ElasticSearch从0到1——基础知识
Posted binggetong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch从0到1——基础知识相关的知识,希望对你有一定的参考价值。
1.ES是什么?
- 是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据
- 使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
- 一个分布式、可扩展、近实时的搜索与数据分析引擎
我们看到ES定义中有2个词,来展开理解一下。
全文检索:
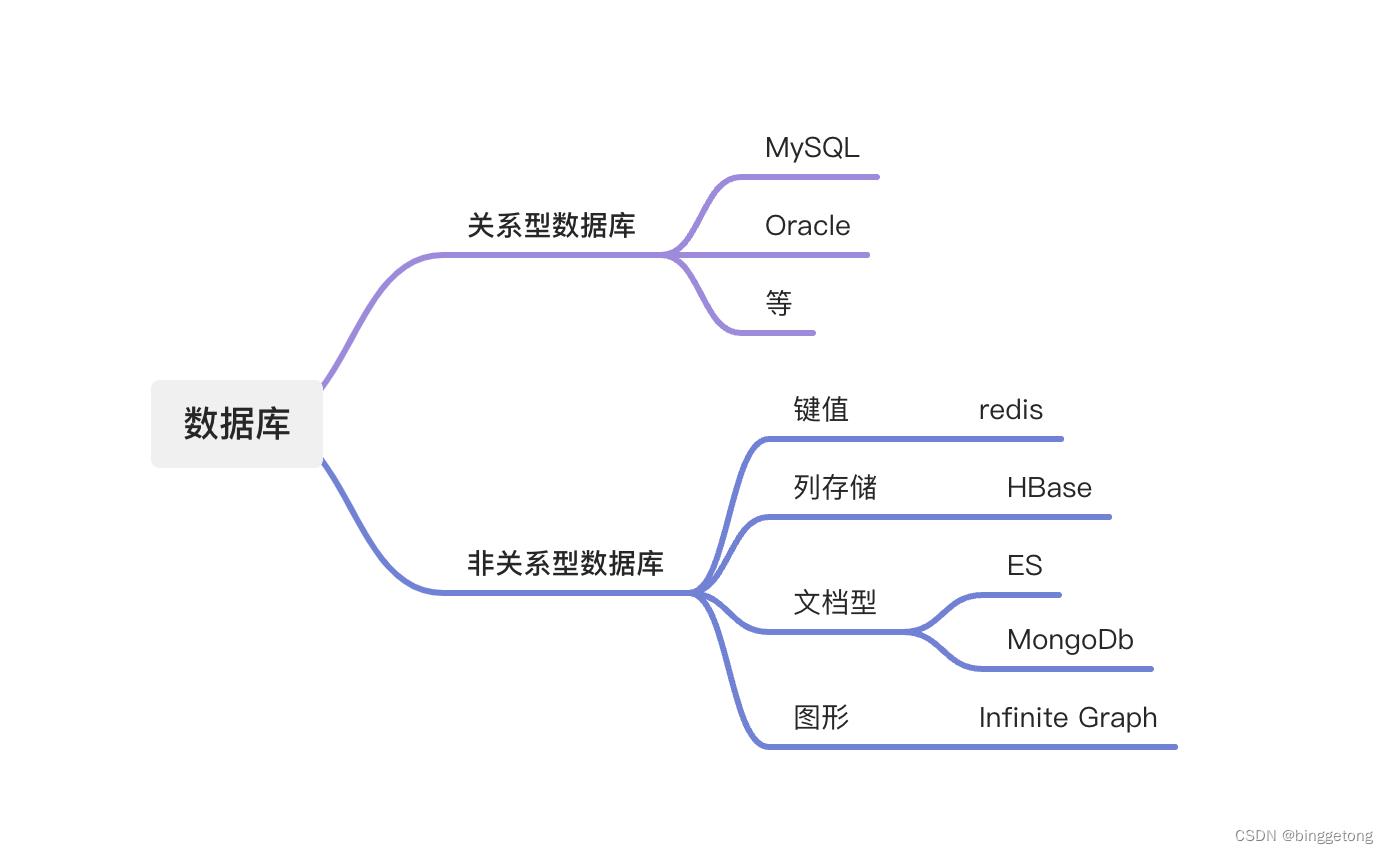
上面的列举了平时用的2种类型的数据库,对于关系型数据,都有一定的结构,比如我们可以通过建立索引来查询,那么对于非关系型数据库,我们经常使用的搜索方式主要有两种:顺序扫描和全文检索。
而全文检索,就是相当于把非结构化的数据,类比结构化的数据检索方式,把部分数据提取出来,提炼成有结构的数据,进行结构化的搜索,提高搜索效率,这就是全文检索的基本思路。
Lucene:
Lucene是apache软件基金会, jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
但是Lucene只是一个工具包,不是一个完整的全文搜索引擎。所以引出了我们今天的主题—— ES:
是在Lucene基础上的开源可用的全文搜索引擎。通过对 Lucene 的封装,隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
2.基本概念
学习一项新技术,最好的方式就是和原有的知识相结合,形成知识网络,也更容易理解。
下面以mysql和ES的对比来介绍ES中的一些基本概念。
| ES | Mysql |
| 索引index | 数据库db |
| 类型type | 表table |
| 文档doc | 每一条记录row |
| 字段field | 字段 column |
| 映射mapping | schema |
| Query DSL | sql |
不过在 6.x 版本后,就废弃了 Type ,因为设计者发现 ElasticSearch 这种与关系型数据类比的设计方式有缺陷。建议的是每个类型(业务)的数据单独放在一个索引中。
下面是ES介绍中分布式、可扩展、近实时的搜索与数据分析引擎的概念支撑
集群:Cluster,ES可以作为一个单个独立的搜索服务器,为了处理大型数据,实现容错和高可用,ES运行在多个互相合作的服务器上。这些服务器的集合,称为集群。
节点:Node,形成集群的每个服务器。
分片:Shard,每个索引默认被分成5片存储,每个分片都存在至少一个备份分片。当我们查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。
副本:replia,为提高查询吞吐量或实现高可用性,可以使用分片副本。注意,只有一个主分片,可以支持修改。其他副本只支持查询。
倒排索引==词典(内存中)+倒排文件(磁盘上)
类似于mysql里的like语句。把doc中存储的内容,按照词拆分成一个个词条(term),词条组合成词典,即词典=词条+指针。指针指向出现过的文档doc。
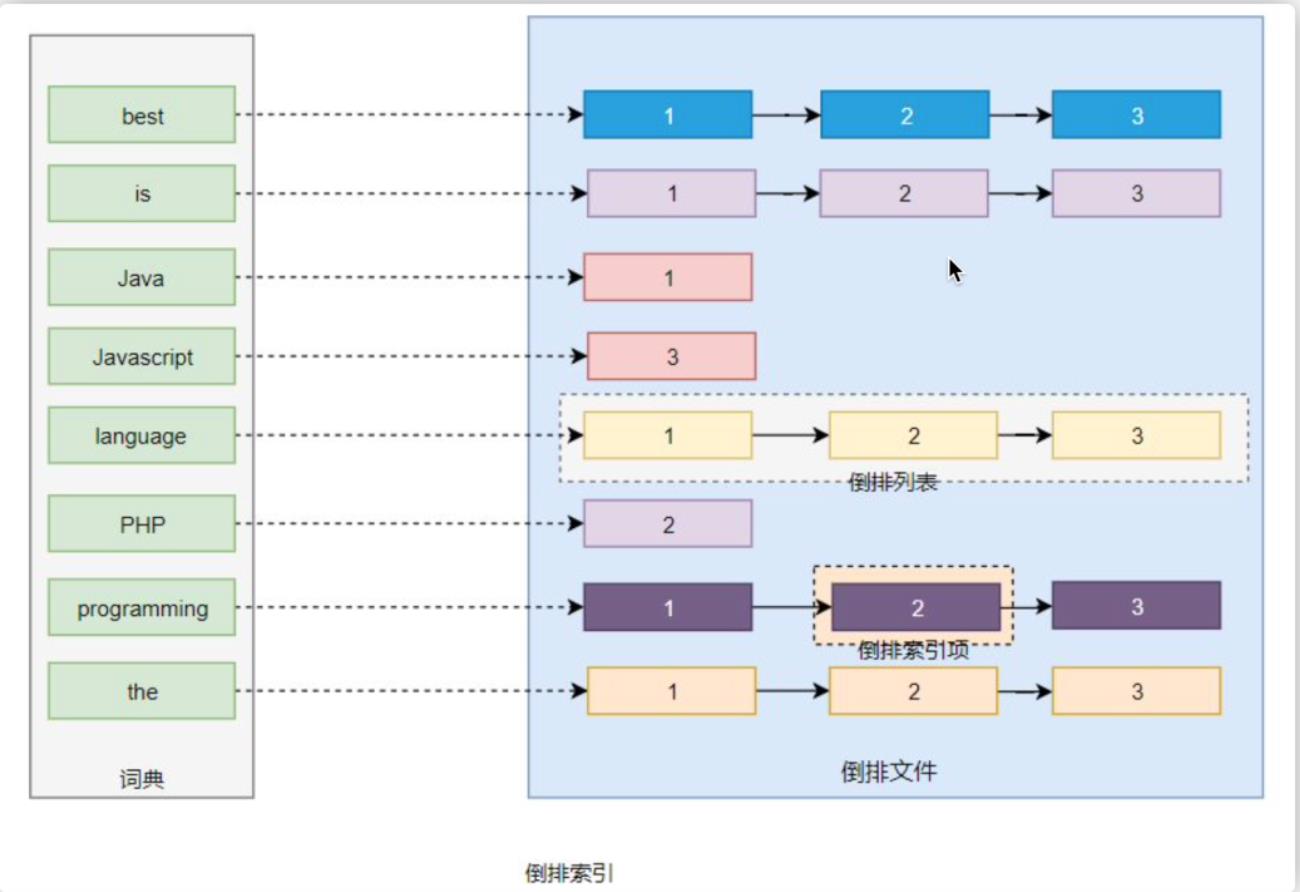
基础概念大概就这些。
下一篇会根据一个ES中存储的例子,来详细介绍下ES的使用。
荐参考资料:
以上是关于ElasticSearch从0到1——基础知识的主要内容,如果未能解决你的问题,请参考以下文章