MySQL基础第三课
Posted trp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL基础第三课相关的知识,希望对你有一定的参考价值。
回顾
字段类型(列类型): 数值型, 时间日期型和字符串类型
数值型: 整型和小数型(浮点型和定点型)
时间日期型: datetime, date,time,timestamp, year
字符串类型: 定长, 变长, 文件字符串(text和blob), 枚举和集合
mysql记录长度: 65535个字节, varchar达不到理论长度, NULL占用一个字节, text文本不占用记录长度(但是本身占据十个字节)
字段属性: 空属性, 列描述, 默认值
字段属性
主键, 唯一键和自增长.
主键
主键: primary key,主要的键. 一张表只能有一个字段可以使用对应的键, 用来唯一的约束该字段里面的数据, 不能重复: 这种称之为主键.
一张表只能有最多一个主键.
增加主键
SQL操作中有多种方式可以给表增加主键: 大体分为三种.
方案1: 在创建表的时候,直接在字段之后,跟primary key关键字(主键本身不允许为空)



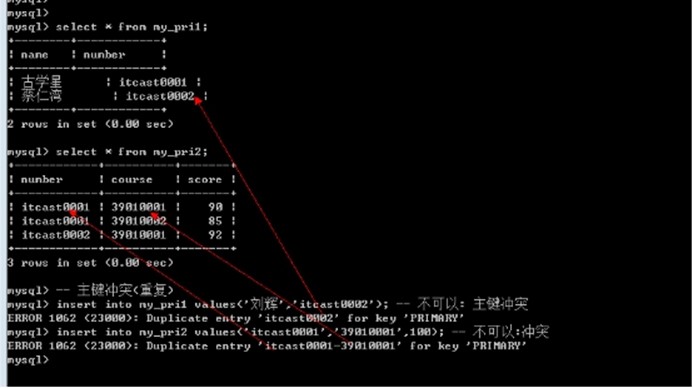
-- 增加主键 create table my_prim1( name varchar(20) not null comment \'姓名\', number char(10) primary key comment \'学号: itcast + 0000, 不能重复\' )charset utf8;
优点: 非常直接; 缺点: 只能使用一个字段作为主键
方案2: 在创建表的时候, 在所有的字段之后, 使用primary key(主键字段列表)来创建主键(如果有多个字段作为主键,可以是复合主键)

-- 复合主键 create table my_pri2( number char(10) comment \'学号: itcast + 0000\', course char(10) comment \'课程代码: 3901 + 0000\', score tinyint unsigned default 60 comment \'成绩\', -- 增加主键限制: 学号和课程号应该是对应的,具有唯一性 primary key(number,course) )charset utf8;
方案3: 当表已经创建好之后, 额外追加主键: 可以通过修改表字段属性, 也可以直接追加。
alter table 表名 add primary key(字段列表);

前提: 表中字段对应的数据本身是独立的(不重复)
主键约束
主键对应的字段中的数据不允许重复: 一旦重复,数据操作失败(增和改)
更新主键 & 删除主键
没有办法更新主键: 主键必须先删除,才能增加.
Alter table 表名 drop primary key;

主键分类
在实际创建表的过程中, 很少使用真实业务数据作为主键字段(业务主键,如学号,课程号); 大部分的时候是使用逻辑性的字段(字段没有业务含义,值是什么都没有关系), 将这种字段主键称之为逻辑主键.
Create table my_student(
Id int primary key auto_increment comment \'逻辑主键: 自增长\', -- 逻辑主键
Number char(10) not null comment \'学号\',
Name varchar(10) not null
)
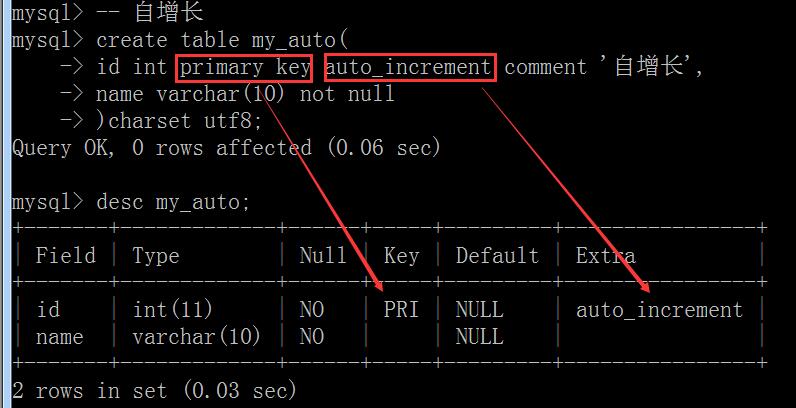
自增长
自增长: 当对应的字段,不给值,或者说给默认值,或者给NULL的时候, 会自动的被系统触发, 系统会从当前字段中已有的最大值再进行+1操作,得到一个新的不同的字段.
自增长通常是跟主键搭配.
新增自增长
自增长特点: auto_increment
-
任何一个字段要做自增长必须前提是本身是一个索引(key一栏有值)


自增长使用
当自增长被给定的值为NULL或者默认值的时候会触发自动增长.

自增长如果对应的字段输入了值,那么自增长失效: 但是下一次还是能够正确的自增长(从最大值+1)

如何确定下一次是什么自增长呢? 可以通过查看表创建语句看到.
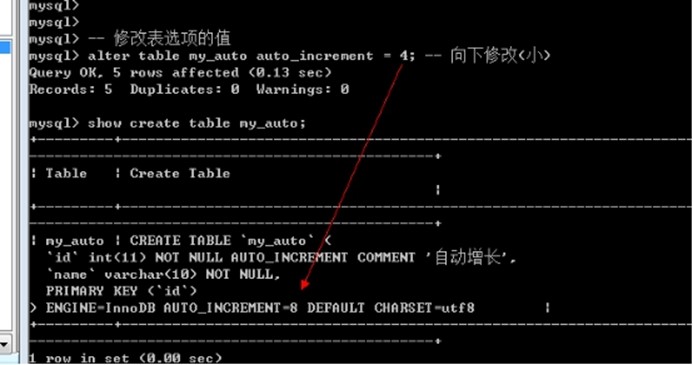
如下图:AUTO_INCREMENT=8 即表示该自增长的下一个值为8

修改自增长
自增长如果是涉及到字段改变: 必须先删除自增长,后增加(一张表只能有一个自增长)
修改当前自增长已经存在的值: 修改只能比当前已有的自增长的最大值大,不能小(小不生效)
Alter table 表名 auto_increment = 值;
向上修改可以

思考: 为什么自增长是从1开始?为什么每次都是自增1呢?
所有系统的变量(如字符集,校对集)都是由系统内部的变量进行控制的.
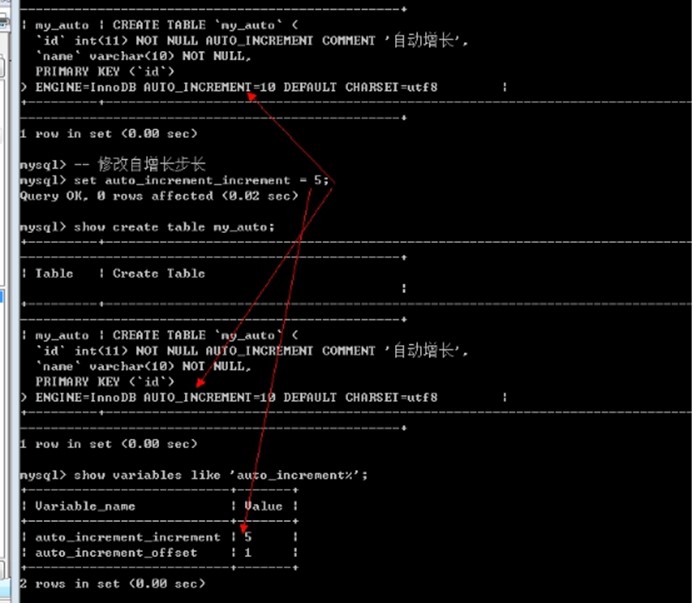
查看自增长对应的变量: show variables like \'auto_increment%\';

可以修改变量实现不同的效果: 修改是对整个数据修改,而不是单张表: (修改是会话级)
会话级:表示只对当前本次有效,关闭了数据库连接之后,就失效了
Set auto_increment_increment = 5; -- 一次自增5
测试效果: 自动使用自增长
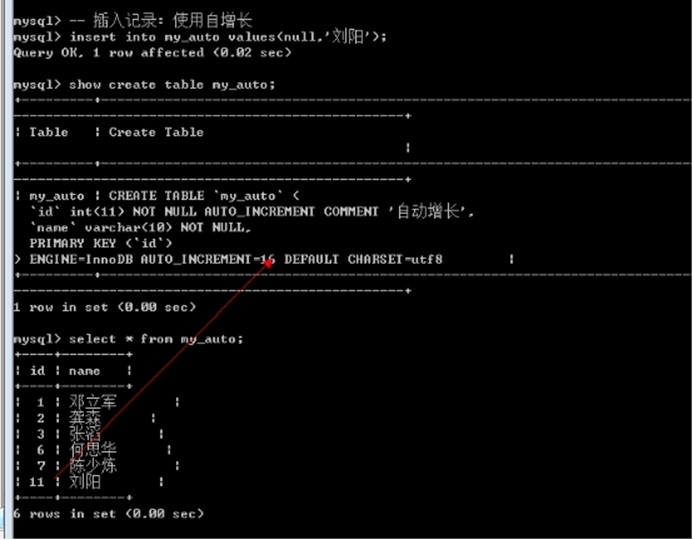
删除自增长
自增长是字段的一个属性: 可以通过modify来进行修改(保证字段没有auto_increment即可)
Alter table 表名 modify 字段 类型;

唯一键
一张表往往有很多字段需要具有唯一性,数据不能重复: 但是一张表中只能有一个主键: 唯一键(unique key)就可以解决表中有多个字段需要唯一性约束的问题.
唯一键的本质与主键差不多: 唯一键默认的允许自动为空,而且可以多个为空(空字段不参与唯一性比较)
增加唯一键
基本与主键差不多: 三种方案
方案1: 在创建表的时候,字段之后直接跟unique/ unique key

方案2: 在所有的字段之后增加unique key(字段列表); -- 复合唯一键

方案3: 在创建表之后增加唯一键
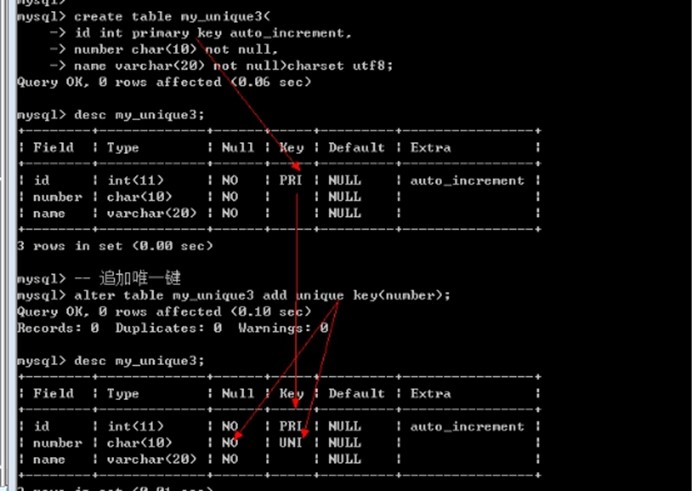
唯一键约束
唯一键与主键本质相同: 唯一的区别就是唯一键默认允许为空,而且是多个为空.

如果唯一键也不允许为空: 与主键的约束作用是一致的.
更新唯一键 & 删除唯一键
更新唯一键: 先删除后新增(唯一键可以有多个: 可以不删除).
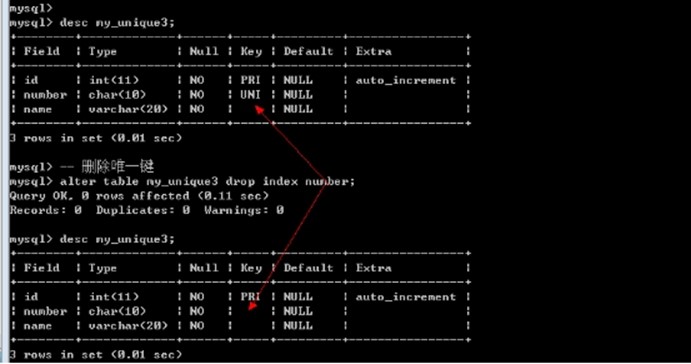
删除唯一键
Alter table 表名 drop unique key; -- 错误: 唯一键有多个
Alter table 表名 drop index 索引名字; -- 唯一键默认的使用字段名作为索引名字
索引
几乎所有的索引都是建立在字段之上.
索引: 系统根据某种算法, 将已有的数据(未来可能新增的数据),单独建立一个文件: 文件能够实现快速的匹配数据, 并且能够快速的找到对应表中的记录.
索引的意义
-
提升查询数据的效率
-
约束数据的有效性(唯一性等)
增加索引的前提条件: 索引本身会产生索引文件(有时候有可能比数据文件还大) ,会非常耗费磁盘空间.
如果某个字段需要作为查询的条件经常使用, 那么可以使用索引(一定会想办法增加);
如果某个字段需要进行数据的有效性约束, 也可能使用索引(主键,唯一键)
Mysql中提供了多种索引
-
主键索引: primary key
-
唯一索引: unique key
-
全文索引: fulltext index
-
普通索引: index
全文索引: 针对文章内部的关键字进行索引
全文索引最大的问题: 在于如何确定关键字
英文很容易: 英文单词与单词之间有空格
中文很难: 没有空格, 而且中文可以各种随意组合(分词: sphinx)
关系
将实体与实体的关系, 反应到最终数据库表的设计上来: 将关系分成三种: 一对一, 一对多(多对一)和多对多.
所有的关系都是指的表与表之间的关系.
一对一
一对一: 一张表的一条记录一定只能与另外一张表的一条记录进行对应; 反之亦然.
学生表: 姓名,性别,年龄,身高,体重,婚姻状况, 籍贯, 家庭住址,紧急联系人
|
Id(P) |
姓名 |
性别 |
年龄 |
体重 |
身高 |
婚姻 |
籍贯 |
住址 |
联系人 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表设计成以上这种形式: 符合要求. 其中姓名,性别,年龄,身高,体重属于常用数据; 但是婚姻,籍贯,住址和联系人属于不常用数据. 如果每次查询都是查询所有数据,不常用的数据就会影响效率, 实际又不用.
解决方案: 将常用的和不常用的信息分离存储,分成两张表
常用信息表
|
Id(P) |
姓名 |
性别 |
年龄 |
体重 |
身高 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
不常用信息表: 保证不常用信息与常用信息一定能够对应上: 找一个具有唯一性(确定记录)的字段来共同连接两张表
|
Id(P) |
婚姻 |
籍贯 |
住址 |
联系人 |
|
2 |
|
|
|
|
|
1 |
|
|
|
|
一个常用表中的一条记录: 永远只能在一张不常用表中匹配一条记录;反过来,一个不常用表中的一条记录在常用表中也只能匹配一条记录: 一对一的关系
一对多
一对多: 一张表中有一条记录可以对应另外一张表中的多条记录; 但是返回过, 另外一张表的一条记录只能对应第一张表的一条记录. 这种关系就是一对多或者多对一.
母亲与孩子的关系: 母亲,孩子两个实体
妈妈表
|
ID(P) |
名字 |
年龄 |
性别 |
|
|
|
|
|
|
|
|
|
|
孩子表
|
ID(P) |
名字 |
年龄 |
性别 |
|
|
|
|
|
|
|
|
|
|
以上关系: 一个妈妈可以在孩子表中找到多条记录(也有可能是一条); 但是一个孩子只能找到一个妈妈: 是一种典型的一对多的关系.
但是以上设计: 解决了实体的设计表问题, 但是没有解决关系问题: 孩子找不出妈,妈也找不到孩子.
解决方案: 在某一张表中增加一个字段,能够找到另外一张表的中记录: 应该在孩子表中增加一个字段指向妈妈表: 因为孩子表的记录只能匹配到一条妈妈表的记录.
妈妈表
|
ID(P) |
名字 |
年龄 |
性别 |
|
|
|
|
|
|
|
|
|
|
孩子表
|
ID(P) |
名字 |
年龄 |
性别 |
妈妈ID |
|
|
|
|
|
妈妈表主键 |
|
|
|
|
|
|
多对多
多对多: 一张表中(A)的一条记录能够对应另外一张表(B)中的多条记录; 同时B表中的一条记录也能对应A表中的多条记录: 多对多的关系
老师教学: 老师和学生
老师表
|
T_ID(P) |
姓名 |
性别 |
|
1 |
A |
男 |
|
2 |
B |
女 |
学生表
|
S_ID(P) |
姓名 |
性别 |
|
1 |
张三 |
男 |
|
2 |
小芳 |
女 |
以上设计方案: 实现了实体的设计, 但是没有维护实体的关系.
一个老师教过多个学生; 一个学生也被多个老师教过.
解决方案: 在学生表中增加老师字段: 不管在哪张表中增加字段, 都会出现一个问题: 该字段要保存多个数据, 而且是与其他表有关系的字段, 不符合表设计规范: 增加一张新表: 专门维护两张表之间的关系
老师表
|
T_ID(P) |
姓名 |
性别 |
|
1 |
A |
男 |
|
2 |
B |
女 |
学生表
|
S_ID(P) |
姓名 |
性别 |
|
1 |
张三 |
男 |
|
2 |
小芳 |
女 |
中间关系表: 老师与学生的关系
|
ID |
T_ID(老师) |
S_ID(学生) |
|
1 |
1 |
1 |
|
2 |
1 |
2 |
|
3 |
2 |
1 |
|
4 |
|
|
增加中间表之后: 中间表与老师表形成了一对多的关系: 而且中间表是多表,维护了能够唯一找到一表的关系; 同样的,学生表与中间表也是一个一对多的关系: 一对多的关系可以匹配到关联表之间的数据.
学生找老师: 找出学生id -> 中间表寻找匹配记录(多条) -> 老师表匹配(一条)
老师找学生: 找出老师id -> 中间表寻找匹配记录(多条) -> 学生表匹配(一条)
范式
范式: Normal Format, 是一种离散数学中的知识, 是为了解决一种数据的存储与优化的问题: 保存数据的存储之后, 凡是能够通过关系寻找出来的数据,坚决不再重复存储: 终极目标是为了减少数据的冗余.
范式: 是一种分层结构的规范, 分为六层: 每一次层都比上一层更加严格: 若要满足下一层范式,前提是满足上一层范式.
六层范式: 1NF,2NF,3NF...6NF, 1NF是最底层,要求最低;6NF最高层,最严格.
Mysql属于关系型数据库: 有空间浪费: 也是致力于节省存储空间: 与范式所有解决的问题不谋而合: 在设计数据库的时候, 会利用到范式来指导设计.
但是数据库不单是要解决空间问题,要保证效率问题: 范式只为解决空间问题, 所以数据库的设计又不可能完全按照范式的要求实现: 一般情况下,只有前三种范式需要满足.
范式在数据库的设计当中是有指导意义: 但是不是强制规范.
1NF
第一范式: 在设计表存储数据的时候, 如果表中设计的字段存储的数据,在取出来使用之前还需要额外的处理(拆分),那么说表的设计不满足第一范式: 第一范式要求字段的数据具有原子性: 不可再分.
讲师代课表
|
讲师 |
性别 |
班级 |
教室 |
代课时间 |
代课时间(开始,结束) |
|
朱元璋 |
Male |
php0226 |
D302 |
30天 |
2014-02-27,2014-05-05 |
|
朱元璋 |
Male |
php0320 |
B206 |
30天 |
2014-03-21,2014-05-30 |
|
李世民 |
Male |
php0320 |
B206 |
15天 |
2014-06-01,2014-06-20 |
上表设计不存在问题: 但是如果需求是将数据查出来之后,要求显示一个老师从什么时候开始上课,到什么时候节课: 需要将代课时间进行拆分: 不符合1NF, 数据不具有原子性, 可以再拆分.
解决方案: 将代课时间拆分成两个字段就解决问题.
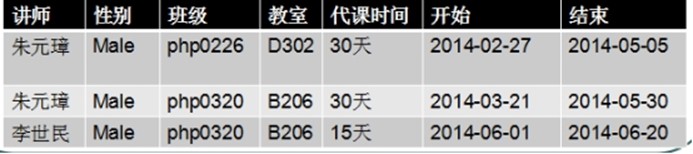
2NF
第二范式: 在数据表设计的过程中,如果有复合主键(多字段主键), 且表中有字段并不是由整个主键来确定, 而是依赖主键中的某个字段(主键的部分): 存在字段依赖主键的部分的问题, 称之为部分依赖: 第二范式就是要解决表设计不允许出现部分依赖.
讲师带课表

以上表中: 因为讲师没有办法作为独立主键, 需要结合班级才能作为主键(复合主键: 一个老师在一个班永远只带一个阶段的课): 代课时间,开始和结束字段都与当前的代课主键(讲师和班级): 但是性别并不依赖班级, 教室不依赖讲师: 性别只依赖讲师, 教室只依赖班级: 出现了性别和教室依赖主键中的一部分: 部分依赖.不符合第二范式.
解决方案1: 可以将性别与讲师单独成表, 班级与教室也单独成表.
解决方案2: 取消复合主键, 使用逻辑主键

ID = 讲师 + 班级(业务逻辑约束: 复合唯一键)
3NF
要满足第三范式,必须满足第二范式.
第三范式: 理论上讲,应该一张表中的所有字段都应该直接依赖主键(逻辑主键: 代表的是业务主键), 如果表设计中存在一个字段, 并不直接依赖主键,而是通过某个非主键字段依赖,最终实现依赖主键: 把这种不是直接依赖主键,而是依赖非主键字段的依赖关系称之为传递依赖. 第三范式就是要解决传递依赖的问题.
讲师带课表

以上设计方案中: 性别依赖讲师存在, 讲师依赖主键; 教室依赖班级,班级依赖主键: 性别和教室都存在传递依赖.
解决方案: 将存在传递依赖的字段,以及依赖的字段本身单独取出,形成一个单独的表, 然后在需要对应的信息的时候, 使用对应的实体表的主键加进来.
讲师代课表

讲师表 班级表


讲师表: ID = 讲师 班级表中: ID = 班级
逆规范化
有时候, 在设计表的时候,如果一张表中有几个字段是需要从另外的表中去获取信息. 理论上讲, 的确可以获取到想要的数据, 但是就是效率低一点. 会刻意的在某些表中,不去保存另外表的主键(逻辑主键), 而是直接保存想要的数据信息: 这样一来,在查询数据的时候, 一张表可以直接提供数据, 而不需要多表查询(效率低), 但是会导致数据冗余增加.
如讲师代课信息表

逆规范化: 磁盘利用率与效率的对抗
数据高级操作
数据操作: 增删改查
新增数据
基本语法
Insert into 表名 [(字段列表)] values (值列表);
在数据插入的时候, 假设主键对应的值已经存在: 插入一定会失败!(因为主键值的唯一性)
主键冲突
当主键存在冲突的时候(Duplicate key),可以选择性的进行处理: 更新和替换
主键冲突: 更新操作
Insert into 表名[(字段列表:包含主键)] values(值列表) on duplicate key update 字段 = 新值;

主键冲突: 替换
Replace into 表名 [(字段列表:包含主键)] values(值列表);

蠕虫复制
蠕虫复制: 从已有的数据中去获取数据,然后将数据又进行新增操作: 数据成倍的增加.
表创建高级操作: 从已有表创建新表(复制表结构)
Create table 表名 like 数据库.表名;
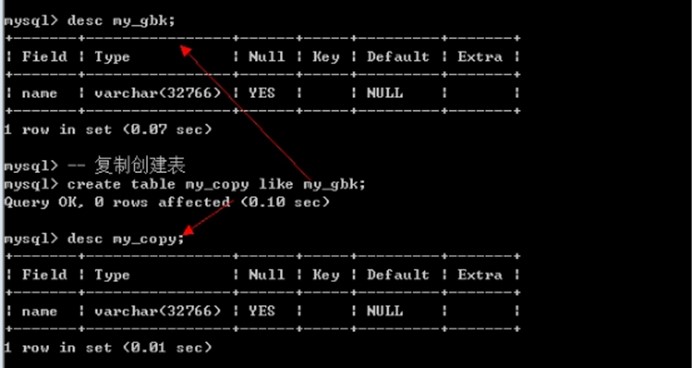
蠕虫复制: 先查出数据, 然后将查出的数据新增一遍
Insert into 表名[(字段列表)] select 字段列表/* from 数据表名;
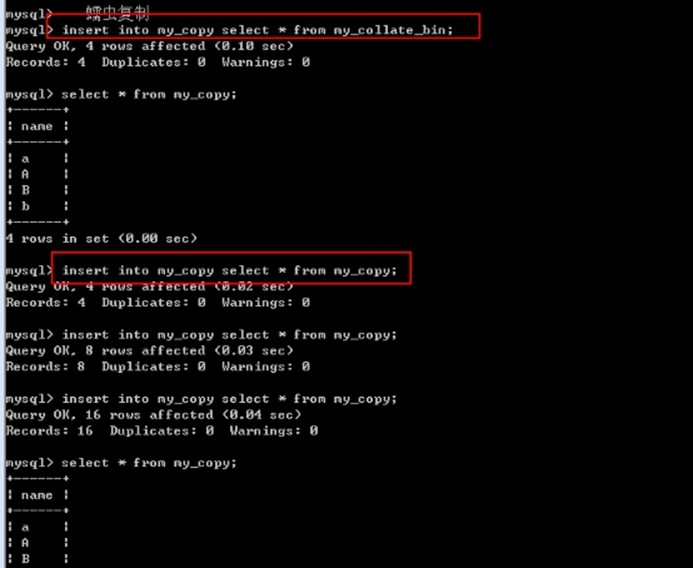
蠕虫复制的意义
-
从已有表拷贝数据到新表中(也可以从自己的表中复制数据到自己表中,也就是自我复制,但是复制的时候不要复制主键,因为这会引起主键冲突)
-
可以迅速的让表中的数据膨胀到一定的数量级: 测试表的压力以及效率
更新数据
基本语法
Update 表名 set 字段 = 值 [where条件];
高级新增语法
Update 表名 set 字段 = 值 [where条件] [limit 更新数量];
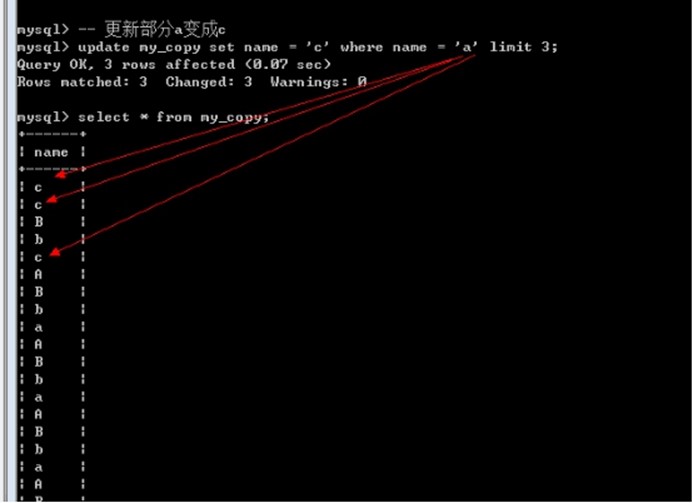
删除数据
与更新类似: 可以通过limit来限制数量
Delete from 表名 [where条件] [limit 数量];
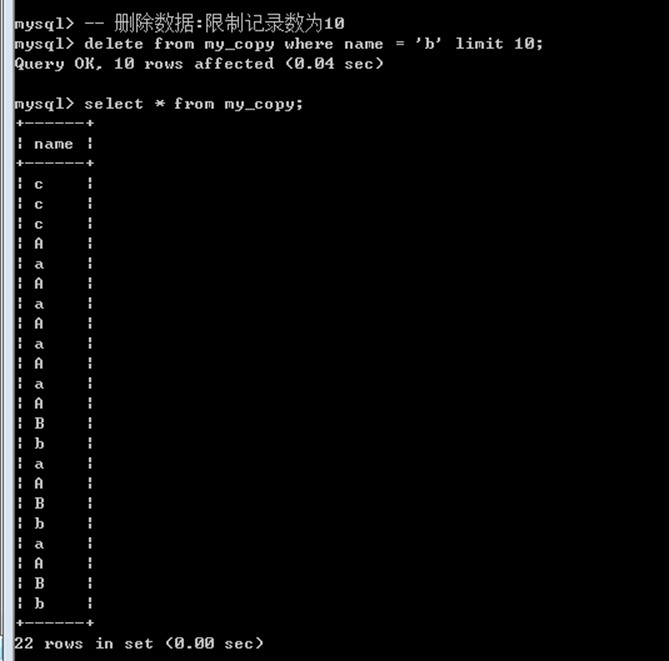
删除: 如果表中存在主键自增长,那么当删除之后, 自增长不会还原

思路: 数据的删除是不会改变表结构, 只能删除表后重建表
Truncate 表名; -- 先删除改变,后新增改变

查询数据
基本语法
Select 字段列表/* from 表名 [where条件];
完整语法
Select [select选项] 字段列表[字段别名]/* from 数据源 [where条件子句] [group by子句] [having子句] [order by子句] [limit 子句];
Select选项
Select选项: select对查出来的结果的处理方式
All: 默认的,保留所有的结果
Distinct: 去重, 查出来的结果,将重复给去除(所有字段都相同)

字段别名
字段别名: 当数据进行查询出来的时候, 有时候名字并一定就满足需求(多表查询的时候, 会有同名字段). 需要对字段名进行重命名: 别名
语法
字段名 [as] 别名;
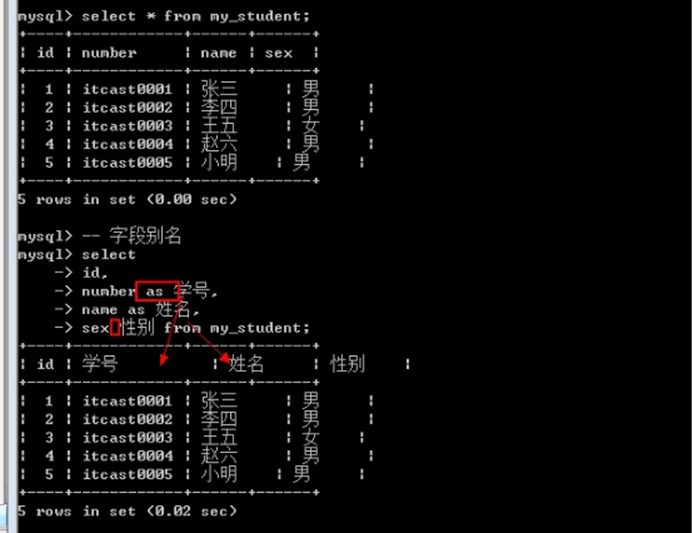
数据源
数据源: 数据的来源, 关系型数据库的来源都是数据表: 本质上只要保证数据类似二维表,最终都可以作为数据源.
数据源分为多种: 单表数据源, 多表数据源, 查询语句
单表数据源: select * from 表名;

多表数据源: select* from 表名1,表名2...;

从一张表中取出一条记录,去另外一张表中匹配所有记录,而且全部保留:(记录数和字段数),将这种结果成为: 笛卡尔积(交叉连接): 笛卡尔积没什么卵用, 所以应该尽量避免.
子查询: 数据的来源是一条查询语句(查询语句的结果是二维表)
Select * from (select 语句) as 表名;

Where子句
Where子句: 用来判断数据,筛选数据.
Where子句返回结果: 0或者1, 0代表false,1代表true.
判断条件:
比较运算符: >, <, >=, <= ,!= ,<>, =, like, between and, in/not in
逻辑运算符: &&(and), ||(or), !(not)
Where原理: where是唯一一个直接从磁盘获取数据的时候就开始判断的条件: 从磁盘取出一条记录, 开始进行where判断: 判断的结果如果成立保存到内存;如果失败直接放弃.
条件查询1: 要求找出学生id为1或者3或者5的学生

条件查询2: 查出区间落在180,190身高之间的学生:

Between本身是闭区间; between左边的值必须小于或者等于右边的值

Group by子句
Group by:分组的意思, 根据某个字段进行分组(相同的放一组,不同的分到不同的组)
基本语法: group by 字段名;

分组的意思: 是为了统计数据(按组统计: 按分组字段进行数据统计)
SQL提供了一系列统计函数
Count(): 统计分组后的记录数: 每一组有多少记录
Max(): 统计每组中最大的值
Min(): 统计最小值
Avg(): 统计平均值
Sum(): 统计和

Count函数: 里面可以使用两种参数: *代表统计记录,字段名代表统计对应的字段(NULL不统计)

分组会自动排序: 根据分组字段:默认升序
Group by 字段 [asc|desc]; -- 对分组的结果合并之后的整个结果进行排序

多字段分组: 先根据一个字段进行分组,然后对分组后的结果再次按照其他字段进行分组

有一个函数: 可以对分组的结果中的某个字段进行字符串连接(保留该组所有的某个字段): group_concat(字段);

回溯统计: with rollup: 任何一个分组后都会有一个小组, 最后都需要向上级分组进行汇报统计: 根据当前分组的字段. 这就是回溯统计: 回溯统计的时候会将分组字段置空.

多字段回溯: 考虑第一层分组会有此回溯: 第二次分组要看第一次分组的组数, 组数是多少,回溯就是多少,然后加上第一层回溯即可.

Having子句
Having子句: 与where子句一样: 进行条件判断的.
Where是针对磁盘数据进行判断: 进入到内存之后,会进行分组操作: 分组结果就需要having来处理.
Having能做where能做的几乎所有事情, 但是where却不能做having能做的很多事情.
-
分组统计的结果或者说统计函数都只有having能够使用.

-
Having能够使用字段别名: where不能: where是从磁盘取数据,而名字只可能是字段名: 别名是在字段进入到内存后才会产生.

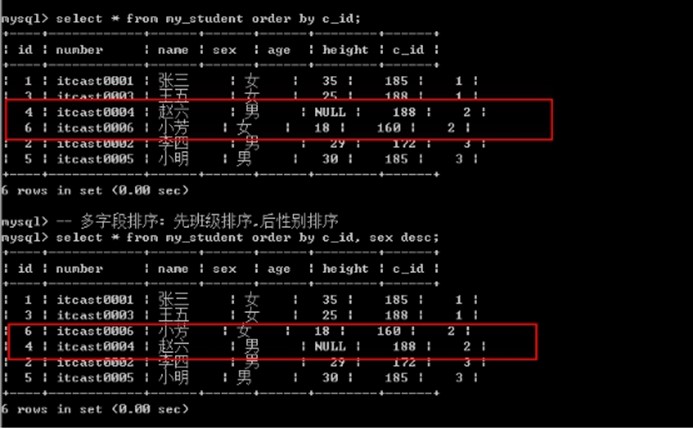
Order by子句
Order by: 排序, 根据某个字段进行升序或者降序排序, 依赖校对集.
使用基本语法
Order by 字段名 [asc|desc]; -- asc是升序(默认的),desc是降序

排序可以进行多字段排序: 先根据某个字段进行排序, 然后排序好的内部,再按照某个数据进行再次排序:
Limit子句
Limit子句是一种限制结果的语句: 限制数量.
Limit有两种使用方式
方案1: 只用来限制长度(数据量): limit 数据量;

方案2: 限制起始位置,限制数量: limit 起始位置,长度;

Limit方案2主要用来实现数据的分页: 为用户节省时间,提交服务器的响应效率, 减少资源的浪费.
对于用户来讲: 可以点击的分页按钮: 1,2,3,4
对于服务器来讲: 根据用户选择的页码来获取不同的数据: limit offset,length;
Length: 每页显示的数据量: 基本不变
Offset: offset = (页码 - 1) * 每页显示量
对应sql脚本代码:
-- 增加主键 create table my_pri1( name varchar(20) not null comment \'姓名\', number char(10) primary key comment \'学号: itcast + 0000, 不能重复\' )charset utf8; -- 复合主键 create table my_pri2( number char(10) comment \'学号: itcast + 0000\', course char(10) comment \'课程代码: 3901 + 0000\', score tinyint unsigned default 60 comment \'成绩\', -- 增加主键限制: 学号和课程号应该是个对应的,具有唯一性 primary key(number,course) )charset utf8; -- 追加主键 create table my_pri3( course char(10) not null comment \'课程编号: 3901 + 0000\', name varchar(10) not null comment \'课程名字\' ); alter table my_pri3 modify course char(10) primary key comment \'课程编号: 3901 + 0000\'; alter table my_pri3 add primary key(course); -- 向pri1表插入数据 insert into my_pri1 values(\'古学星\',\'itcast0001\'),(\'蔡仁湾\',\'itcast0002\'); insert into my_pri2 values(\'itcast0001\',\'39010001\',90),(\'itcast0001\',\'39010002\',85),(\'itcast0002\',\'39010001\',92); -- 主键冲突(重复) insert into my_pri1 values(\'刘辉\',\'itcast0002\'); -- 不可以: 主键冲突 insert into my_pri2 values(\'itcast0001\',\'39010001\',100); -- 不可以:冲突 -- 删除主键 alter table my_pri3 drop primary key; -- 自增长 create table my_auto( id int primary key auto_increment comment \'自动增长\', name varchar(10) not null )charset utf8; -- 触发自增长 insert into my_auto(name) values(\'邓立军\'); insert into my_auto values(null,\'龚森\'); insert into my_auto values(default,\'张滔\'); -- 指定数据 insert into my_auto values(6,\'何思华\'); insert into my_auto values(null,\'陈少炼\'); -- 修改表选项的值 alter table my_auto auto_increment = 4; -- 向下修改(小) alter table my_auto auto_increment = 10; -- 向上修改 -- 查看自增长变量 show variables like \'auto_increment%\'; -- 修改自增长步长 set auto_increment_increment = 5; -- 插入记录: 使用自增长 insert into my_auto values(null,\'刘阳\'); insert into my_auto values(null,\'邓贤师\'); -- 删除自增长 alter table my_auto modify id int primary key; -- 错误: 主键理论是单独存在 alter table my_auto modify id int; -- 有主键的时候,千万不要再加主键 -- 唯一键 create table my_unique1( number char(10) unique comment \'学号: 唯一,允许为空\', name varchar(20) not null )charset utf8; create table my_unique2( number char(10) not null comment \'学号以上是关于MySQL基础第三课的主要内容,如果未能解决你的问题,请参考以下文章