自动驾驶决策概况
Posted yuan〇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶决策概况相关的知识,希望对你有一定的参考价值。
文章目录
1. 第一章行为决策在自动驾驶系统架构中的位置
Claudine Badue[1]等人以圣西班牙联邦大学(UFES)开发的自动驾驶汽车(Intelligent Autonomous Robotics Automobile,IARA)为例,提出了自动驾驶汽车的自动驾驶系统的典型架构。如图所示,自动驾驶系统主要由感知系统(Perception System)和规划决策系统(Decision Making System)组成。感知系统主要由交通信号检测模块(Traffic Signalization Detector,TSD)、移动目标跟踪模块(Moving Objects Tracker,MOT)、定位与建图模块(Localizer and Mapper)等组成。规划决策系统主要由全局路径规划模块(Route Planner)、局部路径规划模块(Path Planner)、行为决策模块(Behavior Selector)、运动规划模块(Motion Planner)、自主避障模块(Obstacle Avoider)以及控制模块(Controller)组成。
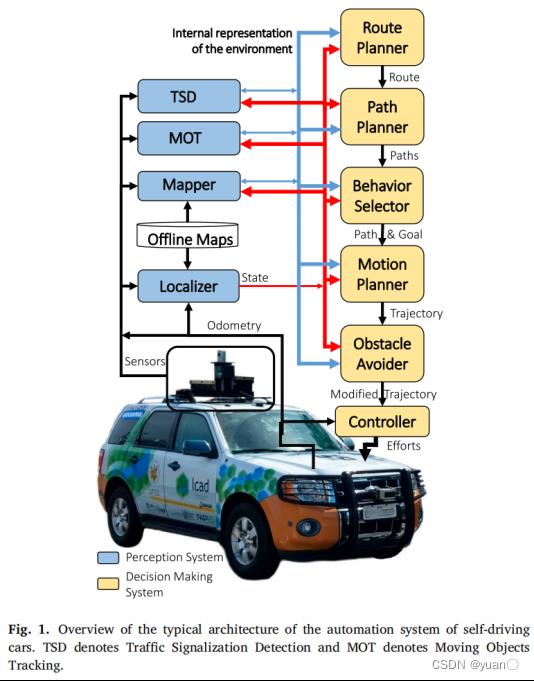
行为决策在此架构中主要是由行为决策模块完成的。行为决策模块负责选择当前的驾驶行为,如车道保持、十字路口处理、红绿灯处理等。该模块选取一组路径 P P P中的一条路径 p j p_j pj,以及 p j p_j pj中的一个位姿点 p g p_g pg,该位姿点大致位于汽车决策前的5s左右(这被称为决策视野),并设立目标速度与目标位姿 G o a l g = ( p g , v g ) Goal_g=(p_g,v_g) Goalg=(pg,vg)。行为决策模块选择一个考虑当前驾驶行为的目标路径,并在决策视野内避免与环境中静态和移动障碍物的碰撞。
2. 行为决策算法的种类
行为决策模块负责选择当前的驾驶行为,如车道保持、十字路口处理、红绿灯处理等。该模块选取一组路径 P P P中的一条路径 p j p_j pj,以及 p j p_j pj中的一个位姿点 p g p_g pg,该位姿点大致位于汽车决策前的5s左右(这被称为决策视野),并设立目标速度与目标位姿 G o a l g = ( p g , v g ) Goal_g=(p_g,v_g) Goalg=(pg,vg)。行为决策模块选择一个考虑当前驾驶行为的目标路径,并在决策视野内避免与环境中静态和移动障碍物的碰撞。
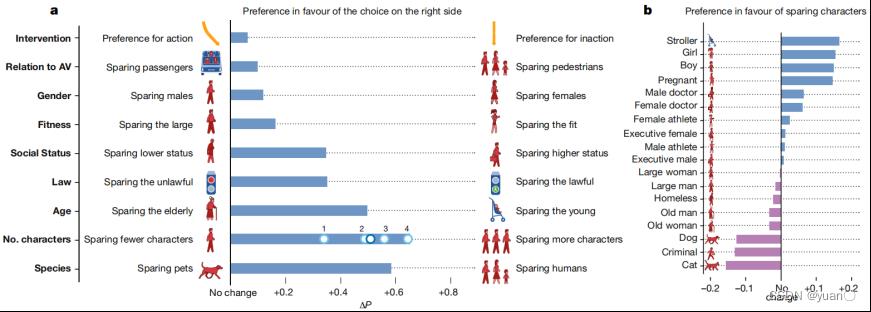
自动驾驶行为决策不得不考虑一些有关伦理道德的问题,例如,当自动驾驶汽车发生交通事故时,应该优先保护其他交通参与者——行人的安全还是优先保护自己车上乘客的安全?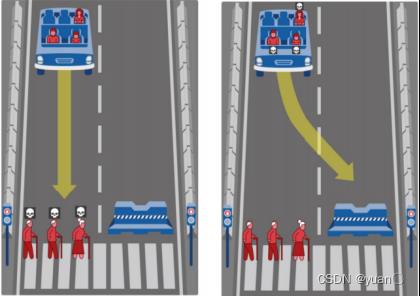
E. Awad团队 [2]通过从年龄、教育、性别、收入、政治和宗教等多个方面对调查人员进行标记,并统计他们的选择(选择左边代表优先保护乘客,选择右边代表优先保护行人)。据他们的统计发现,更多的人们倾向于保护行人,尤其是婴幼儿、男孩、女孩等未成年人。
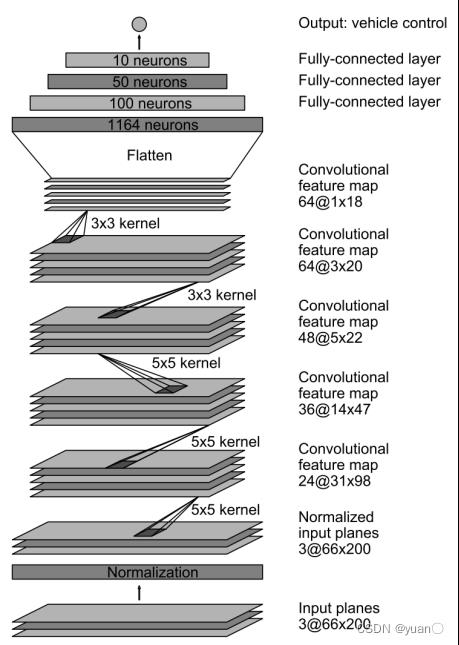
自动驾驶汽车必须处理各种道路和城市交通情况。许多文献将行为选择问题根据不同的交通场景进行划分,以便解决问题,这类方法成为集中式决策。集中式决策中主要有基于规则的决策算法和基于统计的决策算法。还有一些文献采用的是端到端的方法,例如使用CNN [3]来处理自动驾驶的相关问题。
在DARPA城市挑战赛,用于不同驾驶场景的主要方法有启发式组合法 [4]、决策树 [5,6]、有限状态机(FSM) [7]和贝叶斯网络 [5]。上述的这些方法在一些简单的、限定的场景里可以实现,表现良好,但对复杂场景,例如中高密度的城市路网交通流,算法的稳定性与适应性就稍欠理想。
此外,近年来,基于状态机的方法得到改进并与其他方法融合,以应对更多的真实城市交通场景,例如X. Han[8]等人在现有研究的基础上,提出了一种通过层次框架具有组织行为的综合多车道平台算法。该算法在战略任务层面上,开发了一种基于确定性有限状态机(FSM)的平台化行为协议来指导成员的操作。此外,他们以FSM为基线训练遗传模糊系统,以扩展算法在入口匝道合并场景下的能力。基于本体论[9](Ontologies-based)的方法同样也可以作为一个场景建模的工具。该方法主要基于知识库进行行为决策。
除此之外,一些方法考虑了决策过程中的其他交通参与者的决策意图以及运动轨迹的不确定性,例如马尔可夫决策过程[10](MDP)和部分可观察马尔可夫决策过程[11](POMDP)。
2.1 基于规则的决策算法
2.1.1 决策树
决策树是依据决策建立起来的、用来分类和决策的树结构。概括地说,决策树算法的逻辑可以描述为if-then, 根据样本的特征属性按照“某种顺序”排列成树形结构,将样本的属性取值按照if-then逻辑逐个自顶向下分类,最后归结到某一个确定的类中[5]。“某种顺序”是指决策树的属性选择方法。以二叉决策树为例,树形结构由结点和边组成,决策树的结点代表分类问题中样本的某个属性,边的含义为是与否两种情况,即样本属性取值是否符合当前分类依据。
决策树学习的关键在于选择划分属性。属性的选择流程可简略表述为:首先,计算训练样本中每个属性的“贡献度”,选择贡献最高的属性作为根结点。根结点下扩展的分支将依据根结点所代表属性的取值决定。然后,将已经被选择为结点的属性从候选属性集中剔除,接着不断重复进行候选属性集合中剩余属性的“贡献度”的计算和选择,直至达到预设的模型训练阈值(例如达到决策树最大深度)。最后,得到一棵能较好地拟合训练样本分布的决策树模型。
常见的决策树算法有以下三种:
- ID3(iterative dichotomiser 3)算法:
信息增益大的属性优先。首先,计算所有候选属性的信息增益,选择其中信息增益最大的属性作为根结点。然后,按照根结点所代表属性的取值决定分支情况。其次,将已选择属性从候选集中删除,并计算剩余属性的信息增益。最后,选择信息增益最大的结点作为子结点,直至所有属性都已选择。信息熵是用来衡量样本纯度指标的,是计算信息增益的前提,定义为:
E
n
t
(
D
)
=
−
∑
K
=
1
∣
K
∣
p
k
log
2
p
k
Ent(D) = - \\sum\\limits_K = 1^\\left| K \\right| p_k\\log _2p_k
Ent(D)=−K=1∑∣K∣pklog2pk式中
D
D
D——样本集合; 以上是关于自动驾驶决策概况的主要内容,如果未能解决你的问题,请参考以下文章
p
k
——
D
p_k——D
pk——D中第
k
k
k类样本所占的比例,其计算方式为:
p
k
=
∣
C
k
∣
∣
D
∣
p_k = \\frac\\left| C_k \\right|\\left| D \\right|
pk=∣D∣∣Ck∣式中
C
k
C_k
Ck——集合D中属于第k类样本的样本子集。
假设
D
D
D中某个具有
V
V
V个取值的属性为
A
A
A,取值分别为
a
1
,
a
2
,
…
,
a
V
a_1,a_2,…,a_V
a1,a2,…,aV。根据不同的取值将
D
D
D中的样本划分为
V
V
V个子集。其中,取值为
a
v
a_v
av的样本属于第
v
v
v个子集,记作
D
v
D_v
Dv。
根据式(2-1)可以计算出样本
D
v
D_v
Dv的信息熵。通过增加各分支权重
∣
D
v
∣
/
∣
D
∣
|D_v|/|D|
∣Dv∣/∣D∣使样本数量多的结点具有更大的“影响”。首先,计算属性
A
A
A对于数据集
D
D
D的条件熵
E
n
t
(
D
∣
A
)
Ent(D|A)
Ent(D∣A):
E
n
t
(
D
∣
A
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
(
∑
k
=
1
K
∣
D
v
k
∣
∣
D
v
∣
log
2
∣
D
v
k
∣
∣
D
v
∣
)
\\beginarraycEnt(D|A) = \\sum\\limits_v = 1^V \\frac\\left| D^v \\right|\\left| D \\right| Ent(D^v)\\\\ = - \\sum\\limits_v = 1^V \\frac\\left| D^v \\right|\\left| D \\right| \\left( \\sum\\limits_k = 1^K \\frac\\left| D^vk \\right|\\left| D^v \\right|\\log _2\\frac\\left| D^vk \\right|\\left| D^v \\right| \\right)\\endarray
Ent(D∣A)=v=1∑V∣D∣∣Dv∣Ent(Dv)=−v=1∑V∣D∣∣Dv∣(k=1∑K∣Dv∣∣Dvk∣log2∣Dv∣∣D<