卷积神经网络笔记--吴恩达深度学习课程笔记
Posted 无乎648
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络笔记--吴恩达深度学习课程笔记相关的知识,希望对你有一定的参考价值。
各个知识点详解
LeNet-5网络

LetNet网络的的讲解主要参考1998年计算机科学家Yann LeCun发布的一篇论文《Gradient based learning applied to document-recognition》大家可以找到这篇论文结合学习,针对该网络,首先大家需要了解一下图像中的常用操作卷积,卷积这个词是信号处理领域的词,表示一个系统多数据处理的过程,在图像处理中的卷积,其实就是滤波器。下面先简要介绍一下卷积核的概念,这个不能细说,因为想要深入理解卷积需要很多知识,这里只给大家一个直观的概念,随着我们后面的不断深入,在优化时在讨论卷积核如何设置。

输入层
– 32*32的图片,也就是相当于1024个神经元
C1层(卷积层)
选择6个5 * 5的卷积核,得到6个大小为32-5+1=28的特征图,也就是神经元的个数为6 * 28 * 28=4704
我们从图中可以看到这里有6个特征平面(这里不应该称为卷积核,卷积核是滑动窗口,通过卷积核提取特征的结果叫特征平面),得到的每个特征平面使用的一个5x5的卷积核(这里说明窗口滑动的权值就是卷积核的内容,这里需要注意的是特征平面有6个说明有6个不同的卷积核,因此每个特征平面所使用的权值都是一样的,这样就得到了特征平面。那么特征平面有多少神经元呢?如下图,32x32通过一个5x5的卷积核运算,根据局部连接和平滑,需要每次移动1,因此从左移动到右时是28,因此特征平面是28x28的,即每个特征平面有28x28个神经元。如下图,权值共享就是右边的神经元的权值都是w,这里大家需要好好理解,还是在解释一下,6个特征平面对应6个不同的卷积核或者6个滤波器,每个滤波器的参数值也就是权值都是一样的,下图就是卷积对应的一个特征平面,这样的平面有6个,即卷积层有6个特征平面。
S2层(下采样层)
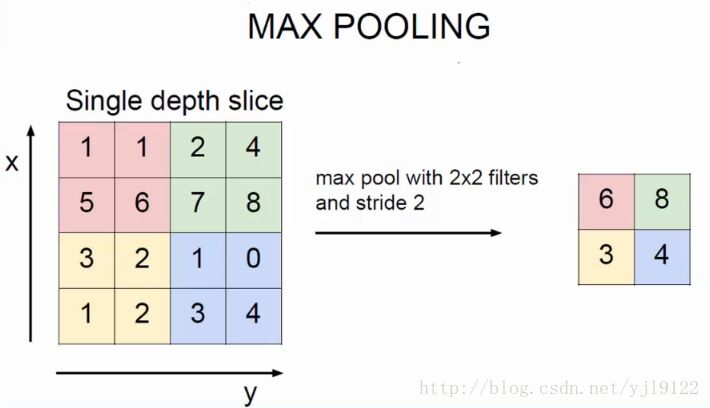
– 每个下抽样节点的4个输入节点求和后取平均(平均池化),均值乘上一个权重参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。池化核大小选择2 * 2,得到6个14 * 14大小特征图
池化层又叫下采样层,目的是压缩数据,降低数据维度,如下图所示,他和卷积有明显的区别,这里采样2x2的选择框进 行压缩,如何压缩呢,通过选择框的数据求和再取平均值然后在乘上一个权值和加上一个偏置值,组成一个新的图片,每个特征平面采样的权值和偏置值都是一样的,因此每个特征平面对应的采样层只两个待训练的参数。如下图4x4的图片经过采样后还剩2x2,直接压缩了4倍。本层具有激活函数,为sigmod函数,而卷积层没有激活函数。
对于激活函数,主要作用是防止线性化,因为每次卷积的目的就是为了是每次的输出结果不同,不同越深的卷积层那么输出的特征图也更加明显,但是如果没有激活函数,那么多次的输出特征图都可以用一层卷积来代替,那么这就与深度学习的思想相违背,为了非线性而选择出来了不同的激活函数,每个激活函数的作用也不相同,博主列出了几个激活函数如下:


C3层(卷积层)
– 用5*5的卷积核对S2层输出的特征图进行卷积后,得到6张10 * 10新 图片,然后将这6张图片相加在一起,然后加一个偏置项b,然后用 激活函数进行映射,就可以得到1张10 * 10的特征图。我们希望得到 16 张 10 * 10 的 特 征 图 , 因 此 我 们 就 需 要 参 数 个 数 为 16 * (6 * ( 5 * 5))=16 * 6 * (5 * 5)个参数
S4层(下采样层)
– 对C3的16张1010特征图进行最大池化,池化核大小为22,得到16
张大小为55的特征图。神经元个数已经减少为:165*5=400
C5层(卷积层)
– 用5*5的卷积核进行卷积,然后我们希望得到120个特征图,特征图大小为5-5+1=1。神经元个数为120
F6层(全连接层)
– 有84个节点,该层的训练参数和连接数都是(120+1)x84=10164
Output层
– 共有10个节点,分别代表数字0到9,如果节点 i 的输出值为0,则网络识别的结果是数字。
AlexNet
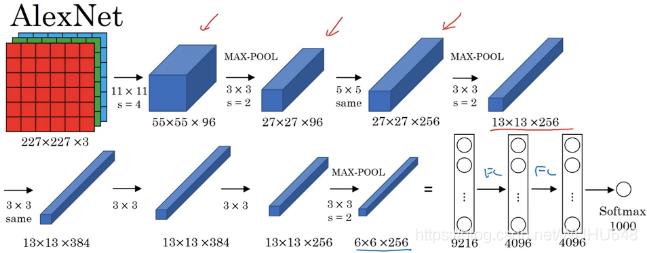
AlexNet模型有5层卷积,去掉任意一层都会使结果不好,所以这个网络的深度似乎是很重要的,这样的话难免引起我们的思考,记得不知道哪位大神在一篇论文中证明了,神经网络可以模拟任意多项式,只要神经元数量足够多,并且和深度关系不大。但这里的实验却表示深度会对网络的性能有影响。

第一层:卷积层1
输入为 224 × 224 × 3 224 \\times 224 \\times 3224×224×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11 × 11 × 3 stride = 4, stride表示的是步长, pad = 0, 表示不扩充边缘;
卷积后的图形大小是怎样的呢?
wide = (224 + 2 * padding - kernel_size) / stride + 1 = 54
height = (224 + 2 * padding - kernel_size) / stride + 1 = 54
dimention = 96
然后进行 (Local Response Normalized), 后面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map
最终第一层卷积的输出为
第二层:卷积层2,
输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:5 × 5 × 48 ; pad = 2, stride = 1; 然后做 LRN, 最后 max_pooling, pool_size = (3, 3), stride = 2;
第三层:卷积3
输入为第二层的输出,卷积核个数为384, kernel_size = (3 × 3 × 256), padding = 1, 第三层没有做LRN和Pool
第四层:卷积4
输入为第三层的输出,卷积核个数为384, kernel_size = (3 × 3), padding = 1, 和第三层一样,没有LRN和Pool
第五层:卷积5,
输入为第四层的输出,卷积核个数为256, kernel_size = (3 × 3), padding = 1。然后直接进行max_pooling, pool_size = (3, 3), stride = 2;
第6,7,8层是全连接层
每一层的神经元的个数为4096,最终输出softmax为1000,因为上面介绍过,ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
其中我们会发现AlexNet最后三层全连接层是4096–>4096–>1000,为什么其中4096到4096大小没有任何优化呢,其实这之间的转换主要是因为最后卷积出来的4096个特征值但是这个些特征值是无序的,但是最后一些特征值是需要合并提取的,所以4096到4096主要是对特征值进行一些排序。
VGG
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
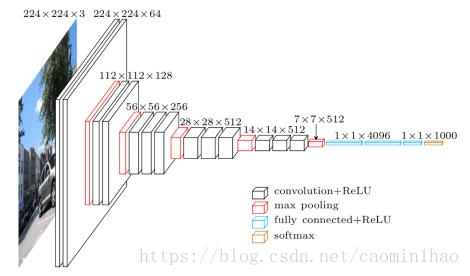
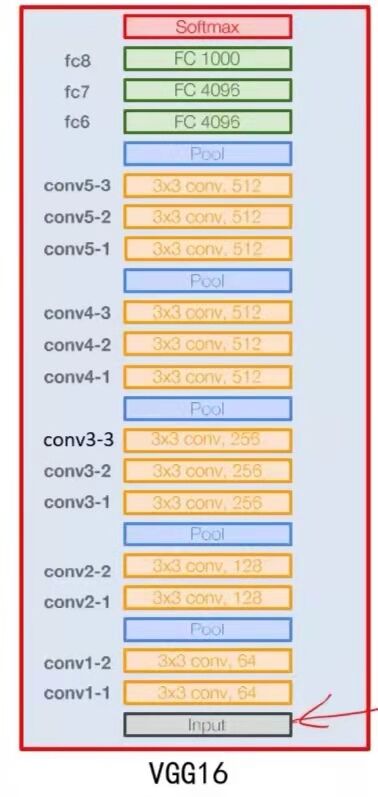
Input Layer:224 * 224 * 3图像
Conv1-1 Layer:包含64个卷积核,kernal size:333,stride:1,padding:1
输入图像:224*224*3
卷积后大小:224*224*64
Conv1-2 Layer:包含64个卷积核,kernal size:3 * 3 * 64,stride:1,padding:1
输入图像:224*224*64
卷积后大小:224*224*64
Pool1 Layer:包含64个卷积核,kernal size:2 * 2,stride:2,padding:0
输入图像:224*224*64
卷积后大小:112*112*64
Conv2-1Layer:包含128个卷积核,kernal size:3 *3 *64,stride:1,padding:1
输入图像: 112*112*64
卷积后大小:112*112*128
Conv2-2 Layer:包含128个卷积核,kernal size:3 *3 *128,stride:1,padding:1
输入图像: 112*112*128
卷积后大小:112*112*128
Pool2 Layer:包含128个卷积核,kernal size:2 * 2,stride:2,padding:0
输入图像: 112*112*128
卷积后大小:56*56*128
Conv3-1 Layer:包含256个卷积核,kernal size:3 *3 *128,stride:1,padding:1
输入图像大小:56*56*128
卷积后大小:56*56*256
Conv3-2Layer:包含256个卷积核,kernal size:3 *3 *256,stride:1,padding:1
输入图像大小:56*56*256
卷积后大小:56*56*256
Conv3-3 Layer:包含256个卷积核,kernal size:3 *3 *256,stride:1,padding:1
输入图像大小:56*56*256
卷积后大小:56*56*256
Pool3 Layer:包含256个卷积核,kernal size:2 *2,stride:2,padding:0
输入图像大小:56*56*256
卷积后大小:28*28*256
Conv4-1 Layer:包含512个卷积核,kernal size:3 *3 *256,stride:1,padding:1
输入图像大小:28*28*256
卷积后大小:28*28*512
Conv4-2 Layer:包含512个卷积核,kernal size:3 *3 *512,stride:1,padding:1
输入图像大小:28*28*512
卷积后大小:28*28*512
Conv4-3 Layer:包含512个卷积核,kernal size:3 *3 *512,stride:1,padding:1
输入图像大小:28*28*512
卷积后大小:28*28*512
Pool4 Layer:包含512个卷积核,kernal size:2 *2,stride:2,padding:0
输入图像大小:28*28*512
卷积后大小:14*14*512
Conv5-1 Layer:包含512个卷积核,kernal size:3 *3 *512,stride:1,padding:1
输入图像大小:14*14*512
卷积后大小:14*14*512
Conv5-2 Layer:包含512个卷积核,kernal size:3 * 3 *512,stride:1,padding:1
输入图像大小:14*14*512
卷积后大小:14*14*512
Conv5-3 Layer:包含512个卷积核,kernal size:3 *3 *512,stride:1,padding:1
输入图像大小:14*14*512
卷积后大小:14*14*512
Pool5 Layer:包含512个卷积核,kernal size:2 *2,stride:2,padding:0
输入图像大小:14*14*512
卷积后大小:7*7*512
FullConect Layer1:这里用1*1卷积核,包含4096个卷积核,
FullConect Layer2:这里用1*1卷积核,包含4096个卷积核,
FullConect Layer3:这里用1*1卷积核,包含4096个卷积核,
第1层:1792 = 3*3*3*64+64
第2层:36928 = 3*3*64*64+64
第3层:73856 = 3*3*64*128+128
第4层:147584 = 3*3*128128+128
第5层:295168 = 33128256+256
第6层:590080 = 3*3*256*256+256
第7层:590080 = 3*3*256*256+256
第8层:1180160 = 3*3*256*512+512
第9层:2359808 = 3*3*512*512+512
第10层:2359808 = 3*3*512*512+512
第11层:2359808 = 3*3*512*512+512
第12层:2359808 = 3*3*512*512+512
第13层:2359808 = 3*3*512*512+512
第14层:102764544 = 7*7*512*4096+4096
第15层:16781312 = 4096*4096+4096
第16层:4097000 = 4096*1000+1000
总计:138357544个 (138M)
VGG优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
验证了通过不断加深网络结构可以提升性能。
VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
相关知识

对于感受野,博主的理解就想上图中上方的特征图3 * 3通过卷积核与中方特征图的1 * 1相对应,那么中方的特征图的1 * 1的感受野就是上方特征图的3 * 3。
下面我们通过计算发现(步长为1)
一个3 * 3的卷积核后的1 * 1感受野等于3 * 3,
两个3 * 3的卷积核后的1 * 1感受野等于5 * 5,
三个3 * 3的卷积核后的1 * 1感受野等于7 * 7,
…
一个5 * 5的卷积核后的1 * 1感受野等于5 * 5,
两个5 * 5的卷积核后的1 * 1感受野等于7 * 7,
三个5 * 5的卷积核后的1 * 1感受野等于9 * 9,
…
以此类推,我们可以发现一个规律,一个5 * 5的卷积核的感受野等于两个3 * 3的卷积核的感受野,一个7 * 7的卷积核的感受野等于两个5 * 5的卷积核的感受野等于四个3 * 卷积核的感受野…
既然不同大小的卷积核可以互相等价,那为什么不同的卷积层还要使用不同的卷积核呢,下面我们来谈谈不同卷积核之间的差异:
首先我们先计算一下当输入特征图和输出特征图大小一样的情况下对于不同的卷积核所需要计算的参数数量的比较
28 * 28 *192 -----(32个5 * 5 same)----> 28 * 28 *32
计算所用到的参数 28×28×32×5×5×192≈12亿
28 * 28 192 -----(16个 1 1 * 192)----> 28 * 28 * 16 -----(32个 5 * 5 * 16)----> 28 * 28 * 32
计算所用到的参数 28×28×16×192≈0.24亿, 28×28×32×5×5×16≈1亿,1+0.24=1.24亿
通过比较12亿和1.24亿,发现先用越小的卷积核可以使运算的参数数量大大减少,这也就是VGG选用所有的卷积核是3×3的原因
说明越小的卷积核效果越好,但是大卷积核就没有好处了吗,对于AlexNet中,第一个卷积层就是使用的11×11的大卷积核,下面我们看看大卷积核有什么作用。
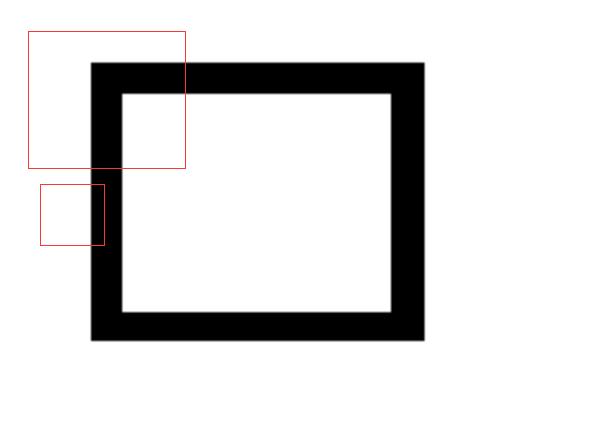
上图是一个黑色边框的矩形,这个矩形的边框比较粗,旁边有两个红色的卷积核,我们会发现,小卷积核在进行卷积的时候由于太小不能完全包括边框,这样回导致小卷积核识别出来的是两个边缘,一个内边缘一个外边缘,如果我们进行矩形数量的识别,那么这样就会导致识别出来了两个矩形,这就导致了识别失误,而对于大卷积核,因为可以完全包括住边框,这样才能正确的识别出来矩形的个数。
Inception网络
Inception模块的作用:代替人工确定卷积层中的卷积核大小或者确定是否需要创建卷积层和池化层。即不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。因此可以使计算量大大减少,收敛更快。

由于使用Inception模块的计算量还是比较多的,上图中的网络是1.2亿次,所以可以在中间添加瓶颈层来减少运算量。下图的运算量为1240万次,约为上面运算量的十分之一。
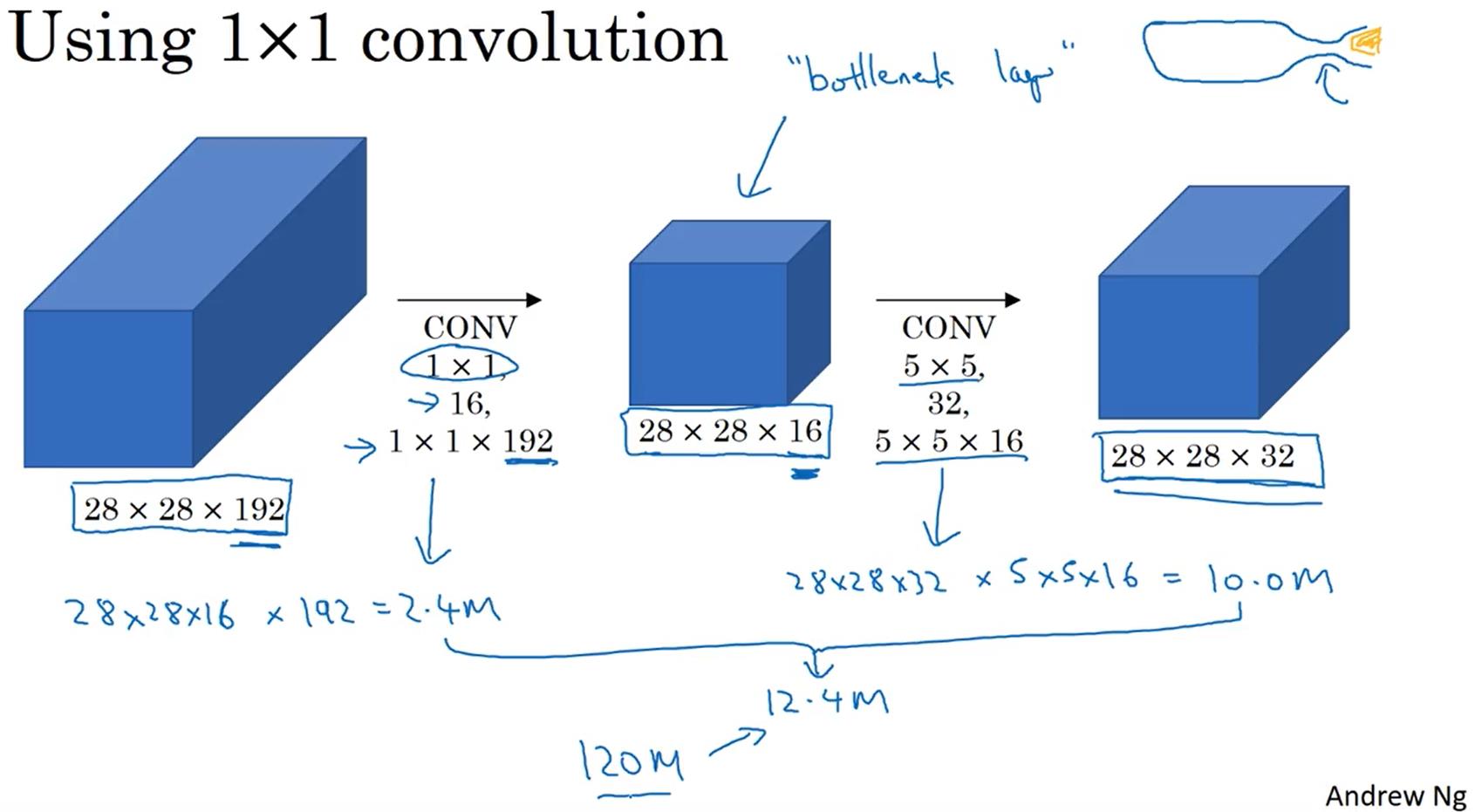
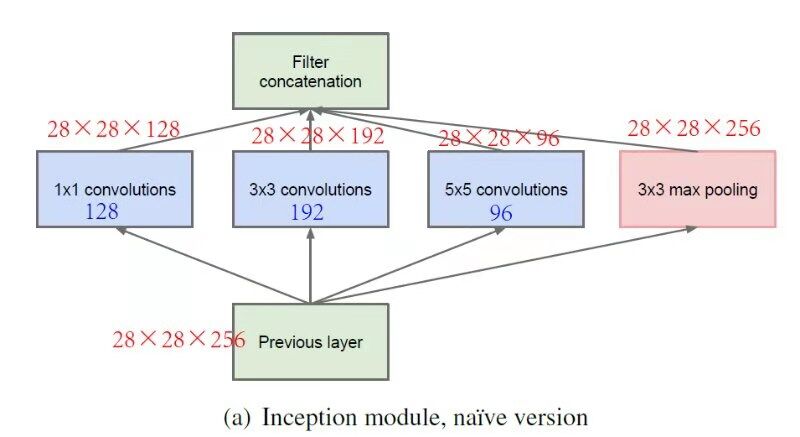
下图就是一个Inception模块,一个Inception模块可能由很多不同的卷积核甚至池化层构成,它们都要采用same卷积方式,这样最后的输出才可以拼接在一起,为了避免池化层的通道数过多,在池化层后面还加上了一个1*1的卷积核来减少通道数。

下图是一个Inception神经网络,我们可以看到在下面的网络中有很多分支,这些分支的作用就是通过隐藏层来做出预测。它确保了即便是隐藏单元和中间层也参与了特征计算,它们也能预测图片的分类,它在Inception网络中起到了一种调整的效果,并且能够防止网络发生过拟合。

以上是关于卷积神经网络笔记--吴恩达深度学习课程笔记的主要内容,如果未能解决你的问题,请参考以下文章