Mongodb数据模型
Posted 张小贱1987
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mongodb数据模型相关的知识,希望对你有一定的参考价值。
描述表关系的方式:
方式一:嵌入式
> db.person.find({name:\'zjf\'}).pretty()
{
"_id" : ObjectId("592ffd872108e8e79ea902b0"),
"name" : "zjf",
"age" : 30,
"address" : {
"province" : "河南省",
"city" : "南阳市",
"building" : "桐柏县"
}
}
将address作为一个对象嵌入到person中,此处也可以是一个数组。
这种方式会有数据冗余。而且address被写死在了person中,对于所有person来说,他们的address都是一个一个独立的,而不是可以作为一类一类共享的。
方式二:手动引用式
> db.person.find({name:\'xhj\'}).pretty()
{
"_id" : ObjectId("593011c8a92497992cdfac10"),
"name" : "xhj",
"age" : 30,
"address" : ObjectId("59314b07e693aae7a5eb72ab")
}
> db.address.find().pretty()
{
"_id" : ObjectId("59314b07e693aae7a5eb72ab"),
"province" : "河南省",
"city" : "南阳市",
"building" : "桐柏县"
}
person中存储的是指向address的引用。
这种方式的缺点是要经过join才能获取到所有数据,但是Mongodb的不支持直接的join语法。
DBRefs引用式
这种方式是上面的完善,不过依然有不能join的缺陷,需要两步才能获取数据。优点是“关联那张表的那个字段”可以记录在数据中。
第一种方式(注意顺序一定要是$ref,$id,$db):
> db.person.save({ "_id" : ObjectId("593011c8a92497992cdfac10"), "name" : "xhj", "age" : 30, "address" :{$ref:\'address\',$id: ObjectId("59314b07e693aae7a5eb72ab") ,$db:\'mydb\'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
第二种方式:
> db.person.save({ "_id" : ObjectId("593011c8a92497992cdfac10"), "name" : "xhj", "age" : 30, "address" : DBRef("address", ObjectId("59314b07e693aae7a5eb72ab"), "mydb") })
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 })
也可以不写$db参数
> db.person.save({ "_id" : ObjectId("593011c8a92497992cdfac10"), "name" : "xhj", "age" : 30, "address" : DBRef("address", ObjectId("59314b07e693aae7a5eb72ab")) })
> db.person.find({name:\'xhj\'}).pretty()
{
"_id" : ObjectId("593011c8a92497992cdfac10"),
"name" : "xhj",
"age" : 30,
"address" : DBRef("address", ObjectId("59314b07e693aae7a5eb72ab"), "mydb")
}
查询:
> var p = db.person.findOne({name:\'xhj\'})
> var p_address = p.address;
> db[p_address.$ref].find({_id:p_address.$id})
{ "_id" : ObjectId("59314b07e693aae7a5eb72ab"), "province" : "河南省", "city" : "南阳市", "building" : "桐柏县" }
注:以下翻译自Mongodb的官方文档。
数据建模介绍
数据建模中的关键挑战是平衡应用程序的需求,数据库引擎的性能特征和数据检索模式。 在设计数据模型时,请始终考虑数据的应用程序使用情况(即数据的查询,更新和处理)以及数据本身的固有结构。
文件结构
MongoDB应用程序设计数据模型的关键决定在于文档的结构以及应用程序如何表示数据之间的关系。 有两个工具允许应用程序来表示这些关系:引用和嵌入文档。
引用
引用通过将一个文档的链接或引用包含在另一个文档中来存储数据之间的关系 应用程序可以解析这些引用以访问相关数据。 广义上说,这些都是规范化的数据模型。
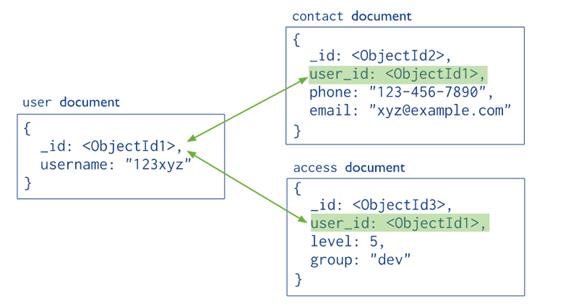
嵌入文档
嵌入文档通过将相关数据存储在单个文档结构中来捕获数据之间的关系。 MongoDB文档可以将文档结构嵌入到文档中的字段或数组中。 这些 "非规范化"模型,允许应用程序在单个数据库操作中检索和操纵相关数据。

写操作的原子性
在MongoDB中,写入操作在文档级别是原子的,没有一个写入操作可以原子上影响多个文档或多个集合。 具有嵌入数据的非正规化数据模型将表示的实体的所有相关数据组合在单个文档中。 这有助于原子写入操作,因为单个写入操作可以插入或更新实体的数据。 归一化数据将跨多个集合分割数据,并且需要不是原子的多个写入操作。
然而,促进原子写入的模式可能会限制应用程序可以使用数据的方式,也可能限制修改应用程序的方法。原子性注意事项文档描述了设计平衡灵活性和原子性的模式的挑战。
文件增长
一些更新,例如将元素推送到数组或添加新字段,可增加文档的大小。
对于MMAPv1存储引擎,如果文档大小超过该文档的分配空间,则MongoDB会将文档重定位到磁盘上。 使用MMAPv1存储引擎时,增长考虑可能会影响数据规范化或非规范化的决策。有关MMAPv1的文档增长计划和管理的更多信息,请参阅文档增长注意事项。
数据模型设计
有效的数据模型支持您的应用需求。 您的文档结构的关键考虑是决定嵌入或使用引用。
嵌入式数据模型
使用MongoDB,您可以将相关数据嵌入到单个结构或文档中。这些模式通常被称为"非规范化"模型,并利用MongoDB丰富的文档。
嵌入式数据模型允许应用程序在相同的数据库记录中存储相关的信息。因此,应用程序可能需要发出较少的查询和更新以完成常见操作。
一般来说,使用嵌入式数据模型时:
- 您有实体之间的"包含"关系。请参阅与嵌入式文档的模型一对一关系。
- 您有实体之间的一对多关系。在这些关系中,"许多"或子文档总是与"一个"或父文档一起出现或被查看。请参阅与嵌入式文档模型一对多关系。
通常,嵌入为读操作提供更好的性能,以及在单个数据库操作中请求和检索相关数据的能力。嵌入式数据模型可以在单个原子写入操作中更新相关数据。
然而,将相关数据嵌入到文档中可能会导致文档在创建后增长的情况。使用MMAPv1存储引擎,文档增长可能会影响写入性能并导致数据碎片化。
在3.0.0版本中,MongoDB使用2个大小的分配功能作为MMAPv1的默认分配策略,以便考虑文档增长,从而最大限度地减少数据碎片的可能性。此外,MongoDB中的文档必须小于最大BSON文档大小。对于批量二进制数据,请考虑GridFS。
规范化数据模型
一般来说,使用规范化数据模型:
- 嵌入时会导致数据重复,但不能提供足够的读取性能优势,超过重复的影响。
- 代表更复杂的多对多关系。
- 模拟大型分层数据集。
引用提供比嵌入更多的灵活性。 但是,客户端应用程序必须发出后续查询才能解析引用。 换句话说,规范化数据模型可能需要更多的往返服务器。
操作因素和数据模型
为MongoDB建模应用程序数据取决于数据本身以及MongoDB本身的特性。例如,不同的数据模型可能允许应用程序使用更有效的查询,增加插入和更新操作的吞吐量,或更有效地将活动分发到分片集群。
这些因素是在应用程序之外产生的操作或地址要求,但影响基于MongoDB的应用程序的性能。在开发数据模型时,结合以下注意事项分析所有应用程序的读写操作。
- 文件增长
版本3.0.0更改。
文档的一些更新可以增加文档的大小。这些更新包括将元素推送到数组(即$ push)并向文档添加新字段。
使用MMAPv1存储引擎时,文档增长可能是您的数据模型的考虑因素。对于MMAPv1,如果文档大小超过该文档的分配空间,MongoDB将将文档重新放置在磁盘上。然而,使用MongoDB 3.0.0,默认使用2大小分配的权力可以最大限度地减少这种重新分配的发生,并允许有效地重新使用释放的记录空间。
使用MMAPv1时,如果您的应用程序需要更新,频繁导致文档增长超过当前的2分配功能,则可能需要重构数据模型以使用不同文档中的数据之间的引用,而不是非规范化数据模型。
您还可以使用预分配策略来明确避免文档增长。
- 原子性
在MongoDB中,操作在文档级别是原子的。 没有单个写入操作可以更改多个文档。 在一个集合中修改多个单个文档的操作仍然一次在一个文档上运行。 [1]确保您的应用程序将所有具有原子相关性要求的字段存储在同一文档中。 如果应用程序可以容忍两个数据的非原子更新,则可以将这些数据存储在单独的文档中。
将相关数据嵌入到单个文档中的数据模型有助于这些原子操作。 对于存储相关数据之间的引用的数据模型,应用程序必须发出单独的读取和写入操作来检索和修改这些相关数据。
- 分片
MongoDB使用分片来提供水平缩放。 这些集群支持具有大数据集和高吞吐量操作的部署。 分片允许用户对数据库中的集合进行分区,以将集合的文档分发到多个mongod实例或分片。
为了将数据和应用程序流量分散到分片集合中,MongoDB使用分片键。 选择正确的分片键对性能有重大影响,并且可以启用或阻止查询隔离和增加写入容量。 重要的是仔细考虑用作分片键的字段或字段。
- 索引
使用索引来提高常见查询的性能。 在查询中经常出现的字段和返回排序结果的所有操作的字段上构建索引。 MongoDB会自动在_id字段上创建唯一的索引。
创建索引时,请考虑索引的以下行为:
- 每个索引需要至少8 kB的数据空间。
- 添加索引对于写入操作有一些负面的性能影响。 对于具有高读/写比率的集合,索引是昂贵的,因为每个插入也必须更新任何索引。
- 具有高读/写比率的集合通常受益于附加索引。 索引不影响未索引的读取操作。
- 当活动时,每个索引都会占用磁盘空间和内存。 这种使用可能是重要的,应该跟踪容量规划,特别是对于工作集大小的担忧。
- 大量集合
在某些情况下,您可能会选择将相关信息存储在多个集合中,而不是单个集合中。
考虑存储各种环境和应用程序的日志文件的示例收集日志。日志集合包含以下表单的文档:
{log:"dev",ts:...,info:...}
{log:"debug",ts:...,info:...}
如果文档总数较少,则可以按文件类型将文档分组到集合中。对于日志,请考虑维护不同的日志集合,例如logs_dev和logs_debug。 logs_dev集合将仅包含与开发环境相关的文档。
一般来说,拥有大量的集合并没有显着的性能损失,并导致非常好的性能。大量不同的集合对于高吞吐量的批处理非常重要。
使用具有大量集合的模型时,请考虑以下行为:
- 每个集合具有几千字节的一定的最小开销。
- 每个索引(包括_id上的索引)至少需要8 kB的数据空间。
- 对于每个数据库,单个命名空间文件(即<database> .ns)存储该数据库的所有元数据,每个索引和集合在命名空间文件中都有自己的条目。 MongoDB限制了命名空间文件的大小。
使用mmapv1存储引擎的MongoDB对命名空间的数量有限制。您可能希望知道当前的命名空间数量,以确定数据库可以支持多少命名空间。要获取当前的命名空间数,请在mongo shell中运行以下命令:
db.system.namespaces.count()
命名空间数量的限制取决于<database> .ns大小。命名空间文件默认为16 MB。
要更改新命名空间文件的大小,请使用选项--nssize <new size MB>启动服务器。对于现有数据库,在使用--nssize启动服务器后,从mongo shell运行db.repairDatabase()命令。
- 集合包含大量小文件
如果您拥有大量小型文档的集合,则应考虑性能方面的嵌入。如果您可以通过某种逻辑关系对这些小型文档进行分组,并且您经常通过此分组检索文档,则可以考虑将小型文档"滚动"到包含嵌入文档数组的较大文档中。
将这些小文档"滚动"到逻辑分组中意味着检索一组文档的查询涉及顺序读取和较少的随机磁盘访问。此外,"卷起"文件和将公共字段移动到较大的文档有利于这些领域的索引。公共字段的副本将减少,相应索引中的关键密钥条目将减少。
但是,如果您经常只需要检索组内的文档子集,那么"滚动"文档可能无法提供更好的性能。此外,如果小的单独文档代表数据的自然模型,则应该保持该模型。
- 小型集合的存储优化
每个MongoDB文档都包含一定的开销。这个开销通常是微不足道的,但是如果所有的文档只是几个字节,这可能会变得很重要,如果您的集合中的文档只有一个或两个字段,情况就会如此。
请考虑以下建议和策略来优化这些集合的存储利用率:
- 明确使用_id字段。
MongoDB客户端会自动为每个文档添加一个_id字段,并为_id字段生成唯一的12字节ObjectId。此外,MongoDB始终索引_id字段。对于较小的文档,这可能占用了大量的空间。
要优化存储使用,用户可以在将文档插入到集合中时明确指定_id字段的值。该策略允许应用程序在_id字段中存储将占用文档另一部分空间的值。
您可以在_id字段中存储任何值,但是由于此值作为集合中文档的主键,因此必须唯一标识它们。如果字段的值不是唯一的,那么它不能作为主键,因为集合中将存在冲突。
- 使用较短的字段名称。
注意
缩短字段名称可以降低表达力,并且不会对较大的文档提供相当大的收益,而文档开销并不重要。较短的字段名称不会减小索引的大小,因为索引具有预定义的结构。
一般来说,不需要使用短字段名称。
MongoDB将所有字段名称存储在每个文档中。对于大多数文档,这代表文档使用的空间的一小部分;然而,对于小文档,字段名称可以代表比例大的空间。考虑一下类似于以下内容的小型文档的集合:
{last_name:"Smith",best_score:3.9}
如果将名称为last_name的字段缩短为lname,并将名为best_score的字段缩短为以下条件,则可以为每个文档保存9个字节。
{lname:"史密斯",得分:3.9}
- 嵌入文件
在某些情况下,您可能希望将文档嵌入其他文档中,并保存在每个文档的开销上。查看收藏包含大量小文件。
- 数据生命周期管理
数据建模决策应考虑数据生命周期管理。
一段时间后,集合的生存时间或TTL特征到期文件。 考虑使用TTL功能,如果您的应用程序需要一些数据在数据库中持续一段有限的时间。
另外,如果您的应用程序仅使用最近插入的文档,请考虑使用Capped Collections。 加盖的集合提供插入文档的先进先出(FIFO)管理,并有效支持基于插入顺序插入和读取文档的操作。
我的理解是:
一对一可以随意考虑内嵌方式来提升性能。
一对多的关系,如果使用内嵌的方式,在很多种情况下都可能导致性能问题,如:
内嵌数组太大不适合使用内签方式,因为单个文档的大小是46M。
或者对内嵌数组有频繁的增删操作,特别是有$pull这种需求,因为这操作执行的比较慢,而Mongodb在低版本是全局锁,会阻塞其他的所有读写操作。
所以说,如果不是特别适合的场景(如一对一,或者内签数组的数量在固定的比较小的范围内,而且没有频繁的对内签数组的写操作),我们要考虑使用引用的方式来建模。
以上是关于Mongodb数据模型的主要内容,如果未能解决你的问题,请参考以下文章