SQL如何查询出某一列中不同值出现的次数?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL如何查询出某一列中不同值出现的次数?相关的知识,希望对你有一定的参考价值。
不同的值有很多,所以用case when不现实。
1、首先需要创建一个临时表,用于演示如何筛选出表中指定字段值重复的记录数量。
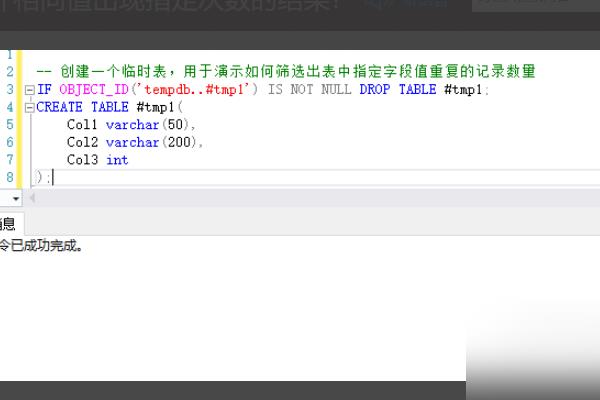
2、往临时表中插入几行测试数据,其中部分字段的Col2栏位值插入相同值,用于统计筛选相同Col2的行数。

3、查询临时表中的测试数据。
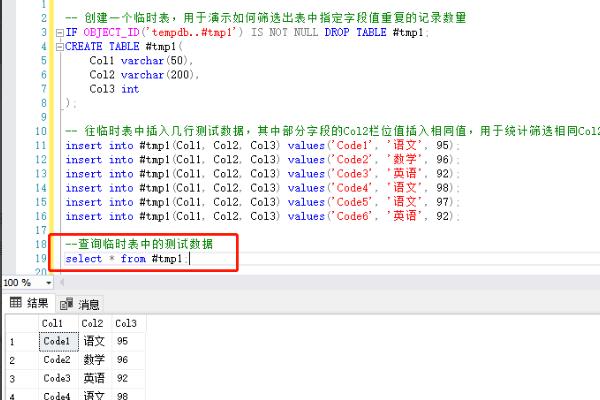
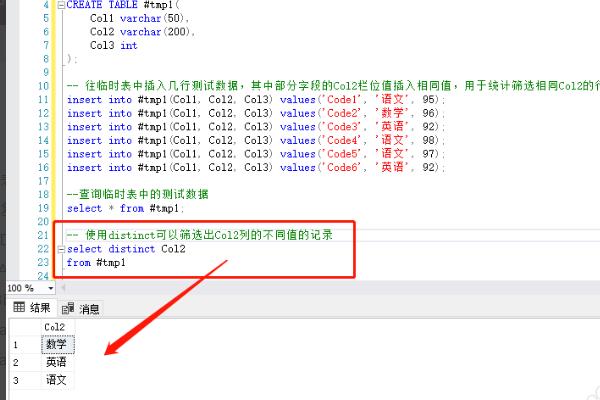
4、使用distinct可以筛选出Col2列的不同值的记录。
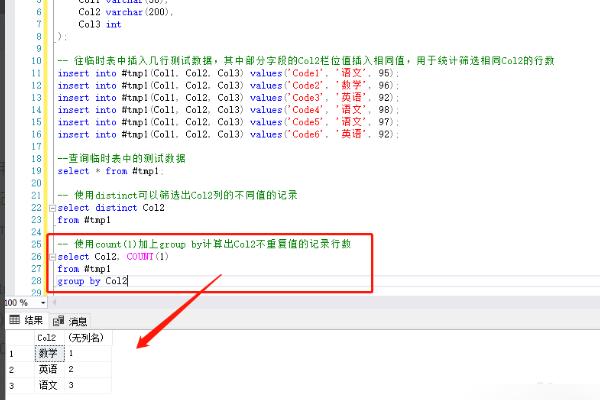
5、使用count(1)加上group by计算出Col2不重复值的记录行数。
6、使用having过滤出Col2列的行数大于1的值以及行数。

7、使用having过滤出Col2列的行数大于1的值以及行数,在按照行数倒序排列。

SQL查询出某一列中不同值出现次数的步骤如下:
我们需要准备的材料分别是:电脑、sql查询器。
1、首先,打开sql查询器,连接上相应的数据库表,例如test2表。
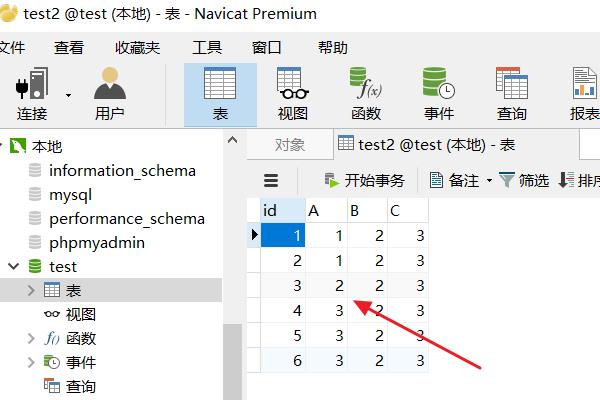
2、点击“查询”按钮,输入:select A, count(*) as num from test2 group by A;。
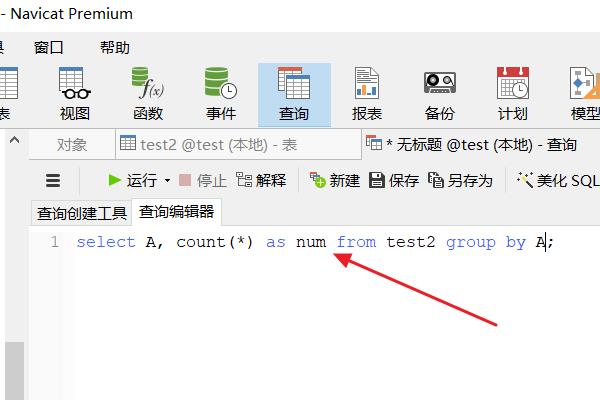
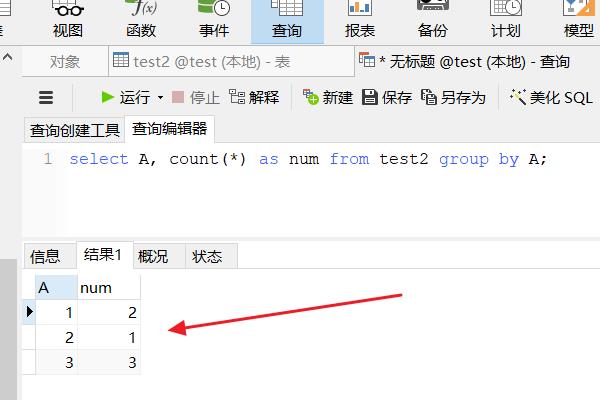
3、点击“运行”按钮,此时会将字段A的所有不同值出现的次数显示出。
我觉得好像不用楼上那么复杂吧?
select count(*) from (select distinct 列名 from 表名)子查询中使用distinct查询出所有不同的值,然后用select count(*)查询子查询返回到行数。
这句查到的是有多少不同的值,而不是每一个不同的值出现的次数。我的问题已经解决了,还是谢谢您的帮助
参考技术C select tb.newcolumn, count(ta.*) as cntfrom tableA ta
inner join (select distinct (thiscolumn) as newcolumn from tableA) tb
where ta.thiscolumn = tb.newcolumn
group by tb.newcolumn
实现了tableA 的 thiscolumn 的不同值的计数。主要的 inner join 自己group by 的值后的结果追问
报错了,不过还是谢谢你的帮助。
参考技术D SELECT 字段a,COUNT(DISTINCT(字段b)) FROM 表名 GROUP BY 字段a以上是关于SQL如何查询出某一列中不同值出现的次数?的主要内容,如果未能解决你的问题,请参考以下文章