mac搭建redis环境
Posted 东方赞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mac搭建redis环境相关的知识,希望对你有一定的参考价值。
一、redis简介
二、redis环境搭建
2.1 redis下载安装
1、首先到官网下载redis,当前最新的版本应该是3.2.4,下载当时最新的稳定版本即可;
官网地址:http://redis.io
2、将下载下来的压缩文件拷贝到/usr/local/目录下;
sudo cp redis-3.2.4.tar.gz
3、进入redis-3.2.4目录;
4、编译测试:sudo make test
正常情况下应该是这样的:
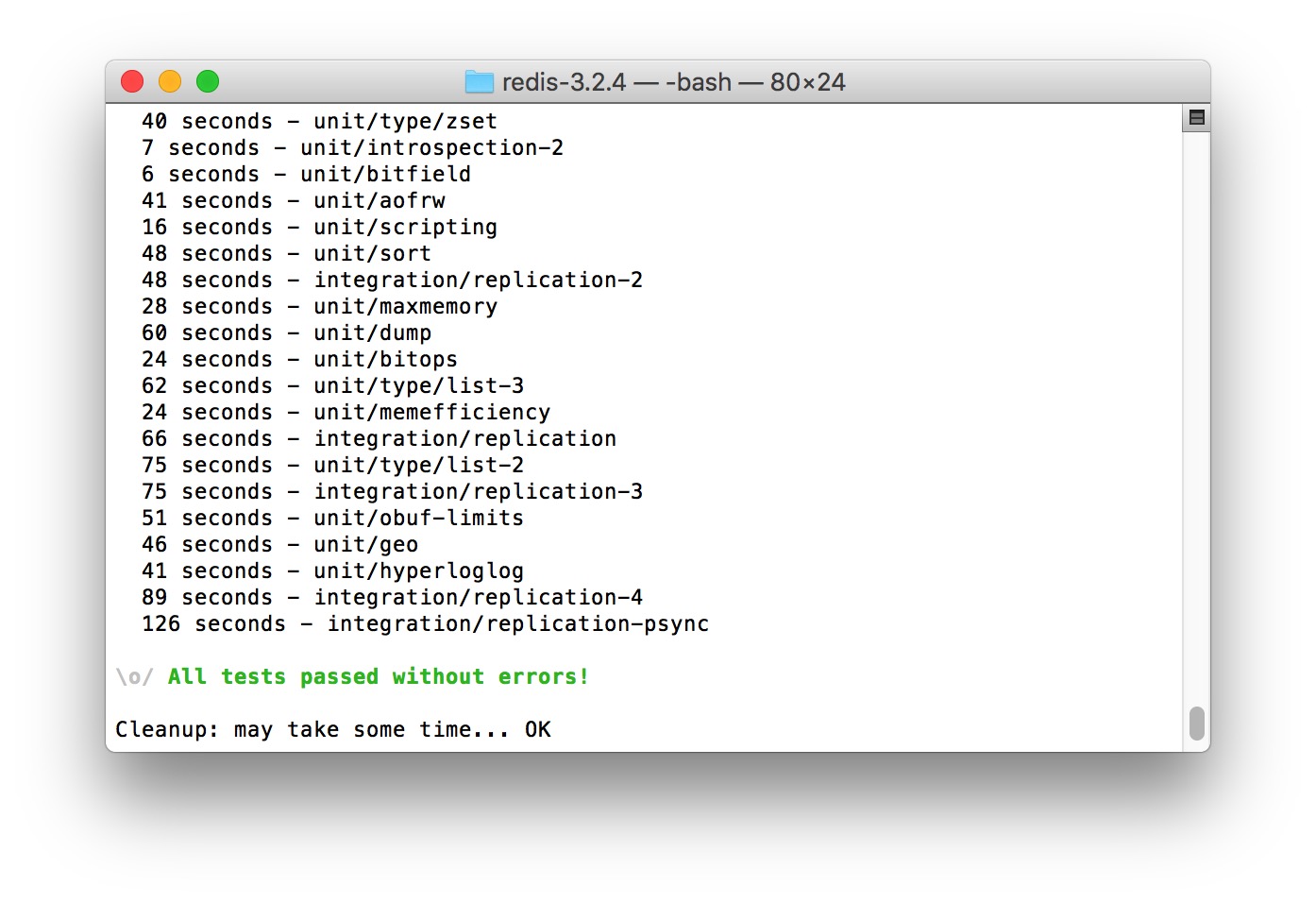
5、redis安装:sudo make install
至此完全安装成功,下面来说一下redis的配置
--------------------------------------------------------------------------
2.2 redis配置
1、在/usr/local目录下创建三个文件夹,包括bin,etc,db三个目录,如果已有就直接用吧
sudo mkdir /usr/local/bin
sudo mkdir /usr/local/etc
sudo mkdir /usr/local/db
2、进入/usr/local/etc/文件夹,创建redis文件夹,并创建redis.conf配置文件,也可以把安装目录下(即之前解压缩的/usr/local/redis-3.2.4/redis.conf)复制过来,再进行修改;
3、修改redis.conf配置文件,主要注意的是配置一下ip地址(如果配成127.0.0.1,那么默认只能本机访问redis服务器,如果需要其他局域网内机器或外网机器进行访问时,请配置成当前机器的ip地址),超时时间,日志文件位置等等。具体内容可以在网上搜索redis配置文件每一个含义,这里就不一一解释了。


1 # Redis configuration file example. 2 # 3 # Note that in order to read the configuration file, Redis must be 4 # started with the file path as first argument: 5 # 6 # ./redis-server /path/to/redis.conf 7 8 # Note on units: when memory size is needed, it is possible to specify 9 # it in the usual form of 1k 5GB 4M and so forth: 10 # 11 # 1k => 1000 bytes 12 # 1kb => 1024 bytes 13 # 1m => 1000000 bytes 14 # 1mb => 1024*1024 bytes 15 # 1g => 1000000000 bytes 16 # 1gb => 1024*1024*1024 bytes 17 # 18 # units are case insensitive so 1GB 1Gb 1gB are all the same. 19 20 ################################## INCLUDES ################################### 21 22 # Include one or more other config files here. This is useful if you 23 # have a standard template that goes to all Redis servers but also need 24 # to customize a few per-server settings. Include files can include 25 # other files, so use this wisely. 26 # 27 # Notice option "include" won\'t be rewritten by command "CONFIG REWRITE" 28 # from admin or Redis Sentinel. Since Redis always uses the last processed 29 # line as value of a configuration directive, you\'d better put includes 30 # at the beginning of this file to avoid overwriting config change at runtime. 31 # 32 # If instead you are interested in using includes to override configuration 33 # options, it is better to use include as the last line. 34 # 35 # include /path/to/local.conf 36 # include /path/to/other.conf 37 38 ################################## NETWORK ##################################### 39 40 # By default, if no "bind" configuration directive is specified, Redis listens 41 # for connections from all the network interfaces available on the server. 42 # It is possible to listen to just one or multiple selected interfaces using 43 # the "bind" configuration directive, followed by one or more IP addresses. 44 # 45 # Examples: 46 # 47 # bind 192.168.1.100 10.0.0.1 48 # bind 127.0.0.1 ::1 49 # 50 # ~~~ WARNING ~~~ If the computer running Redis is directly exposed to the 51 # internet, binding to all the interfaces is dangerous and will expose the 52 # instance to everybody on the internet. So by default we uncomment the 53 # following bind directive, that will force Redis to listen only into 54 # the IPv4 lookback interface address (this means Redis will be able to 55 # accept connections only from clients running into the same computer it 56 # is running). 57 # 58 # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES 59 # JUST COMMENT THE FOLLOWING LINE. 60 # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 61 # bind 127.0.0.1 62 63 bind 121.49.107.233 64 65 # Protected mode is a layer of security protection, in order to avoid that 66 # Redis instances left open on the internet are accessed and exploited. 67 # 68 # When protected mode is on and if: 69 # 70 # 1) The server is not binding explicitly to a set of addresses using the 71 # "bind" directive. 72 # 2) No password is configured. 73 # 74 # The server only accepts connections from clients connecting from the 75 # IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain 76 # sockets. 77 # 78 # By default protected mode is enabled. You should disable it only if 79 # you are sure you want clients from other hosts to connect to Redis 80 # even if no authentication is configured, nor a specific set of interfaces 81 # are explicitly listed using the "bind" directive. 82 protected-mode yes 83 84 # Accept connections on the specified port, default is 6379 (IANA #815344). 85 # If port 0 is specified Redis will not listen on a TCP socket. 86 port 6379 87 88 # TCP listen() backlog. 89 # 90 # In high requests-per-second environments you need an high backlog in order 91 # to avoid slow clients connections issues. Note that the Linux kernel 92 # will silently truncate it to the value of /proc/sys/net/core/somaxconn so 93 # make sure to raise both the value of somaxconn and tcp_max_syn_backlog 94 # in order to get the desired effect. 95 tcp-backlog 511 96 97 # Unix socket. 98 # 99 # Specify the path for the Unix socket that will be used to listen for 100 # incoming connections. There is no default, so Redis will not listen 101 # on a unix socket when not specified. 102 # 103 # unixsocket /tmp/redis.sock 104 # unixsocketperm 700 105 106 # Close the connection after a client is idle for N seconds (0 to disable) 107 timeout 300 108 109 # TCP keepalive. 110 # 111 # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence 112 # of communication. This is useful for two reasons: 113 # 114 # 1) Detect dead peers. 115 # 2) Take the connection alive from the point of view of network 116 # equipment in the middle. 117 # 118 # On Linux, the specified value (in seconds) is the period used to send ACKs. 119 # Note that to close the connection the double of the time is needed. 120 # On other kernels the period depends on the kernel configuration. 121 # 122 # A reasonable value for this option is 300 seconds, which is the new 123 # Redis default starting with Redis 3.2.1. 124 tcp-keepalive 300 125 126 ################################# GENERAL ##################################### 127 128 # By default Redis does not run as a daemon. Use \'yes\' if you need it. 129 # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. 130 daemonize yes 131 132 # If you run Redis from upstart or systemd, Redis can interact with your 133 # supervision tree. Options: 134 # supervised no - no supervision interaction 135 # supervised upstart - signal upstart by putting Redis into SIGSTOP mode 136 # supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET 137 # supervised auto - detect upstart or systemd method based on 138 # UPSTART_JOB or NOTIFY_SOCKET environment variables 139 # Note: these supervision methods only signal "process is ready." 140 # They do not enable continuous liveness pings back to your supervisor. 141 supervised no 142 143 # If a pid file is specified, Redis writes it where specified at startup 144 # and removes it at exit. 145 # 146 # When the server runs non daemonized, no pid file is created if none is 147 # specified in the configuration. When the server is daemonized, the pid file 148 # is used even if not specified, defaulting to "/var/run/redis.pid". 149 # 150 # Creating a pid file is best effort: if Redis is not able to create it 151 # nothing bad happens, the server will start and run normally. 152 pidfile /var/run/redis_6379.pid 153 154 # Specify the server verbosity level. 155 # This can be one of: 156 # debug (a lot of information, useful for development/testing) 157 # verbose (many rarely useful info, but not a mess like the debug level) 158 # notice (moderately verbose, what you want in production probably) 159 # warning (only very important / critical messages are logged) 160 loglevel debug 161 162 # Specify the log file name. Also the empty string can be used to force 163 # Redis to log on the standard output. Note that if you use standard 164 # output for logging but daemonize, logs will be sent to /dev/null 165 logfile /usr/local/etc/redis/log-redis.log 166 167 # To enable logging to the system logger, just set \'syslog-enabled\' to yes, 168 # and optionally update the other syslog parameters to suit your needs. 169 # syslog-enabled no 170 171 # Specify the syslog identity. 172 # syslog-ident redis 173 174 # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7. 175 # syslog-facility local0 176 177 # Set the number of databases. The default database is DB 0, you can select 178 # a different one on a per-connection basis using SELECT <dbid> where 179 # dbid is a number between 0 and \'databases\'-1 180 databases 8 181 182 ################################ SNAPSHOTTING ################################ 183 # 184 # Save the DB on disk: 185 # 186 # save <seconds> <changes> 187 # 188 # Will save the DB if both the given number of seconds and the given 189 # number of write operations against the DB occurred. 190 # 191 # In the example below the behaviour will be to save: 192 # after 900 sec (15 min) if at least 1 key changed 193 # after 300 sec (5 min) if at least 10 keys changed 194 # after 60 sec if at least 10000 keys changed 195 # 196 # Note: you can disable saving completely by commenting out all "save" lines. 197 # 198 # It is also possible to remove all the previously configured save 199 # points by adding a save directive with a single empty string argument 200 # like in the following example: 201 # 202 # save "" 203 204 save 900 1 205 save 300 10 206 save 60 10000 207 208 # By default Redis will stop accepting writes if RDB snapshots are enabled 209 # (at least one save point) and the latest background save failed. 210 # This will make the user aware (in a hard way) that data is not persisting 211 # on disk properly, otherwise chances are that no one will notice and some 212 # disaster will happen. 213 # 214 # If the background saving process will start working again Redis will 215 # automatically allow writes again. 216 # 217 # However if you have setup your proper monitoring of the Redis server 218 # and persistence, you may want to disable this feature so that Redis will 219 # continue to work as usual even if there are problems with disk, 220 # permissions, and so forth. 221 stop-writes-on-bgsave-error yes 222 223 # Compress string objects using LZF when dump .rdb databases? 224 # For default that\'s set to \'yes\' as it\'s almost always a win. 225 # If you want to save some CPU in the saving child set it to \'no\' but 226 # the dataset will likely be bigger if you have compressible values or keys. 227 rdbcompression yes 228 229 # Since version 5 of RDB a CRC64 checksum is placed at the end of the file. 230 # This makes the format more resistant to corruption but there is a performance 231 # hit to pay (around 10%) when saving and loading RDB files, so you can disable it 232 # for maximum performances. 233 # 234 # RDB files created with checksum disabled have a checksum of zero that will 235 # tell the loading code to skip the check. 236 rdbchecksum yes 237 238 # The filename where to dump the DB 239 dbfilename dump.rdb 240 241 # The working directory. 242 # 243 # The DB will be written inside this directory, with the filename specified 244 # above using the \'dbfilename\' configuration directive. 245 # 246 # The Append Only File will also be created inside this directory. 247 # 248 # Note that you must specify a directory here, not a file name. 249 dir /usr/local/redis/db/ 250 251 ################################# REPLICATION ################################# 252 253 # Master-Slave replication. Use slaveof to make a Redis instance a copy of 254 # another Redis server. A few things to understand ASAP about Redis replication. 255 # 256 # 1) Redis replication is asynchronous, but you can configure a master to 257 # stop accepting writes if it appears to be not connected with at least 258 # a given number of slaves. 259 # 2) Redis slaves are able to perform a partial resynchronization with the 260 # master if the replication link is lost for a relatively small amount of 261 # time. You may want to configure the replication backlog size (see the next 262 # sections of this file) with a sensible value depending on your needs. 263 # 3) Replication is automatic and does not need user intervention. After a 264 # network partition slaves automatically try to reconnect to masters 265 # and resynchronize with them. 266 # 267 # slaveof <masterip> <masterport> 268 269 # If the master is password protected (using the "requirepass" configuration 270 # directive below) it is possible to tell the slave to authenticate before 271 # starting the replication synchronization process, otherwise the master will 272 # refuse the slave request. 273 # 274 # masterauth <master-password> 275 276 # When a slave loses its connection with the master, or when the replication 277 # is still in progress, the slave can act in two different ways: 278 # 279 # 1) if slave-serve-stale-data is set to \'yes\' (the default) the slave will 280 # still reply to client requests, possibly with out of date data, or the 281 # data set may just be empty if this is the first synchronization. 282 # 283 # 2) if slave-serve-stale-data is set to \'no\' the slave will reply with 284 # an error "SYNC with master in progress" to all the kind of commands 285 # but to INFO and SLAVEOF. 286 # 287 slave-serve-stale-data yes 288 289 # You can configure a slave instance to accept writes or not. Writing against 290 # a slave instance may be useful to store some ephemeral data (because data 291 # written on a slave will be easily deleted after resync with the master) but 292 # may also cause problems if clients are writing to it because of a 293 # misconfiguration. 294 # 295 # Since Redis 2.6 by default slaves are read-only. 296 # 297 # Note: read only slaves are not designed to be exposed to untrusted clients 298 # on the internet. It\'s just a protection layer against misuse of the instance. 299 # Still a read only slave exports by default all the administrative commands 300 # such as CONFIG, DEBUG, and so forth. To a limited extent you can improve 301 # security of read only slaves using \'rename-command\' to shadow all the 302 # administrative / dangerous commands. 303 slave-read-only yes 304 305 # Replication SYNC strategy: disk or socket. 306 # 307 # ------------------------------------------------------- 308 # WARNING: DISKLESS REPLICATION IS EXPERIMENTAL CURRENTLY 309 # ------------------------------------------------------- 310 # 311 # New slaves and reconnecting slaves that are not able to continue the replication 312 # process just receiving differences, need to do what is called a "full 313 # synchronization". An RDB file is transmitted from the master to the slaves. 314 # The transmission can happen in two different ways: 315 # 316 # 1) Disk-backed: The Redis master creates a new process that writes the RDB 317 # file on disk. Later the file is transferred by the parent 318 # process to the slaves incrementally. 319 # 2) Diskless: The Redis master creates a new process that directly writes the 320 # RDB file to slave sockets, without touching the disk at all. 321 # 322 # With disk-backed replication, while the RDB file is generated, more slaves 323 # can be queued and served with the RDB file as soon as the current child producing 324 # the RDB file finishes its work. With diskless replication instead once 325 # the transfer starts, new slaves arriving will be queued and a new transfer 326 # will start when the current one terminates. 327 # 328 # When diskless replication is used, the master waits a configurable amount of 329 # time (in seconds) before starting the transfer in the hope that multiple slaves 330 # will arrive and the transfer can be parallelized. 331 # 332 # With slow disks and fast (large bandwidth) networks, diskless replication 333 # works better. 334 repl-diskless-sync no 335 336 # When diskless replication is enabled, it is possible to configure the delay 337 # the server waits in order to spawn the child that transfers the RDB via socket 338 # to the slaves. 339 # 340 # This is important since once the transfer starts, it is not possible to serve 341 # new slaves arriving, that will be queued for the next RDB transfer, so the server 342 # waits a delay in order to let more slaves arrive. 343 # 344 # The delay is specified in seconds, and by default is 5 seconds. To disable 345 # it entirely just set it to 0 seconds and the transfer will start ASAP. 346 repl-diskless-sync-delay 5 347 348 # Slaves send PINGs to server in a predefined interval. It\'s possible to change 349 # this interval with the repl_ping_slave_period option. The default value is 10 350 # seconds. 351 # 352 # repl-ping-slave-period 10 353 354 # The following option sets the replication timeout for: 355 # 356 # 1) Bulk transfer I/O during SYNC, from the point of view of slave. 357 # 2) Master timeout from the point of view of slaves (data, pings). 358 # 3) Slave timeout from the point of view of masters (REPLCONF ACK pings). 359 # 360 # It is important to make sure that this value is greater than the value 361 # specified for repl-ping-slave-period otherwise a timeout will be detected 362 # every time there is low traffic between the master and the slave. 363 # 364 # repl-timeout 60 365 366 # Disable TCP_NODELAY on the slave socket after SYNC? 367 # 368 # If you select "yes" Redis will use a smaller number of TCP packets and 369 # less bandwidth to send data to slaves. But this can add a delay for 370 # the data to appear on the slave side, up to 40 milliseconds with 371 # Linux kernels using a default configuration. 372 # 373 # If you select "no" the delay for data to appear on the slave side will 374 # be reduced but more bandwidth will be used for replication. 375 # 376 # By default we optimize for low latency, but in very high traffic conditions 377 # or when the master and slaves are many hops away, turning this to "yes" may 378 # be a good idea. 379 repl-disable-tcp-nodelay no 380 381以上是关于mac搭建redis环境的主要内容,如果未能解决你的问题,请参考以下文章
全新安装Mac OSX 开发者环境 同时使用homebrew搭建 PHP,Nginx ,MySQL,Redis,Memcache ... ... (LNMP开发环境)