关于MySQL的commit非规律性失败案例的深入分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于MySQL的commit非规律性失败案例的深入分析相关的知识,希望对你有一定的参考价值。
案例描述:
一个普通的事务提交,在应用里面会提示commit超时,失败。
一、理论知识
1、关于commit原理,事务提交过程
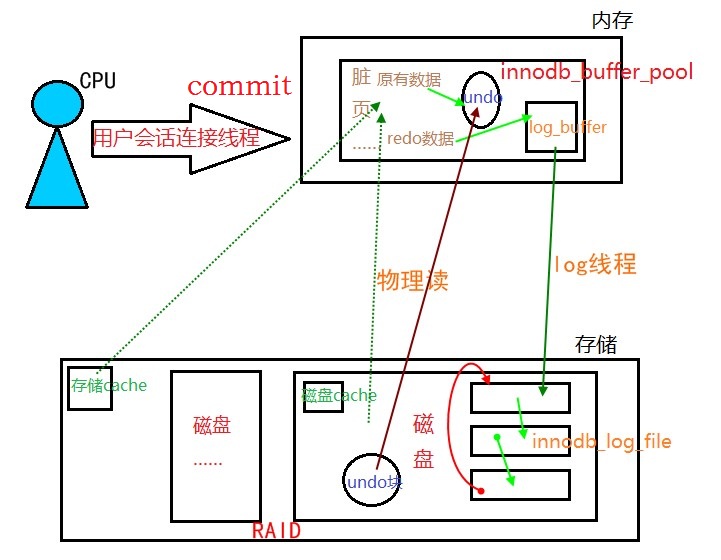
1、寻找修改的数据页:
1、如果该数据页在内存中,则直接是内存读;
2、如果该数据页内存中没有,物理读,就从磁盘调入内存;
2、磁盘中的undo页调入内存;
3、先将原来的数据存入undo,然后修改数据(数据页成脏页);
4、修改数据的信息生成redo数据存入log_buffer(内存中的一个空间,默认16M)中;
mysql> show variables like \'%log_buffer%\';
+------------------------+----------+
| Variable_name | Value |
+------------------------+----------+
| innodb_log_buffer_size | 16777216 |
+------------------------+----------+
1 row in set (0.01 sec)
5、log_buffer通过log线程(后台线程,非常勤快),持续不断的将redo信息写入disk的innodb_log_file中;
mysql> show variables like \'innodb_log_file%\';
+---------------------------+----------+
| Variable_name | Value |
+---------------------------+----------+
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
+---------------------------+----------+
2 rows in set (0.01 sec)
6、事务提交,刻意触发log线程,将剩余的log_buffer中的redo数据信息写入磁盘中,数据量已剩不多,写完提交成功。
注意:
1、修改记录前,一定要先写日志;
“日志先行”,这是数据库最基本的原则。
2、事务提交过程中,一定要保证日志先落盘,才能算事务提交完成。
3、意外掉电,内存脏页丢失,但是磁盘的innodb_log_file中存放了redo日志信息,待重启服务器,MySQL通过读取磁盘的log_files数据,自动将数据的修改重新跑一边。
Q:为什么mysql commit速度总是很快,尽管事务修改的数据量可能很大?
A:
因为事务提交,并不是对磁盘数据进行修改,而是将修改数据的redo信息通过后台log线程写入磁盘的redo logfile中,完成mysql commit,无论事务修改的数据量有多大,这个过程速度是很快的。
而内存中的脏块,也就是修改后的数据页,正常情况下是由后台相关write线程周期性的将脏页数据刷入磁盘中,保证innodb buffer pool有足够的干净块、可用块。
2、关于rollback原理,回滚过程
1、MySQL读取内存中undo页信息
2、通过undo信息找到脏页,反着对数据进行修改
3、do、undo的时间相同,且都会产成redo信息
4、事务提交
MySQL回滚处理机制:
如果线程中断,事务没有提交,undo会将记录此信息,待另一会话进程连上,查看该块数据信息,MySQL自动回滚进行数据页修改,然后被读取。也就是说为了避免系统因为rollback被hang住,通过直接杀死进程的方式,中断事务,等待后来者要读取该数据信息时进行回滚,再返回结果。
Q:rollback为什么有时候很慢,rollback的风险和风险避免方式?
A:
rollback的时间取决于回滚前事务修改数据的时间,处理量大回滚时间长,处理量小回滚时间短。
1、rollback风险:容易导致系统被hang住;
2、风险避免方式:直接杀死会话进程或是mysql进程。
3、存储写入性能分析
Q:mysql commit,存储为什么写速度能够保持在0ms,极少出现1ms情况?
A:
对于存储来说,写性能相当高:假设存储cache总有空闲空间的情况下,事务提交,将log buffer中剩余的很少的redo数据写入存储cache,即为完成mysql commit,这个过程是相当快的(能够保持在0ms,极少出现1ms情况),后续redo数据由cache写入磁盘的过程是后台进行。
4、存储级别的灾备(同城灾备)
1、灾备同步过程:commit
1、redo、binlog写入本地存储cache;
2、通过网络同步binlog写入远端同步的服务器的存储cache中;
3、响应本地数据库;
4、事务提交成功;
2、风险:
网络出现问题(信号断续,缆线断了),导致写hang住,commit超时失败。
3、解决:
通过超时设置,网络中断超过限制,自动将同步改为灾备异步,尽可能少的影响业务commit超时失败。
二、分析与处理
存储写性能比较差,很多时段会达到5ms,甚至于10ms以上
备注:灾备同步已经停止的情况下。
1、存储中BBU问题,出现监控BBU的bug;
解决:重启BBU,不行就更新BBU。
2、cache被占满
1、海量数据写入,commit数据占满cache;
2、硬盘I/O异常,异常SQL导致的海量物理读;
解决:索引优化。
3、存储性能差
解决:找老板掏钱,更换优质设备。
以上是关于关于MySQL的commit非规律性失败案例的深入分析的主要内容,如果未能解决你的问题,请参考以下文章