shell 例程 —— 解决redis读取稳定性
Posted yangykaifa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell 例程 —— 解决redis读取稳定性相关的知识,希望对你有一定的参考价值。
问题背景: php读取线上redis数据,常常不稳定,数据响应时有时无。
解决方法:多次读取。每次读取全部上一次没读出的数据,直到全部获取。
本文实现用shell进行多次redis数据读取, 每次取出当中的有效值(对于我们的样例中,就是给key,能在redis上取得其value的为有效值。其它无效),并将无效值重跑一遍,以此迭代,直到全部redis数据被取出。PS:redis数据能够由php或C读出,给定接口的话很easy,详细能够參考phpredis。。因为可能涉密,本文中不给出这块的实现。
方法概述:
- 将source中的key分为N个文件。丢入redis并行get value
- 实时统计N个文件get value输出结果的总行数,以及当中有效的行数
- N个文件统计结束后, 将其全部结果合并,放入result/step/stepx.res
- 删除原先并行的的source文件,结果文件
- 将result中未获取到的key放入source/step2/contsigns。作为下一轮的输入。再次将其分为N个文件,运行(这里的contsign就是redis的key)
- 最后将各个step所得结果都写入final.res文件。cat result/steps/step*.res >> final.res
项目结构:
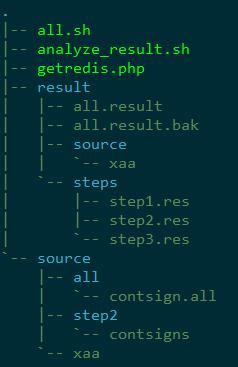
- getredis.php: 实现获取redis数据
- all.sh: 主程序,并行运行getredis.php;
- analyze_result.sh: 实时分析redis获取数据运行情况(第2步), 加參数后实现上面的第3-5步(详细见下一节凝视);
- source/:存储输入数据,当中all/下为原始全部redis的输入。 step2/为这一轮中未获取到的key,将作为下一轮获取redis的输入, 其余(如xaa)为当前这一轮中key分成的N个文件;
- result/: 存储结果。当中source/包括当前一轮source下全部N个文件的输出;steps/包括各轮输出后的合并结果
详细实现:
all.sh :
#Author:Rachel Zhang
#Email: zrqjennifer@sina.com
for file in source/*
do
{
echo "processing source $file"
if test -f $file
then
php getredis.php $file > result/$file
fi
echo "$file done..."
}&
done
analyze_result.sh:
#Author:Rachel Zhang
#Email: zrqjennifer@sina.com
Filefolder=result/source/*
#Filefolder=source/*
echo "##################################"
echo " In Folder $Filefolder"
echo "##################################"
nl=0
hv=0
for file in $Filefolder
do
if test -f $file
then
fline=`wc -l $file | awk \'{print $1}\'`
nl=$(($nl+$fline))
fvalue=`cat $file |awk \'BEGIN{x=0;}{if($2) x=x+1;}END{print x;}\'`
hv=$(($hv+$fvalue))
fi
done
echo "totally $nl lines"
echo "$hv lines have tag value"
##################################
#combine results into one file
if [ "$#" -gt 0 ]
then
if test -e "result/all.result"
then
mv result/all.result result/all.result.bak
fi
for file in $Filefolder
do
if test -f $file
then
cat $file >> result/all.result
fi
done
echo "all the output are write in result/all.result"
# put null-value keys into source/step2/contsigns
if test -e source/step2
then
mkdir source/step2
fi
cat result/all.result| awk \'{if($2==null) print}\' > source/step2/contsigns
Nnull_value=`wc -l source/step2/contsigns | awk \'{print $1}\'`
echo "remaining ${Nnull_value} keys to be processed"
# put has-value key-value into result/steps/step${step_id}.res
step_id=1
while test -e result/steps/step${step_id}.res
do
step_id=$(($step_id+1))
done
cat result/all.result | awk \'{if($2) print}\' > result/steps/step${step_id}.res
echo "current valid results are writen in result/steps/step${step_id}.res"
# remove the current source files, generate new source files and re-run all.sh
echo "remove current source and result files? (y/n)"
read answer
if [ $answer == "y" ]; then
if [ $Nnull_value -gt 10 ]; then
rm source/*
rm result/source/*
cd source && split -l 5000 step2/contsigns && cd ../
echo "now re-run sh ./all.sh?
(y/n)"
read answer
if [ $answer == "y" ]; then
sh all.sh
fi
fi
fi
fi
PS: 以上analyze_result.sh 还能够去掉analyze_result.sh中的interactive部分(无需用户输入)。通过crontab进行定时,进一步自己主动化运行。
以上是关于shell 例程 —— 解决redis读取稳定性的主要内容,如果未能解决你的问题,请参考以下文章