Hadoop 2.x 之 HA 简介
Posted 嘣嘣嚓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 2.x 之 HA 简介相关的知识,希望对你有一定的参考价值。
HA结构图
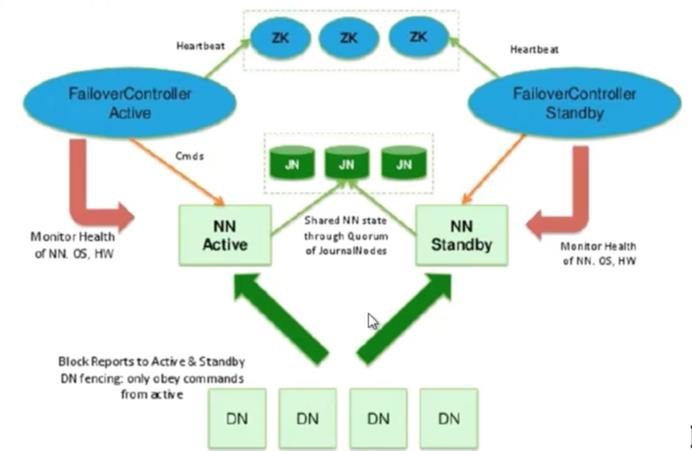
HA是用来解决单点故障问题
- DN: DataNode,启动时会往所有的NameNode汇报
- NN: NameNode(主 Active(一个) 备 Standby(可以有多个))
- JournalNodes:JournalNodes就是用来存储元数据的,是一个集群,节点数量必须为奇数个。
- 如果主NameNode的元数据存在本地磁盘中的fsimage及edits文件中,如果主挂掉了,那么备用NameNode将无法从主NameNode获取元数据文件,所以元数据文件不能存储在主NameNode的本地了,而是存储在JournalNodes中
- 所有的NameNode,不管是主还是备,读写元数据都是在JournalNodes中进行的。
- 主NameNode 挂掉后,备NameNode自动从JournalNodes中加载到元数据,然后进行工作。
- FailoverController: 控制NameNode切换的一个服务,还对NameNode进行心跳检查,判断是否挂掉,挂掉后要切换到另外一个NameNode
- ZooKeeper:主要工作是做高可用,任何一个服务的高可用都可以用ZooKeeper来做,节点数量必须为奇数个
- 客户端不指定IP地址访问NameNode,客户端去请求ZooKeeper,ZooKeeper知道哪个NameNode是Active的,然后ZooKeeper返回给客户端真正工作的NameNode
- 自动:ZooKeeper会对所有的NameNode进行心跳检测,检测有没有挂掉,可通过FailoverController对NameNode进行切换
- 手动:正常情况下,如果想对某个Active NameNode进行修改配置,可手动将其闲置下来,变成Standby,将另一个Standby的NameNode变成Active
HA优点
- 主备NameNode
- 解决单点故障
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有DataNode同时向两个NameNode汇报数据块信息
- 两种切换选择
- 手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
- 自动切换:基于ZooKeeper实现
- 基于ZooKeeper自动切换方案
- ZooKeeper FailoverController : 监控NameNode健康状态
- 并向Zookeeper注册NameNode
- NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active
主NameNode挂掉后,Standby竞争锁,每个NameNode对应的FailoverController在Zookeeper上竞争锁,获得锁之后就可以把该NameNode变成Active了
任何一个NameNode都要对应一个FailoverController
Zookeeper必须是奇数个,否则将不会得到一个锁,Zookeeper内部使用的是一个投票机制,竞争锁算法用的是投票机制
NFS网络文件系统(了解)
NFS 网络文件系统,相当于一个共享目录,找一台机器专门共享文件,让所有NameNode读写元数据都在那台共享机器上操作,读写在共享的目录中。(也会有单点故障问题)
以上是关于Hadoop 2.x 之 HA 简介的主要内容,如果未能解决你的问题,请参考以下文章