Oracle ORA-01555 快照过旧 说明
Posted lclc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle ORA-01555 快照过旧 说明相关的知识,希望对你有一定的参考价值。
ORA-01555 快照过旧,是数据库中很常见的一个错误,比如当我们的事务需要使用undo来构建CR块的时候,而此时对应的undo 已经不存在了, 这个时候就会报ORA-01555的错误。
有关CR 块,参考我的Blog:
CR (consistent read) blocks create 说明
http://blog.csdn.net/xujinyang/article/details/6823237
老熊Blog上的一个链接:
http://www.laoxiong.net/ora-1555-case.html
ORA-01555错误在Oracle 8i及之前的版本最多。从9i开始的undo自动管理,至现在的10g、11g中的undo auto tuning,使得ORA-01555的错误越来越少。但是这个错误,仍然不可避免。
1. 出现ORA-01555错误,通常有2种情况:
(1)SQL语句执行时间太长,或者UNDO表空间过小,或者事务量过大,或者过于频繁的提交,导致执行SQL过程中进行一致性读时,SQL执行后修改的前镜像(即UNDO数据)在UNDO表空间中已经被覆盖,不能构造一致性读块(CR blocks)。 这种情况最多。
(2)SQL语句执行过程中,访问到的块,在进行延迟块清除时,不能确定该块的事务提交时间与SQL执行开始时间的先后次序。 这种情况很少。
2. 第1种情况解决的办法:
(1)增加UNDO表空间大小
(2)增加undo_retention 时间,默认只有15分钟
(3)优化出错的SQL,减少查询的时间,首选方法
(4)避免频繁的提交
有关Undo 的更多信息,参考我的Blog:
Oracle undo 表空间管理
http://blog.csdn.net/xujinyang/article/details/6822968
3. 第二种情况描述
在块清除过程中,如果一个块已被修改,下一个会话访问这个块时,可能必须查看最后一个修改这个块的事务是否还是活动的。一旦确定该事务不再活动,就会完成块清除,这样另一个会话访问这个块时就不必再历经同样的过程。
要完成块清除,Oracle 会从块首部确定前一个事务所用的undo 段(ITL),然后确定从undo 首部能不能看出这个块是否已经提交。
可以用以下两种方式完成这种确认:
一种方式是Oracle 可以确定这个事务很久以前就已经提交,它在undo 段事务表中的事务槽已经被覆盖。
另一种情况是COMMIT SCN 还在undo 段的事务表中,这说明事务只是稍早前刚提交,其事务槽尚未被覆盖。
当满足以下条件时,就会从defered clean 收到ORA-01555的错误:
首先做了一个修改并COMMIT,块没有自动清理(即没有自动完成“提交清除”,例如修改了太多的块,在SGA 块缓冲区缓存的10%中放不下)。
其他会话没有接触这些块,而且在我们这个“倒霉”的查询(稍后显示)命中这些块之前,任何会话都不会接触它们。
开始一个长时间运行的查询。这个查询最后会读其中的一些块。这个查询从SCN t1 开始,这就是读一致SCN,必须将数据回滚到这一点来得到读一致性。
开始查询时,上述修改事务的事务条目还在undo 段的事务表中。查询期间,系统中执行了多个提交。执行事务没有接触执行已修改的块(如果确实接触到,也就不存在问题了)。
由于出现了大量的COMMIT,undo 段中的事务表要回绕并重用事务槽(ITL)。最重要的是,将循环地重用原来修改事务的事务条目。另外,系统重用了undo 段的区段,以避免对undo段首部块本身的一致读。
此外,由于提交太多,undo 段中记录的最低SCN 现在超过了t1(高于查询的读一致SCN)。如果查询到达某个块,而这个块在查询开始之前已经修改并提交,就会遇到麻烦。正常情况下,会回到块所指的undo 段,找到修改了这个块的事务的状态(换句话说,它会找到事务的COMMIT SCN)。
如果这个COMMIT SCN 小于t1,查询就可以使用这个块。如果该事务的COMMIT SCN 大于t1,查询就必须回滚这个块。不过,问题是,在这种特殊的情况下,查询无法确定块的COMMIT SCN 是大于还是小于t1。相应地,不清楚查询能否使用这个块映像。这就导致了ORA-01555 错误。
大批量的UPDATE 或INSERT 会导致块清除(block cleanout),所以在大批量UPDATE 或大量加载之后使用DBMS_STATS收集相关对象的统计信息,加载之后完成这些对象的清理。
关于块清除这块,在<Oracle 10g 编程艺术> 一书中有更详细的说明。
老熊blog上关于defered Clean的场景说明:
(1)有事务大量修改了A表的数据,或者A表的数据虽然被事务少量修改,但是一部分修改过的块已经刷出内存并写到了磁盘上。随即事务提交,提交时刻为SCN1。而提交时有数据块上的事务没有被清除。
(2)在SCN2时刻,开始执行SELECT查询A表,对A表进行全表扫描,而且A表很大。也可能是其他情况,比如是小表,但是是一个游标方式的处理过程,而处理过程中又非常耗时。注意,这里SCN2与SCN1之间可能相隔了很远,从时间上来说,甚至可能有数十天。不管怎么样,这在SCN1至SCN2时间之间,系统中存在大量的事务,使得UNDO表空间的块以及UNDO段头的事务表全部被重用过。
(3)SELECT语句在读A表的一个块时,发现表上有活动事务,这是由于之前的事务没有清除所致。ORACLE根据数据块中ITL的XID检查事务表,这时会有2种情况:
(A)XID对应的事务表中的记录仍然存在并发现事务已经提交,可以得到事务准确的提交SCN(commit scn),称为SCN3,等于SCN1。很显然,由于查询的时刻SCN2晚于事务提交的时刻SCN1,那么不需要构造一致性读块。
(B)XID对应的事务表中的记录已经被重用,这个时候仍然表明表明事务已经被提交。那么这个时候,Oracle没办法准确地知道事务的提交时间,只能记录为这样一个事实,事务提交的SCN小于其UNDO段的事务表中最近一次重用的事务记录的SCN(即这个事务表最老的事务SCN)。这里称这个SCN为SCN4。
(4)SCN4可能远小于SCN2,那是因为事务很早之前就已经提交。也可能SCN4大于SCN2,这是因为SELECT语句执行时间很长,同时又有大量的事务已经将事务表重用。对于后者,很显然,Oracle会认为该事务的提交时间可能在SELECT开始执行之后。这里为什么说可能,是因为ORACLE只能判断出事务是在SCN4之前提交的,并不是就刚好在SCN4提交。而此时,利用UNDO BLOCK进行一致性读数据的构造也很可能失败,因为UNDO BLOCK很可能已经被覆盖,特别是SCN1远小于SCN2的情况下。
在这种情况下,ORA-01555错误就会出现。
对这种由于表上存在未清除的事务,同时导出时间过长,UNDO段头的事务表被全部重用,ORACLE在查询到有未清除事务的块时不能确定事务提交时间是否早于导出(查询)开始时间,报ORA-01555错误。
老熊blog上有2个解决方法,一是提高SQL 性能,另一个是清除表上的事务,即延时块清楚(Defered Clean)。 这个方法也很简单,就是select。
SQL>SELECT /*+ FULL(A) */ COUNT(*) FROM BIG_TABLE A;
SELECT COUNT(*),速度显然大大高于SELECT *,所需的时间也更短,出现ORA-01555错误的可能性就非常低了。
注意:
(1)使用FULL HINT,以避免查询进行索引快速全扫描,而不是对表进行全表扫描。
(2)这里不能为了提高性能而使用PARALLEL(并行),测试表明,在表上进行并行查询,以DIRECT READ方式读取表并不会清除掉表上的事务。
如果表过大,SELECT COUNT(*)的时间过长,那么我们可以用下面的代码将表分成多个段,进行分段查询。
/* Formatted on 2011/6/29 19:18:40 (QP5 v5.163.1008.3004) */
SELECT DBMS_ROWID.rowid_create (1,
oid1,
fid1,
bid1,
0)
rowid1,
DBMS_ROWID.rowid_create (1,
oid2,
fid2,
bid2,
9999)
rowid2
FROM (SELECT a.*, ROWNUM rn
FROM ( SELECT chunk_no,
MIN (oid1) oid1,
MAX (oid2) oid2,
MIN (fid1) fid1,
MAX (fid2) fid2,
MIN (bid1) bid1,
MAX (bid2) bid2
FROM (SELECT chunk_no,
FIRST_VALUE (
data_object_id)
OVER (
PARTITION BY chunk_no
ORDER BY
data_object_id, relative_fno, block_id
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
oid1,
LAST_VALUE (
data_object_id)
OVER (
PARTITION BY chunk_no
ORDER BY
data_object_id, relative_fno, block_id
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
oid2,
FIRST_VALUE (
relative_fno)
OVER (
PARTITION BY chunk_no
ORDER BY
data_object_id, relative_fno, block_id
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
fid1,
LAST_VALUE (
relative_fno)
OVER (
PARTITION BY chunk_no
ORDER BY
data_object_id, relative_fno, block_id
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
fid2,
FIRST_VALUE (
block_id)
OVER (
PARTITION BY chunk_no
ORDER BY
data_object_id, relative_fno, block_id
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
bid1,
LAST_VALUE (
block_id + blocks - 1)
OVER (
PARTITION BY chunk_no
ORDER BY
data_object_id, relative_fno, block_id
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
bid2
FROM (SELECT data_object_id,
relative_fno,
block_id,
blocks,
CEIL (sum2 / chunk_size) chunk_no
FROM (SELECT /*+ rule */
b.data_object_id,
a.relative_fno,
a.block_id,
a.blocks,
SUM (
a.blocks)
OVER (
ORDER BY
b.data_object_id,
a.relative_fno,
a.block_id)
sum2,
CEIL (
SUM (a.blocks) OVER ()
/ &trunks)
chunk_size
FROM dba_extents a, dba_objects b
WHERE a.owner = b.owner
AND a.segment_name =
b.object_name
AND NVL (a.partition_name,
‘-1‘) =
NVL (b.subobject_name,
‘-1‘)
AND b.data_object_id
IS NOT NULL
AND a.owner = UPPER (‘&owner‘)
AND a.segment_name =
UPPER (‘&table_name‘))))
GROUP BY chunk_no
ORDER BY chunk_no) a);
该SQL 在执行时需要输入几个参数:
trunks: 表示把表分成的段数
owner: 表的所有者
table_name: 表名
查询的结果类似与:
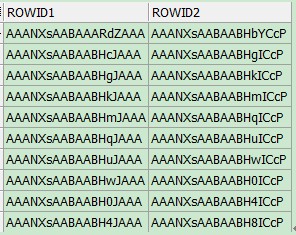
关于Rowid 的说明,参考我的Blog:
Oracle Rowid 介绍
http://blog.csdn.net/xujinyang/article/details/6829751
然后对每组Rowid 查询:
/* Formatted on 2011/6/29 19:25:15 (QP5 v5.163.1008.3004) */
SELECT /*+ NO_INDEX(A) */
COUNT (*)
FROM ta A
WHERE ROWID >= ‘AAANXsAABAAARdZAAA‘ AND ROWID <= ‘AAANXsAABAABHbYCcP‘;
以上是关于Oracle ORA-01555 快照过旧 说明的主要内容,如果未能解决你的问题,请参考以下文章
Oracle数据库 ORA-01555快照过旧是怎么回事?怎么解决?