mysql优化
Posted 开拖拉机的蜡笔小新
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql优化相关的知识,希望对你有一定的参考价值。
对于一个以数据为中心的应用,数据库的好坏直接影响到程序的性能,因此数据库性能至关重要。一
般来说,要保证数据库的效率,要做好以下四个方面的工作:
① 数据库设计
② sql语句优化
③ 数据库参数配置
④ 恰当的硬件资源和操作系统
这个顺序也表现了这四个工作对性能影响的大小
1.
通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解):
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;(只要是关系型数据库都满足1NF)
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识(设置主键),即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即我们的字段信息可以通过关联的关系,派生即可.(通常我们通过外键来处理)
但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。
具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
适当的逆范式:

想要既查询到图片的点击次数,也可以查询相册被点击的次数。单纯在photos表中设置一个hits属性确实是符合3范式的,但是在
查询相册被点击的次数时,需要查询所有albumid为1的相册,然后将点击的次数相加,每次这样的查询效率是相当低的。那么不如在
相册表中设置一个hits属性,虽然违反了第三范式冗余了,但是效率大大提高了。
错误的逆范式:

sql语句的优化

面试题 :sql语句有几类
ddl (数据定义语言) [create alter drop]
dml(数据操作语言)[insert delete upate ]
select
dtl(数据事务语句) [commit rollback savepoint]
dcl(数据控制语句) [grant revoke]
mysql客户端连接成功后,通过使用show [session|global] status 命令可以提供服务器状态信息。
其中的session来表示当前的连接的统计结果,global来表示自数据库上次启动至今的统计结果。默认是session级别的。
下面的例子:
show status like ‘Com_%’;
其中Com_XXX表示XXX语句所执行的次数。
重点注意:Com_select,Com_insert,Com_update,Com_delete通过这几个参数,
可以容易地了解到当前数据库的应用是以插入更新为主还是以查询操作为主,以及各类的SQL大致的执行比例是多少。
还有几个常用的参数便于用户了解数据库的基本情况。
Connections:试图连接MySQL服务器的次数
Uptime:服务器工作的时间(单位秒)
Slow_queries:慢查询的次数 (默认是10)
这里我们优化的重点是在 慢查询. (在默认情况下是10 )
显示查看慢查询默认时间的情况:show variables like \'long_query_time\';
为了测试,我们搞一个海量表(mysql存储过程)
目的,就是看看怎样处理,在海量表中,查询的速度很快!
首先我们先建一个海量测试表:
压力测试sql脚本,生成1800000条的海量数据:


#创建表DEPT
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
ename VARCHAR(20) NOT NULL DEFAULT "",
job VARCHAR(9) NOT NULL DEFAULT "",
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
hiredate DATE NOT NULL,
sal DECIMAL(7,2) NOT NULL,
comm DECIMAL(7,2) NOT NULL,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
# 随机产生字符串
#定义一个新的命令结束符合,为了后面存储过程能够正常执行,不把;作为结束符
delimiter $$
#这里我创建了一个函数.
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100) default
\'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ\';
declare return_str varchar(255) default \'\';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
select rand_string(6);
# 随机产生部门编号
delimiter $$
#这里我们又自定了一个函数
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
select rand_num();
#******************************************
#向emp表中插入记录(海量的数据)
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i) ,rand_string(6),\'SALESMAN\',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
#调用刚刚写好的函数, 1800000条记录,从100001号开始
call insert_emp(100001,1800000);
#**************************************************************
# 向dept表中插入记录
delimiter $$
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into dept values ((start+i) ,rand_string(10),rand_string(8));
until i = max_num
end repeat;
commit;
end $$
delimiter ;
call insert_dept(100,10);
#------------------------------------------------
#向salgrade 表插入数据
delimiter $$
create procedure insert_salgrade(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
ALTER TABLE emp DISABLE KEYS;
repeat
set i = i + 1;
insert into salgrade values ((start+i) ,(start+i),(start+i));
until i = max_num
end repeat;
commit;
end $$
delimiter ;
#测试不需要了
#call insert_salgrade(10000,1000000);
#----------------------------------------------
现在将慢查询的时间改为0.2s,set long_query_time=0.2;
(这种设置只是本次连接有效,设置永久有效需要再配置文件my.ini)
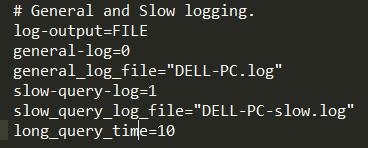
执行查找:select * from emp where empno=123456; 花费0.281s
查询慢查询的次数:show status like \'Slow_queries\';
可见慢查询的次数已经为1.
查找:show variables like \'%quer%\';
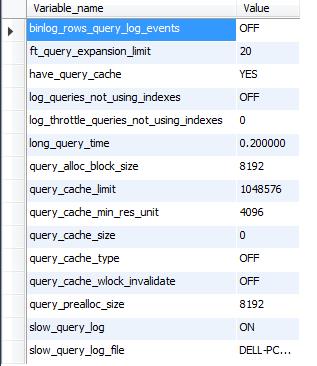
可以查看查找的相关设置信息,从中可以看见show_query_log慢查询日志记录已经开启,记录的信息如下。

现在我们优化:加索引(性价比高,不需要开辟新的内存)
索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行个正确的’create index’,
查询速度就可能提高百倍千倍,这可真有诱惑力。
可是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的(因为要维护索引信息文件),这些写操作,增加了大量的I/O。
(四种索引)
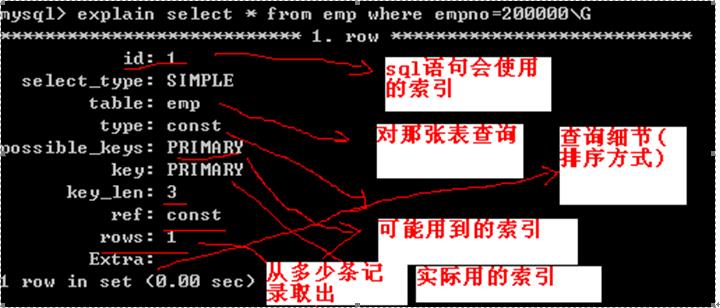
在emp表的 empno建立索引.
alter table emp add primary key(empno);
建索引之前:

建索引之后:

可看见.MYI索引文件变得非常大。
再次查询:

耗时0s,可见速度提高飞速。
索引的原理:
为什么加了索引速度变快?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。在没有索引的情况下,数据库会遍历全部数据后选择符合条件的;
而有了相应的索引之后,数据库会直接在索引中查找符合条件的选项。
索引的代价:
1.磁盘占用(生成索引文件)
2.对dml(update delete insert )语句的效率影响
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
介绍一款非常重要工具 explain, 这个分析工具可以对 sql语句进行分析,可以预测你的sql执行的效率.
他的基本用法是:
explain sql语句\\G (\\G可以使得显示呈列,便于查看 )
//根据返回的信息,我们可知,该sql语句是否使用索引,从多少记录中取出(rows,正是因为建立索引只需要从一个记录中取出),可以看到排序的方式.
删除索引后:
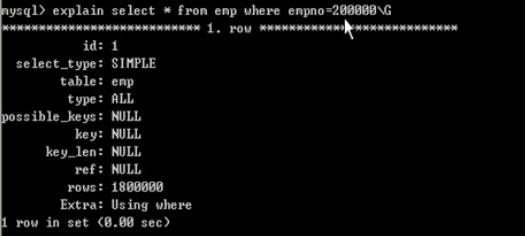


在一列上建立索引后只会在查询这一列的时候提高速度,但是其他列查询的速度不变。
在什么列上添加索引比较合适?
① 在经常查询的列上加索引.
② 列的数据,内容就只有少数几个值,不太适合加索引.
③ 内容频繁变化,不合适加索引
下列几种情况下有可能使用到索引:
1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。

只对左边的列建立的索引:

2,对于使用like的查询,查询如果是 ‘%aaa’ 不会使用到索引
‘aaa%’ 会使用到索引。
下列的表将不使用索引:
1,如果条件中有or,即使其中有条件带索引也不会使用。
2,对于多列索引,不是使用的第一部分,则不会使用索引。
3,like查询是以%开头
4,如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
5,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
如何检测你的索引是否有效
show status like \'Handler_read%\';

![]()
结论: Handler_read_key 越大越少
Handler_read_rnd_next 越小越好
MyISAM 和 Innodb区别
- MyISAM 不支持外键, Innodb支持
- MyISAM 不支持事务, Innodb支持.
- 对数据信息的存储处理方式不同.(如果存储引擎是MyISAM的,则创建一张表,对于三个文件.frm .myd .myi, 如果是Innodb则只有一张文件 *.frm,数据存放到ibdata1)
- MyISAM:默认的MySQL存储引擎。如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高。其优势是访问的速度快。
- InnoDB:提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM,写的处理效率差一些并且会占用更多的磁盘空间。
对于 MyISAM 数据库,删除数据信息,只删掉内容,但是不释放空间。需要定时对表进行碎片整理清理。
optimize table 表名
以下是MYISAM和Innodb在优化上的策略:
innoDB是mysql引擎中唯一支持事务transaction的引擎。默认所有用户行为都在事务内发生。
默认mysql建立新连接时,innoDB采用自动提交autocommit模式,每个SQL语句在它自己上形成一个单独的事务,即insert一次就commit了一次,InnoDB在该事务提交时必须刷新日志到磁盘,因此效率受限于磁盘读写效率。
你可以通过关闭自动提交模式。
如果你的表有索引,索引会拖慢insert速度。大量插入数据时,可以先关闭索引,然后再重建索引。
对于myisam表,常见优化方法如下:
1、禁用索引
对于非空表,插入记录时,mysql会根据表的索引对插入的记录建立索引。如果插入大量数据,建立索引会降低插入记录的速度。
为了解决这个问题,可以在插入记录之前禁用索引,数据插入完毕后再开启索引
禁用索引语句如下:
ALTER TABLE table_name DISABLE KEYS ;
其中table_name是禁用索引的表的表名
重新开启索引语句如下:
ALTER TABLE table_name ENABLE KEYS ;
对于空表批量导入数据,则不需要进行此操作,因为myisam表是在导入数据之后才建立索引!
2、禁用唯一性检查
插入数据时,mysql会对插入的记录进行唯一性校验。这种唯一性校验也会降低插入记录的速度。
为了降低这种情况对查询速度的影响,可以在插入记录之前禁用唯一性检查,等到记录插入完毕之后再开启
禁用唯一性检查的语句如下:
SET UNIQUE_CHECKS=0;
开启唯一性检查的语句如下:
SET UNIQUE_CHECKS=1;
3、使用批量插入
插入多条记录时,可以使用一条INSERT语句插入一条记录,也可以使用一条INSERT语句插入多条记录。
第一种情况
INSERT INTO emp(id,name) VALUES (1,\'suse\'); INSERT INTO emp(id,name) VALUES (2,\'lily\'); INSERT INTO emp(id,name) VALUES (3,\'tom\');
第二种情况
INSERT INTO emp(id,name) VALUES (1,\'suse\'),(2,\'lily\'),(3,\'tom\')
第二种情况要比第一种情况要快
4、使用LOAD DATA INFILE批量导入
当需要批量导入数据时,如果能用LOAD DATA INFILE语句,就尽量使用。因为LOAD DATA INFILE语句导入数据的速度比INSERT语句快很多
对于INNODB引擎的表,常见的优化方法如下:
1、禁用唯一性检查
插入数据时,mysql会对插入的记录进行唯一性校验。这种唯一性校验也会降低插入记录的速度。
为了降低这种情况对查询速度的影响,可以在插入记录之前禁用唯一性检查,等到记录插入完毕之后再开启
禁用唯一性检查的语句如下:
SET UNIQUE_CHECKS=0;
开启唯一性检查的语句如下:
SET UNIQUE_CHECKS=1;
2、禁用外键约束
插入数据之前执行禁止对外键的检查,数据插入完成之后再恢复对外键的检查。禁用外键检查的语句如下:
SET FOREIGN_KEY_CHECKS=0;
恢复对外键的检查语句如下
SET FOREIGN_KEY_CHECKS=1;
3、禁止自动提交
插入数据之前禁止事务的自动提交,数据导入完成之后,执行恢复自动提交操作
或显式指定事务
USE test; START TRANSACTION; INSERT INTO emp(name) VALUES(\'ming\'); INSERT INTO emp(name) VALUES(\'lily\'); commit;
优化group by 语句
默认情况,MySQL对所有的group by col1,col2进行排序。
这与在查询中指定order by col1, col2类似。
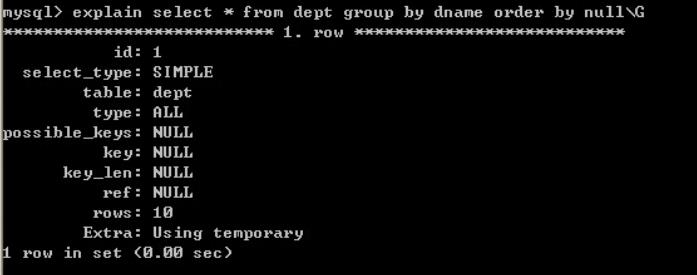
如果查询中包括group by但用户想要避免排序结果的消耗,则可以使用order by null禁止排序
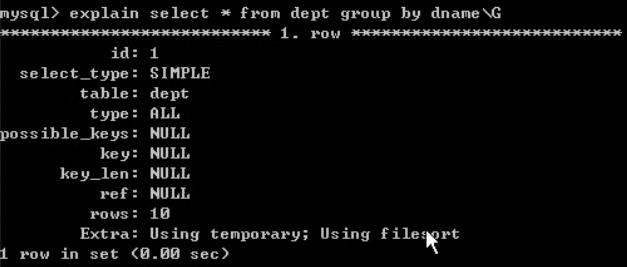
不再使用文件排序:
有些情况下,可以使用连接来替代子查询。
因为使用join,MySQL不需要在内存中创建临时表。
如果想要在含有or的查询语句中利用索引,则or之间的每个条件列都必须用到索引,如果没有索引,则应该考虑增加索引或者使用union all操作。
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
选择合适的数据类型:
在精度要求高的应用中,建议使用定点数(decimal)来存储数值,以保证结果的准确性
1000000.32 万
create table sal(t1 float(10,2));
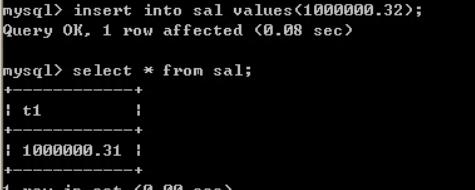
可见存的结果不准确。用decimal存之后:
create table sal2(t1 decimal(10,2));

表的划分
对表水平划分:
如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了。
如果我拆成100个表,那么每个表只有10万条记录。当然这 需要数据在逻辑上可以划分。
一个好的划分依据,有利于程序的简单实现,也可以充分利用水平分表的优势。比如系统界面上只提供按月查询的功能,那么把表按月 拆分成12个,每个查询只查询一个表就了。
如果非要按照地域来分,即使把表拆的再小,查询还是要联合所有表来查,还不如不拆了。所以一个好的拆分依据是 最重要的。(UNION)
对表进行垂直划分:
有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O,严重降低了性能。
这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。 (JOIN)
联合查询(union)和连接查询(join)恰好表达了这两种方式的用法。
数据库参数配置
最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大
innodb_additional_mem_pool_size = 64M innodb_buffer_pool_size =1G
对于myisam,需要调整key_buffer_size 当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定改调整哪些参数
读写分离技术
如果数据库压力很大,一台机器支撑不了,那么可以用mysql复制实现多台机器同步,将数据库的压力分散。
基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中 的从数据库。

以上是关于mysql优化的主要内容,如果未能解决你的问题,请参考以下文章