YOLOV7模型调试记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOV7模型调试记录相关的知识,希望对你有一定的参考价值。
先前的YOLOv7模型是pytorch重构的,并非官方提供的源码,而在博主使用自己的数据集进行实验时发现效果并不理想,因此生怕是由于源码重构导致该问题,此外还需进行对比实验,因此便从官网上下载了源码,进行调试运行。
环境配置
由于博主先前曾经运行过pytorch版本的yolov7,因此这次就沿用那个虚拟环境了。
有需要了解相关配置的可以参考博主这篇博客:
写在前面,关于YOLOv7的代码中有个wandb大家可以将其关闭,因为这个实际上没有啥用途反而在运行中会造成下载屏障,配置错误等问题,关闭方法打开下面这个文件:
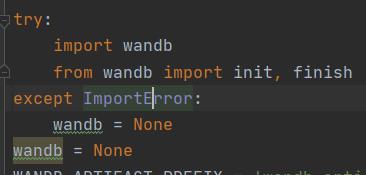
随后在开头代码:
try:
import wandb
from wandb import init, finish
except ImportError:
wandb = None
后加上wandb = None,即为:
测试
将源码下载完成后,先进行简单测试看看环境是否符合,可以先运行detect.py,修改下其中的预训练模型文件:这里建议大家手动下载。
parser.add_argument('--weights', nargs='+', type=str, default='./weights/yolov7.pt', help='model.pt path(s)')
其余的就不用动了,运行成果后会提示你将检测结果放到相应文件夹:
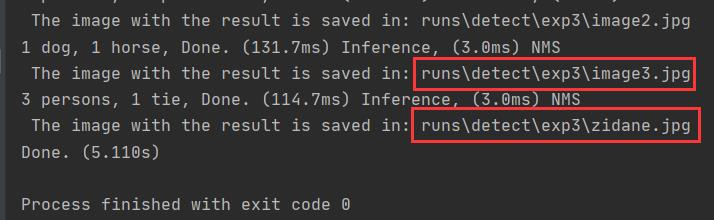
测试结果:

训练调试
这个才是我们的重头戏
其实这个配置并不难,我们使用的是YOLO格式的数据集,该数据集就是先前博主在运行YOLOv8模型时制作的。
具体制作过程参考博主这篇博文:
主要便是执行下面这段代码,即将VOC格式数据集转换为YOLO格式
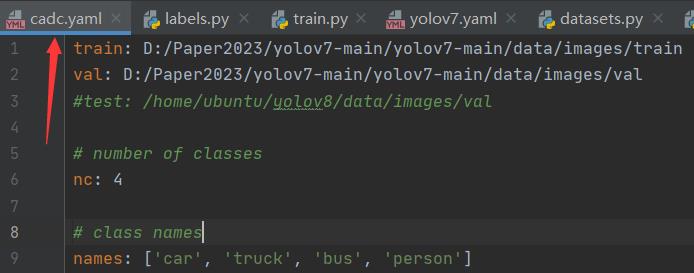
随后创建数据集配置文件
然后修改train.py中的相关配置:分别对应预训练模型参数,模型框架与数据集配置文件,此外还需修改epochs和batch-size等。
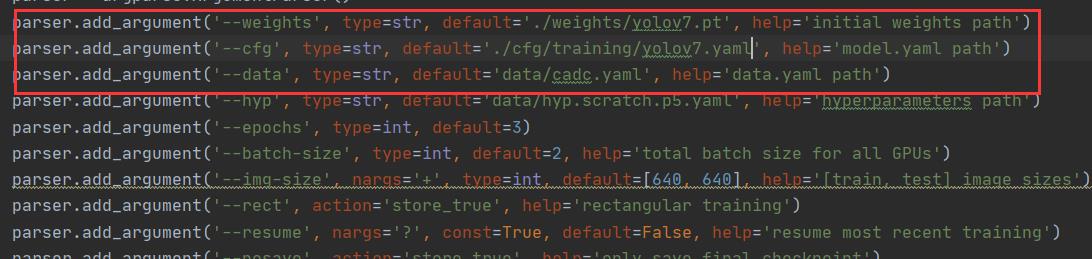
随后我们还需修改模型配置文件中检测的类别数

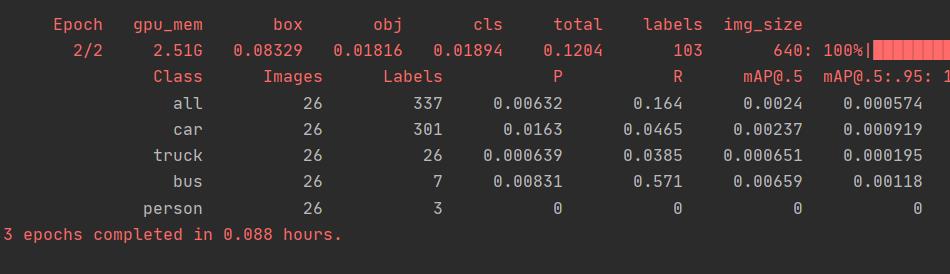
随后我们运行train.py文件就OK了:这里由于博主使用了一小部分数据集所以效果并不理想,稍后会将其上传至服务器上进行实验。
服务器配置
将代码上传值服务器后,由于博主先前已经将使用该数据集训练了YOLOv8模型,因此数据集早已存在于服务器上,此时的数据集存放在yolov8的data文件内,博主将cadc.ymal文件的路径修改为yolov8中的地址却报错,随后便将yolov8中的数据集复制到了yolov7中,再次运行后依旧报错,后来发现是由于在复制过程中连同.cache缓存文件一并复制过来的缘故,将其删除后再次运行,运行成功。
此时设置batch-szie=16 epochs=300
GPU服务器使用情况如下:

以上是关于YOLOV7模型调试记录的主要内容,如果未能解决你的问题,请参考以下文章