritable> { 31 //private static final Text SEPARATOR = new Text("------------------------------------------------"); 32 @Override 33 protected void reduce(IntPair key, Iterable<NullWritable> values, Context context) 34 throws IOException, InterruptedException { 35 context.write(key, NullWritable.get()); 36 } 37 } 38 public static class FirstPartitioner extends Partitioner<IntPair, NullWritable> { 39 public int getPartition(IntPair key, NullWritable value, 40 int numPartitions) { 41 return Math.abs(key.getFirst().get()) % numPartitions; 42 } 43 } 44 //如果不添加这个类,默认第一列和第二列都是升序排序的。 45 //这个类的作用是使第一列升序排序,第二列降序排序 46 public static class KeyComparator extends WritableComparator { 47 //无参构造器必须加上,否则报错。 48 protected KeyComparator() { 49 super(IntPair.class, true); 50 } 51 public int compare(WritableComparable a, WritableComparable b) { 52 IntPair ip1 = (IntPair) a; 53 IntPair ip2 = (IntPair) b; 54 //第一列按升序排序 55 int cmp = ip1.getFirst().compareTo(ip2.getFirst()); 56 if (cmp != 0) { 57 return cmp; 58 } 59 //在第一列相等的情况下,第二列按倒序排序 60 return -ip1.getSecond().compareTo(ip2.getSecond()); 61 } 62 } 63 //入口程序 64 public static void main(String[] args) throws Exception { 65 Configuration conf = new Configuration(); 66 Job job = Job.getInstance(conf); 67 job.setJarByClass(SecondarySort.class); 68 //设置Mapper的相关属性 69 job.setMapperClass(TheMapper.class); 70 //当Mapper中的输出的key和value的类型和Reduce输出 71 //的key和value的类型相同时,以下两句可以省略。 72 //job.setMapOutputKeyClass(IntPair.class); 73 //job.setMapOutputValueClass(NullWritable.class); 74 FileInputFormat.setInputPaths(job, new Path(args[0])); 75 //设置分区的相关属性 76 job.setPartitionerClass(FirstPartitioner.class); 77 //在map中对key进行排序 78 job.setSortComparatorClass(KeyComparator.class); 79 //job.setGroupingComparatorClass(GroupComparator.class); 80 //设置Reducer的相关属性 81 job.setReducerClass(TheReducer.class); 82 job.setOutputKeyClass(IntPair.class); 83 job.setOutputValueClass(NullWritable.class); 84 FileOutputFormat.setOutputPath(job, new Path(args[1])); 85 //设置Reducer数量 86 int reduceNum = 1; 87 if(args.length >= 3 && args[2] != null){ 88 reduceNum = Integer.parseInt(args[2]); 89 } 90 job.setNumReduceTasks(reduceNum); 91 job.waitForCompletion(true); 92 } 93 }
2’ 打包提交
使用Eclipse开发工具将该代码打包,选择主类为mr.Secondary。如果没有指定主类,那么在执行时就要指定须执行的类。假定打包后的文件名为Secondary.jar,主类SecondarySort位于包mr下,则可使用如下命令向Hadoop集群提交本应用。
bin/hadoop jar hdpAction6.jar mr.Secondary /user/mapreduce/secsort/in/secsortdata.txt /user/mapreduce/secsort/out 1
其中“hadoop”为命令,“jar”为命令参数,后面紧跟打的包,/user/mapreduce/secsort/in/secsortdata.txt”为输入文件在HDFS中的位置,如果HDFS中没有这个文件,则自己自行上传。“/user/mapreduce/secsort/out/”为输出文件在HDFS中的位置,“1”为Reduce个数。
如果打包时已经设定了主类,此时命令中无需再次输入定义主类!
(上传secsortdata.txt到HDFS 命令: ” hadoop fs -put 目标文件包括路径 hdfs路径 “)
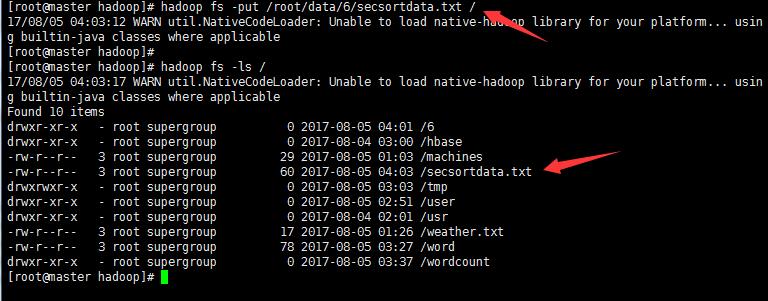
显示结果:
1 [root@master hadoop]# bin/hadoop jar SecondarySort.jar /secsortdata.txt /user/mapreduce/secsort/out 1 2 Not a valid JAR: /usr/cstor/hadoop/SecondarySort.jar 3 [root@master hadoop]# bin/hadoop jar hdpAction6.jar /secsortdata.txt /user/mapreduce/secsort/out 1 4 17/08/05 04:05:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 5 17/08/05 04:05:49 INFO client.RMProxy: Connecting to ResourceManager at master/10.1.21.27:8032 6 17/08/05 04:05:49 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 7 17/08/05 04:05:50 INFO input.FileInputFormat: Total input paths to process : 1 8 17/08/05 04:05:50 INFO mapreduce.JobSubmitter: number of splits:1 9 17/08/05 04:05:50 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1501872322130_0007 10 17/08/05 04:05:50 INFO impl.YarnClientImpl: Submitted application application_1501872322130_0007 11 17/08/05 04:05:50 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1501872322130_0007/ 12 17/08/05 04:05:50 INFO mapreduce.Job: Running job: job_1501872322130_0007 13 17/08/05 04:05:56 INFO mapreduce.Job: Job job_1501872322130_0007 running in uber mode : false 14 17/08/05 04:05:56 INFO mapreduce.Job: map 0% reduce 0% 15 17/08/05 04:06:00 INFO mapreduce.Job: map 100% reduce 0% 16 17/08/05 04:06:05 INFO mapreduce.Job: map 100% reduce 100% 17 17/08/05 04:06:06 INFO mapreduce.Job: Job job_1501872322130_0007 completed successfully 18 17/08/05 04:06:07 INFO mapreduce.Job: Counters: 49 19 File System Counters 20 FILE: Number of bytes read=106 21 FILE: Number of bytes written=230897 22 FILE: Number of read operations=0 23 FILE: Number of large read operations=0 24 FILE: Number of write operations=0 25 HDFS: Number of bytes read=159 26 HDFS: Number of bytes written=60 27 HDFS: Number of read operations=6 28 HDFS: Number of large read operations=0 29 HDFS: Number of write operations=2 30 Job Counters 31 Launched map tasks=1 32 Launched reduce tasks=1 33 Data-lo以上是关于大数据MapReduce(单词计数;二次排序;计数器;join;分布式缓存)的主要内容,如果未能解决你的问题,请参考以下文章