hadoop学习之HDFS
Posted 小虾米的java梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop学习之HDFS相关的知识,希望对你有一定的参考价值。
1、什么是大数据?什么是云计算?什么是hadoop?
大数据现在很火,到底什么是大数据,多大的数据才算大,一般而言对于TB级以上的数据我们成为大数据,对于这些数据它的价值在哪?大数据的价值就是我们大量的数据中分析出有价值的信息,来判断一些行为等等信息。而这些大数据存储在哪?如何进行分析?这就衍生了Hadoop。
云计算是什么?通俗的说云计算就是大规模的计算机集群(即多台服务器集群),我们通过软件将这些计算机整合起来,根据需求根据用户来提供服务。比如进行一些数据的计算分析。用来提高工作效率。(这是目前理解的,后面有深入再写)
什么是hadoop?通俗的说,hadoop就是对大数据进行处理的一个工具。利用它我们可以对数据的管理,主要有两方面:数据存储(HDFS)和数据计算(MapReduce、spark、storm),所以我们简单理解为一个数据处理工具即可。
2、什么是HDFS?
刚上面说了HDFS是hadoop中负责对数据进行存储相当于的一个功能模块吧,总的来说,HDFS是一个分布式的文件系统,它可以无限制的存放大量的文件,这些文件分布式的存放在HDFS中,具有高容错、批处理的特点。
3、HDFS的原理?
HDFS的设计思想:
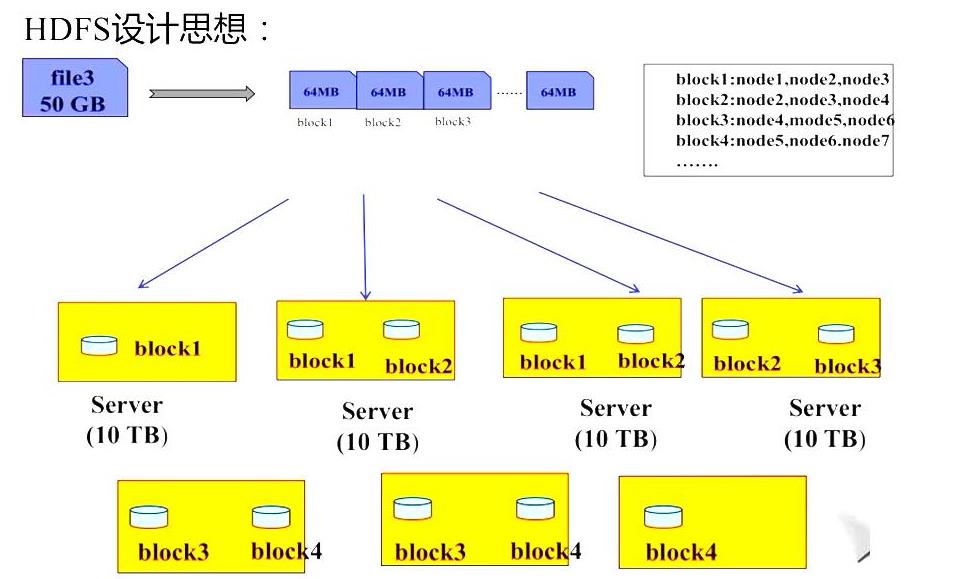
名称解释:
NN: namenode节点:作用:接收来自客户端是读写数据;存放元数据:元数据包括fsimage(格式化的时候产生)和editslog(对元数据进行CRUD的时候产生的日志文件)。
SNN: SecondaryNameNode:作用是协助NN完成元数据的更新操作。
DN:DataNode:数据节点:这里是存放数据的核心位置。DN会不停的向NN发送心跳,用于NN检测DN是否处于活动状态,有没有宕机。
大数据的存储是以块(block)来存储的,每个block默认有三个副本,这三个副本必须存放在不同的节点机器上,即三个不同的计算机。所以DN至少三台。一个DN上面可以存放多个不同的block块,DN的数量必须大于等于block的数量。
SNN合并图:
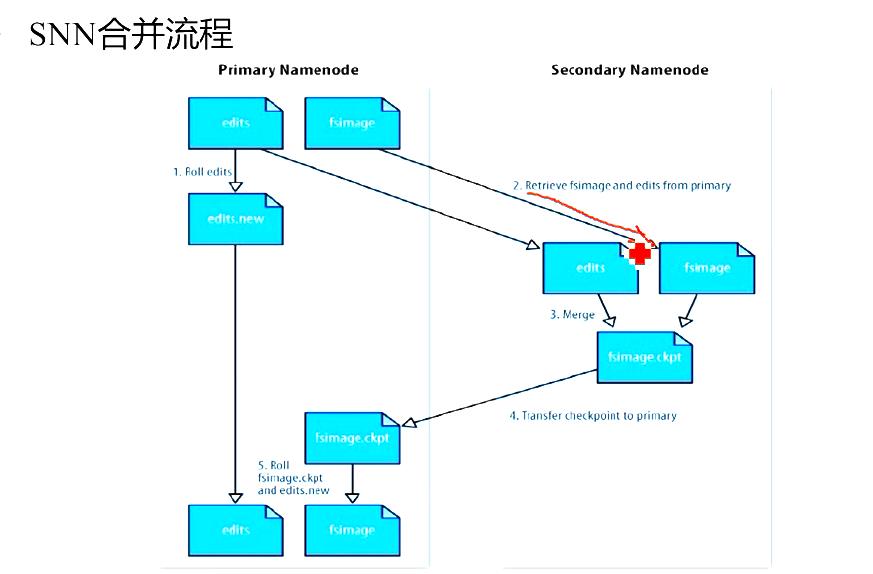
我们根据图来分析:
HDFS写流程:


4、HDFS如何搭建集群
前提:在进行各项试验之前,各个节点切换到root用户下,将防火墙关闭。 chkconfig iptables off
centos中搭建集群的步骤:
搭建集群的环境,我们首先准备四个节点机器,一个用来作为NN,一个用来作为SNN,DN,另外两台作为DN .
(1)设置每个节点机器的ssh 免密码登录。
(2)设置NN上面可以免密码登录其余各个节点机器。(将NN的公钥复制给其余节点,其余节点授权NN可以登录自己)(SCP可以不同服务器直接互相传递文件的命令)
(3)解压hadoop后,
修改配置文件:这个可以参考hadoop的API:
修改hadoop-env.sh 文件配置jdk的路径
修改core-site.xml文件:配置NN的访问端口
修改hdfs-site.xml文件,配置SNN地址。
设置slaves中三台DN的节点位置
设置masters作为SNN的节点的位置。
(4)设置好后,复制hadoop到其余各个节点上面。
在NN上面启动hadoop:
start-dfs.sh 即可启动。
5、什么是HA?
HA是高可用,即整个集群的高可用性。
首先为什么会出现HA?
一个集群中只有能有个NN处于活动状态,可是当这个NN宕机了呢,这个集群就不可用了。方案:一主一备,主的宕机了,备的NN作为主的,接替主的位置。
高可用的原因:NN宕机,内存受限
名称解释:
ZK:zookeeper:可以理解为一个服务的管理者,这里主要负责管理主备的自动切换。
JN: journalNode:在HA高可用的集群中,SNN的作用由JN来代替了,JN主要用来负责记录edits文件,共享edits文件,合并edits文件,用来根据edits来合并NN Active 和NN standy 的源文件。
NN acitve:主节点。
NN standby: 备节点。在主节点处于活动状态时,备节点是不作用的。因为一个集群只有一个NN活动。
FileController: 这个文件主要配合zk来进行主备节点的自动切换。
上图分析:
HA原理:
基于QJM的HDFS HA方案如上图所示,其处理流程为:集群启动后一个NameNode处于Active状态,并提供服务,处理客户端和DataNode的请求,并把editlog写到本地和share editlog(这里是QJM)中。另外一个NameNode处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与Active节点的状态同步。为了实现Standby在Active挂掉后迅速提供服务,需要DataNode同时向两个NameNode汇报,使得Stadnby保存block to DataNode信息,因为NameNode启动中最费时的工作是处理所有DataNode的blockreport。为了实现热备,增加FailoverController和Zookeeper,FailoverController与Zookeeper通信,通过Zookeeper选举机制,FailoverController通过RPC让NameNode转换为Active或Standby。
HDFS HA通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
Hadoop 2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode,这里还配置了一个Zookeeper集群,用于ZKFC故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为Active状态。
YARN的ResourceManager也存在单点故障问题,这个问题在hadoop-2.4.1得到了解决:有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调。
YARN框架下的MapReduce可以开启JobHistoryServer来记录历史任务信息,否则只能查看当前正在执行的任务信息。
Zookeeper的作用是负责HDFS中NameNode主备节点的选举,和YARN框架下ResourceManaer主备节点的选举。

6、如何搭建高可用(HA)的HDFS?
centos搭建步骤:
搭建zk集群,搭建HA:
HDFS HA配置要素
NameNode机器:两台配置对等的物理机器,它们分别运行Active和Standby Node。
JouralNode机器:运行JouralNodes的机器。JouralNode守护进程相当的轻量级,可以和Hadoop的其他进程部署在一起,比如NameNode、DataNode、ResourceManager等,至少需要3个且为奇数,如果你运行了N个JNS,那么它可以允许(N-1)/2个JNS进程失效并且不影响工作。
在HA集群中,Standby NameNode还会对namespace进行checkpoint操作(继承Backup Namenode的特性),因此不需要在HA集群中运行SecondaryNameNode、CheckpointNode或者BackupNode。
HDFS HA配置参数
需要在hdfs.xml中配置如下参数:
dfs.nameservices:HDFS NN的逻辑名称,例如myhdfs。
dfs.ha.namenodes.myhdfs:给定服务逻辑名称myhdfs的节点列表,如nn1、nn2。
dfs.namenode.rpc-address.myhdfs.nn1:myhdfs中nn1对外服务的RPC地址。
dfs.namenode.http-address.myhdfs.nn1:myhdfs中nn1对外服务http地址。
dfs.namenode.shared.edits.dir:JournalNode的服务地址。
dfs.journalnode.edits.dir:JournalNode在本地磁盘存放数据的位置。
dfs.ha.automatic-failover.enabled:是否开启NameNode失败自动切换。
dfs.ha.fencing.methods :配置隔离机制,通常为sshfence。
HDFS自动故障转移
HDFS的自动故障转移主要由Zookeeper和ZKFC两个组件组成。
Zookeeper集群作用主要有:一是故障监控。每个NameNode将会和Zookeeper建立一个持久session,如果NameNode失效,那么此session将会过期失效,此后Zookeeper将会通知另一个Namenode,然后触发Failover;二是NameNode选举。ZooKeeper提供了简单的机制来实现Acitve Node选举,如果当前Active失效,Standby将会获取一个特定的排他锁,那么获取锁的Node接下来将会成为Active。
ZKFC是一个Zookeeper的客户端,它主要用来监测和管理NameNodes的状态,每个NameNode机器上都会运行一个ZKFC程序,它的职责主要有:一是健康监控。ZKFC间歇性的ping NameNode,得到NameNode返回状态,如果NameNode失效或者不健康,那么ZKFS将会标记其为不健康;二是Zookeeper会话管理。当本地NaneNode运行良好时,ZKFC将会持有一个Zookeeper session,如果本地NameNode为Active,它同时也持有一个“排他锁”znode,如果session过期,那么次lock所对应的znode也将被删除;三是选举。当集群中其中一个NameNode宕机,Zookeeper会自动将另一个激活。
HA集群启动:
首先启动zk集群,zkServer.sh start
启动hadoop集群: start-hdfs.sh
7.实验结果:
访问主NN的地址:node1:50070
访问备机:node5:50070
一个显示active 一个显示standby
当一个kill进程主机后,另外standby切换成active
说明:配置下各个节点的名称: 在etc下的hosts文件中添加ip 和节点名。

以上是关于hadoop学习之HDFS的主要内容,如果未能解决你的问题,请参考以下文章