记一次redis挂机导致的服务雪崩事故,不对,是故事~
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次redis挂机导致的服务雪崩事故,不对,是故事~相关的知识,希望对你有一定的参考价值。
事故时常有,最近特别多!但每次事故总会有人出来背锅!如果不是自己的锅,解决了对自己是一种成长,如果是自己的锅,恐怕锅大了,就得走人了,哈哈哈。。。
这不,最近又出了一个锅:从周五开始,每天到11点就不停的接到服务器报警,对于一般的报警,我们早已见怪不怪了,然后作了稍微排查(监控工具: CAT),发现是redis问题,没找到原因,然后过了一会自己就好了,所以刚开始也没怎么管他。然后,第二天报警,第三天报警,领导火了,然后只好说,要不等到周一上班咱们再解决吧!
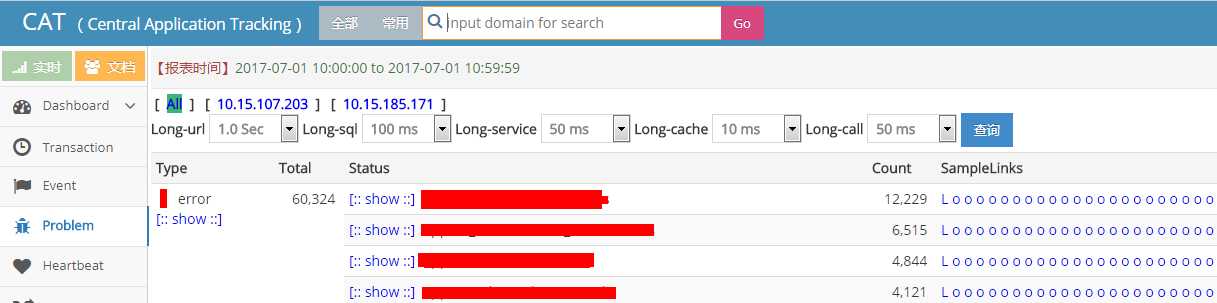
周一,开发同学还没去找运维同学查问题,运维同学倒先紧张起来了。
原因是,他们从监控(监控工具: granfana, zabbix)上发现,服务器到这个点就会有一个访问量的暴增,真的是暴增哦,从图中可以看出,一个笔直的线就上去了。然后运维同学也给出了具体哪些接口的访问次数,然后给出了对比性的数据,在这个点的接口访问次数比其他时间要多上一倍以上的访问量。
然后开始排查:
1. 是不是代码有问题?
确认最近项目有上线吗?我擦,我还真有一个项目是差不多这个时间上去的,吓死我了,赶紧查看代码是否有漏洞存在,几经排查后,确认没有问题。然后,抛弃该条路。
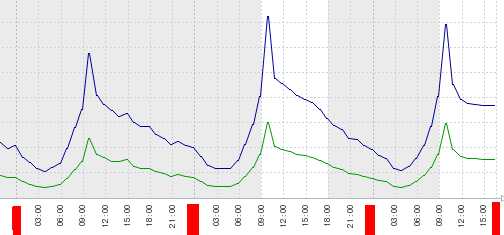
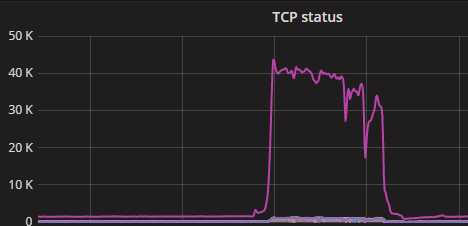
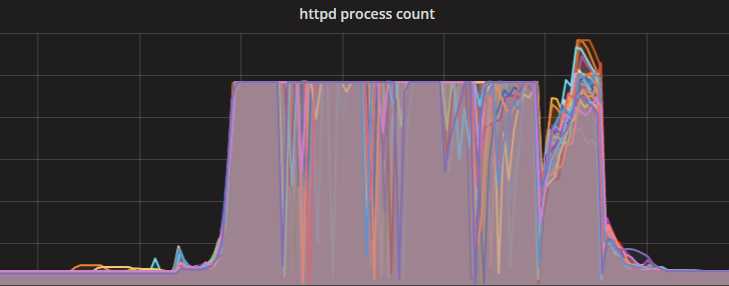
2. 是不是代码里连接redis后,不释放该连接?
从连接原理上和代码逻辑上,确认代码连接redis都是短链接,本次访问完成后释放该连接。(针对该问题,我还一度怀疑redis的连接可能被默默重用,但最终证明我是错的)
3. 对比之前没有报警时的访问情况和现在的情况?
对比之后,在没有该问题时,也会有流量高峰,但是不是这个点,而且服务器也是正常运行。所以可以肯定,是后面发生了什么,才导致的问题!
4. 会不会是定时任务反复访问自己的服务器,从而导致该流量高峰?
仔细检查任务中心(quartz),以及每台机器上的crontab,确认异常的脚本发生。不过,后来,我们曾一度花了很长时间在排查这个可能性上!
5. 统计每个接口的访问量,对比问题前与问题后?
对于该问题,主要通过统计服务器的访问日志,如apache的access_log, 得到接口地址,当然了,我们都是很多的集群环境,如果要在每台机器进行日志搜索,自然是要累死人的。咱们使用 salt工具,进行一台机器上直接搜索所有机器上的日志文件,进行统计。如:
salt ‘cc*.cc‘ cmd.run "cat access_log | awk -F ‘ ‘ ‘{print $9}‘ | sort | uniq -c" > 1.log # 该处的双引号不一定能用哦
6. 发现可疑接口,怀疑可能被黑客攻击,重点排查?
再现某些接口,正常的访问只能是get,但是去发现有post请求,以为是异常请求,于是找了一台测试环境下访问日志,也进行相应的统计:
grep -E ‘POST /x/cc/public/notice |POST /x/cc/Public/init ‘ access_log | less
结果,一样搜索出该情况,由于机制决定,最终确认该情况也为正常访问。
7. 统计每个ip的访问情况,确认是否有黑客攻击行为?
与每个接口访问统计一样,统计ip
cat access_log | awk -F ‘ ‘ ‘{print $2}‘ | sort | uniq -c > 1.log
最后,发现,ip都是无规律分布的,我们假设是被肉机模拟的ip,但是这条路也已经走不通了。
8. 统计每个开放域名的访问情况,以确认是否是某个不安全的域名被扫描或者攻击了?
其实这个工作应该是留在前面进行的,但是我们也是到了后面,实在没了方向,才又折回来的,统计方法和(5)是一样的。
cat access_log | awk -F ‘ ‘ ‘{print $2}‘ | sort | uniq -c > 1.log
然后,发现我们好几个业务的域名都暴增了,然后又没方向了,因为并不是哪个特定的业务出了问题,而是整体的。
9. 查看业务日志代码,检查是否出现了相应的访问后端接口缓慢或异常的情况?
我随机抽看了下某台机器的日志,发现一切访问都正常,除了几个redis读取的异常外,然后我作出了判定,后端接口没有问题。当然,这最终证明了我是错的,因为正是由于后端服务响应慢,从而导致了前端请求一直挂起,从而redis连接未释放情况,从而导致许多的redis连接!
10. 根据统计中发现,在出现问题,access_log中,有大概的" OPTION * " 的请求,为什么?
日志如下:
0 127.0.0.1 cc.c.com - - [24/Jun/2017:21:21:47 +0800] "OPTIONS * HTTP/1.0" 200 - "-" "Apache/2.2.3 (CentOS) (internal dummy connection)" 85 202 "-"
该请求达到好几十万的访问,然后我们又去找,为什么会有这种请求,然后努力模拟这种请求,甚至想用线服务器地址作为请求对象,最终也没有模拟出这种情况,因为无论怎么请求,都会有一个相对路径地址产生,而且在OPTION成功之后,会默认触发一次GET请求。
最终证明,这只是apache在管理子进程时,对自身进程的监听所产生的access log日志,对不是问题的方向。
11. 所有问题都排查了,仍然不知道这流量是从哪里来的,只能问其他人了?
突然有人想起,产品改过某个流控规则,提示文案为”xx业务在xx点开抢,不要错过“!我靠,这不是秒杀系统了吗?流量不暴增才怪!
12. 终于找到问题了,然后再是拉上架构师,去理论!!!
原来是虚惊一场啊(业务人员一不小心搞的秒杀活动~,流量暴增属正常情况),虽然服务器多次挂掉,但是由于不是自己的锅,悬着的心总算掉下来了。
但是,归根结底,还是我们的系统不够牛逼啊,对于这突发的流量,一下没扛住,当然,在本案中,主要表现为redis没有扛住压力,赶紧强化进来吧!~
对于推送活动一类的操作,一定要先跟技术运维做好沟通,将所有的流量预估,机器新增,安全因素考虑在内。让系统做好足够的准备,才能安稳地去搞自己的活动,否则任何一个环节都可能导致瓶颈,从而合使服务瘫痪。(应对这种情况,我们只有一种办法,重启服务甚至服务器)
当然,这里有个问题也是我没想太明白的,就是有时候对于调用第三方的东西,你搞活动不去跟别人打招呼(一般情况都不会),那么,你的系统扛住了压力,那么别人的系统呢?
以上是关于记一次redis挂机导致的服务雪崩事故,不对,是故事~的主要内容,如果未能解决你的问题,请参考以下文章
线上问题解决系列——记一次HTTP连接池导致的Java服务雪崩