Hadoop2源码分析-序列化篇
Posted 张松任
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop2源码分析-序列化篇相关的知识,希望对你有一定的参考价值。
1.概述
上一篇我们了解了MapReduce的相关流程,包含MapReduce V2的重构思路,新的设计架构,与MapReduce V1的区别等内容,今天我们在来学习下在Hadoop V2中的序列化的相关内容,其目录如下所示:
- 序列化的由来
- Hadoop序列化依赖图详解
- Writable常用实现类
下面,我们开始学习今天的内容。
2.序列化的由来
我们知道Java语言对序列化提供了非常友好的支持,在定义一个类时,如果我们需要序列化一个类,只需要实现该类的序列化接口即可。场景:让一个AppInfo类能够被序列化,代码如下所示:

/**
*
*/
package cn.hdfs.io;
import java.io.Serializable;
/**
* @author dengjie
* @date Apr 21, 2015
* @description 定义一个可序列化的App信息类
*/
public class AppInfo implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
}
这么定义,不需要其他的操作,Java会自动的处理各种对象关系。虽然,Java的序列化接口易于实现且内建支持,同样,它的不足之处也是暴露无遗,它占用空间过大,额外的开销导致速度降低。这些缺点对于Hadoop来说是不合适的,导致Hadoop没有采用Java自身的序列化机制,而是Hadoop自己开发了一套适合自己的序列化机制。
由于 Hadoop 的 MapReduce 和 HDFS 都有通信的需求,需要对通信的对象进行序列化。而且,Hadoop本身需要序列化速度要快,体积要小,占用带宽低等要求。因此,了解Hadoop的序列化过程是很有必要的,下面我们对Hadoop的序列化内容做进一步学习研究。
注:本文不对Java的Serializable接口做详细赘述,若需了解 ,请参考官方文档:http://docs.oracle.com/javase/7/docs/api/java/io/Serializable.html
3.Hadoop序列化依赖图详解
在Hadoop的序列化机制中,org.apache.hadoop.io 中定义了大量的可序列化对象,他们都实现了 Writable 接口,Writable接口中有两个方法,如下所示:
-
write:将对象写入字节流。
-
readFields:从字节流中解析出对象。
Writeable源码如下所示:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* A serializable object which implements a simple, efficient, serialization
* protocol, based on {@link DataInput} and {@link DataOutput}.
*
* <p>Any <code>key</code> or <code>value</code> type in the Hadoop Map-Reduce
* framework implements this interface.</p>
*
* <p>Implementations typically implement a static <code>read(DataInput)</code>
* method which constructs a new instance, calls {@link #readFields(DataInput)}
* and returns the instance.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritable implements Writable {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public static MyWritable read(DataInput in) throws IOException {
* MyWritable w = new MyWritable();
* w.readFields(in);
* return w;
* }
* }
* </pre></blockquote></p>
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface Writable {
/**
* Serialize the fields of this object to <code>out</code>.
*
* @param out <code>DataOuput</code> to serialize this object into.
* @throws IOException
*/
void write(DataOutput out) throws IOException;
/**
* Deserialize the fields of this object from <code>in</code>.
*
* <p>For efficiency, implementations should attempt to re-use storage in the
* existing object where possible.</p>
*
* @param in <code>DataInput</code> to deseriablize this object from.
* @throws IOException
*/
void readFields(DataInput in) throws IOException;
}
下面我们来看看Hadoop序列化的依赖图关系,如下图所示:
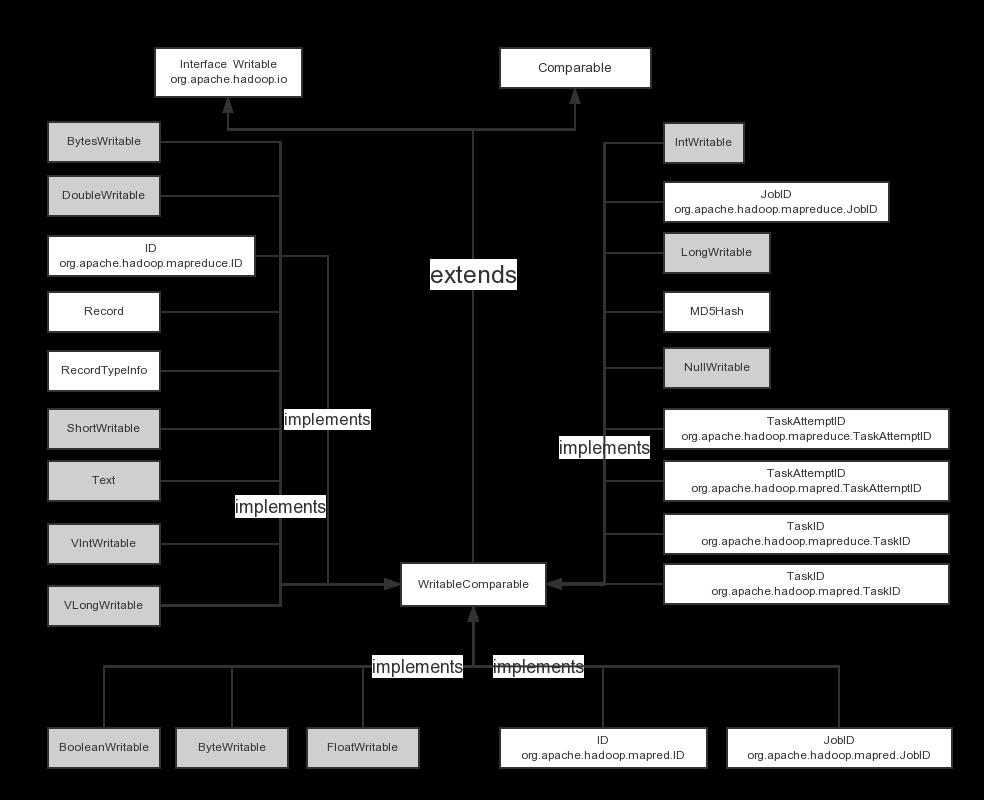
从上图我们可以看出,WritableComparable接口同时继承了Writable和Comparable接口。
WritableComparable源码如下所示:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.io;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* A {@link Writable} which is also {@link Comparable}.
*
* <p><code>WritableComparable</code>s can be compared to each other, typically
* via <code>Comparator</code>s. Any type which is to be used as a
* <code>key</code> in the Hadoop Map-Reduce framework should implement this
* interface.</p>
*
* <p>Note that <code>hashCode()</code> is frequently used in Hadoop to partition
* keys. It\'s important that your implementation of hashCode() returns the same
* result across different instances of the JVM. Note also that the default
* <code>hashCode()</code> implementation in <code>Object</code> does <b>not</b>
* satisfy this property.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritableComparable implements WritableComparable<MyWritableComparable> {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public int compareTo(MyWritableComparable o) {
* int thisValue = this.value;
* int thatValue = o.value;
* return (thisValue < thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
* }
*
* public int hashCode() {
* final int prime = 31;
* int result = 1;
* result = prime * result + counter;
* result = prime * result + (int) (timestamp ^ (timestamp >>> 32));
* return result
* }
* }
* </pre></blockquote></p>
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
接着我们再来看看Comparable的源码,代码如下所示:
package java.lang;
import java.util.*;
public interface Comparable<T> {
public int compareTo(T o);
}
通过源码的阅读,我们可以发现,Java的API提供的Comparable接口,它只有一个方法,就是compareTo,该方法用于比较两个对象。
上图中列举了Hadoop序列化接口中的所有类型,这里我们主要研究一些常用的实现类,如IntWriteable,Text,LongWriteable等。
4.Writable常用实现类
首先我们来看看IntWriteable和LongWriteable的源码,具体代码如下所示:
- IntWriteable
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for ints. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class IntWritable implements WritableComparable<IntWritable> {
private int value;
public IntWritable() {}
public IntWritable(int value) { set(value); }
/** Set the value of this IntWritable. */
public void set(int value) { this.value = value; }
/** Return the value of this IntWritable. */
public int get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(value);
}
/** Returns true iff <code>o</code> is a IntWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
return false;
IntWritable other = (IntWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value;
}
/** Compares two IntWritables. */
@Override
public int compareTo(IntWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
@Override
public String toString() {
return Integer.toString(value);
}
/** A Comparator optimized for IntWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(IntWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int thisValue = readInt(b1, s1);
int thatValue = readInt(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
}
static { // register this comparator
WritableComparator.define(IntWritable.class, new Comparator());
}
}
- LongWritable
package org.apache.hadoop.io;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/** A WritableComparable for longs. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class LongWritable implements WritableComparable<LongWritable> {
private long value;
public LongWritable() {}
public LongWritable(long value) { set(value); }
/** Set the value of this LongWritable. */
public void set(long value) { this.value = value; }
/** Return the value of this LongWritable. */
public long get() { return value; }
@Override
public void readFields(DataInput in) throws IOException {
value = in.readLong();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(value);
}
/** Returns true iff <code>o</code> is a LongWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof LongWritable))
return false;
LongWritable other = (LongWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return (int)value;
}
/** Compares two LongWritables. */
@Override
public int compareTo(LongWritable o) {
long thisValue = this.value;
long thatValue = o.value;
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
@Override
public String toString() {
return Long.toString(value);
}
/** A Comparator optimized for LongWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(LongWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
long thisValue = readLong(b1, s1);
long thatValue = readLong(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
}
/** A decreasing Comparator optimized for LongWritable. */
public static class DecreasingComparator extends Comparator {
@Override
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
static { // register default comparator
WritableComparator.define(LongWritable.class, new Comparator());
}
}
从源码IntWritable和LongWriteable中可以看到,两个类中都包含内部类Comparator,该类的作用是用来支持在没有反序列化的情况下直接对数据进行处理。源码中的compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)方法不需要创建IntWritable对象,效率比compareTo(Object o)高。
- Text
Text的源码大约有670多行,这里就不贴了,若大家要阅读详细的Text源码,请在Hadoop的org.apache.hadoop.io的包下,找到Text类进行阅读,下面只截取Text的部分源码,部分源码如下:
@Stringable
@InterfaceAudience.Public
@InterfaceStability.Stable
public class Text extends BinaryComparable
implements WritableComparable<BinaryComparable> {
// 详细代码省略......
}
从源码中看出,Text继承类BinaryComparable基类,并实现了WritableComparable<BinaryComparable>接口,WritableComparable在上面已赘述过了,下面我们来分析一下BinaryComparable,首先我们来查看一下BinaryComparable的源码,部分源码如下所示:
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class BinaryComparable implements Comparable<BinaryComparable> {
// 详细代码省略......
}
我们发现BinaryComparable(实现了Comparable接口)是一个抽象类,由该抽象类的子类去实现了Hadoop二进制的序列化。该抽象类中有两个compareTo方法,代码如下所示:
/**
* Compare bytes from {#getBytes()}.
* @see org.apache.hadoop.io.WritableComparator#compareBytes(byte[],int,int,byte[],int,int)
*/
@Override
public int compareTo(BinaryComparable other) {
if (this == other)
return 0;
return WritableComparator.compareBytes(getBytes(), 0, getLength(),
other.getBytes(), 0, other.getLength());
}
/**
* Compare bytes from {#getBytes()} to those provided.
*/
public int compareTo(byte[] other, int off, int len) {
return WritableComparator.compareBytes(getBytes(), 0, getLength(),
other, off, len);
}
从代码中,我们可以看出,两个compareTo方法中依赖WritableComparator的静态方法compareBytes来完成二进制数据的比较。另外,从Text类的注视中可以看出,Text是基于UTF-8编码的Writeable类,注视内容如下所示:
/** This class stores text using standard UTF8 encoding. It provides methods * to serialize, deserialize, and compare texts at byte level. The type of * length is integer and is serialized using zero-compressed format. <p>In * addition, it provides methods for string traversal without converting the * byte array to a string. <p>Also includes utilities for * serializing/deserialing a string, coding/decoding a string, checking if a * byte array contains valid UTF8 code, calculating the length of an encoded * string. */
一般来说,在开发Hadoop项目时,我们认为它等价于Java的String类型,即java.lang.String。
5.总结
通过本篇博客的学习,我们对Hadoop的序列化有了较深的认识,对IntWriteable,LongWriteable,Text等实现类也有所了解,这对我们在经后开发Hadoop项目,编写相应的MR作业是有所帮助的。在类型的选择上,我们是可以做到心中有数的。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
以上是关于Hadoop2源码分析-序列化篇的主要内容,如果未能解决你的问题,请参考以下文章