红外与可见光图像融合论文阅读
Posted SSyangguang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了红外与可见光图像融合论文阅读相关的知识,希望对你有一定的参考价值。
最近研究红外与可见光图像融合,看到一篇文章RFN-Nest: An end-to-end residual fusion network for infrared and visible images,这里记录一下。
Abstract
本文提出一种残差融合网络residual fusion network (RFN),用于替换传统的融合方法,同时提出两种损失函数用于训练RFN:细节保留损失函数和特征增强损失函数。模型训练使用了两阶段训练方法,第一阶段训练一个基于nest connection (Nest)的自编码器,第二阶段使用提出的损失函数训练模型。在目前公开数据集上本模型在主观和客观评价标准上都达到了SOTA。代码:https://github.com/hli1221/imagefusion-rfn-nest。
Introduction
图像融合主要有三个关键步骤:特征提取、融合策略和图像重建,目前方法分为传统方法和深度学习方法。传统方法中multi-scale transform在多尺度特征提取中使用广泛,并使用适当地融合策略将不同特征通道进行组合,最终融合特征使用inverse multiscale transform重建为原始分辨率的融合图像,但是这类方法高度依赖于特征提取方法。
Sparse represention (SR)和low rank represention (LRR)法也被用于提取显著性特征,这类方法中滑窗被用于将原始图像分解为patch,然后将这些patch重新组建为一个矩阵,每列元素是patch一维化后的向量,最后将这个矩阵送入SR或LRR模型中计算系数(也就是特征)。通过这种方法就将图像的融合转化为系数融合,融合系数通过适当的融合策略产生,在SR或LRR的框架下重建图像。
传统方法的缺陷有:1.融合效果高度依赖人工设计的特征,很难为所有融合任务设计出通用特征提取方法;2.不同的融合策略要求不同的特征;3.基于SR和LRR方法很耗时;4.基于SR和LRR的方法较难处理复杂图像。
深度学习方法则一定程度上克服了上述问题,根据融合的三个关键步骤段分为三类方法:深度特征提取、融合策略和端对端训练。深度特征提取用于提取深度特征表示,融合策略可以通过深度学习模型来设计,也有方法使用CNN来生成原始图像的decision map,可以对融合后的图像进行适当后处理。为了避免人工设计方法,一些端对端融合模型也被提出了,如FusionGAN、DDcGAN等,利用对抗学习避免了人工设计方法。但上述方法对细节保留不好,为了保留可见光图像更多细节引入了基于nest connection的自编码器模型NestFuse,在细节保留上不错,但是融合策略仍是不可学习的。
为了克服上述问题,本文也就提出了RPN-Nest模型,主要贡献点为:1.提出残差融合网络进行可学习的融合模块,代替人工设计的融合策略;2.使用两阶段训练策略,特征提取和特征重建能力分别是编码器和解码器的主要功能,先将编码网络和解码网络按照自编码器进行训练,再固定编码器和解码器,用适当的损失函数来训练RFN网络;3.设立了两种损失函数,分别用于保留细节和特征增强。
先前的工作主要分为非端对端模型和端对端模型。早期的非端对端模型有基于预训练的VGG19模型,先将源图像分解为显著性部分(纹理和边缘)和基础部分(轮廓和亮度),然后用VGG19从显著性部分提取多层次深度特征,每个层次根据深度特征计算decision map并生成候选融合显著部分,最后的融合图像使用适当的融合策略组合融合基础部分和融合显著性部分进行重建。也有使用ResNet50进行深度特征提取的,decision map通过zerophase component analysis(ZCA) 和 l1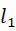 -norm 得到。此外还有PCANet这类模型。有一些方法把特征提取和融合用同一个网络完成,直接从输入图像得到decision map。也有深度编码器-解码器结构模型,一般为编码器-融合-解码器结构,编码器往往用于提取模态间互补信息。较新的模型有NestFuse,该模型保护了可见光图像更多细节信息,同时加强了红外图像的显著性信息,还添加了一个空间/通道注意力模块融合多尺度深度特征。不过上述非端对端方法都较难设计一个有效地人工设计融合策略。端对端模型消除了人工设计特征和融合策略的随意性,很多使用GAN来进行。FusionGAN的生成器计算融合图像,判别器约束融合图像使其可以包含更多可见光图像的细节信息,损失函数包含内容损失和判别器损失,不过该模型对细节的保留不是很好。FusionGANv2加深了生成器和判别器网络,使该模型可以保留更多细节,也提出新的损失函数:细节损失和目标边缘增强损失,这样一来融合图像重建了更多场景信息,锐化了目标边缘。IFCNN使用两层卷积层提取深度特征,元素级融合规则(元素最大值,元素总和,元素平均值)融合卷积层得到的深度特征,但是该模型结构过于简单,不能提取很深层的特征,融合策略也不是最有的。
-norm 得到。此外还有PCANet这类模型。有一些方法把特征提取和融合用同一个网络完成,直接从输入图像得到decision map。也有深度编码器-解码器结构模型,一般为编码器-融合-解码器结构,编码器往往用于提取模态间互补信息。较新的模型有NestFuse,该模型保护了可见光图像更多细节信息,同时加强了红外图像的显著性信息,还添加了一个空间/通道注意力模块融合多尺度深度特征。不过上述非端对端方法都较难设计一个有效地人工设计融合策略。端对端模型消除了人工设计特征和融合策略的随意性,很多使用GAN来进行。FusionGAN的生成器计算融合图像,判别器约束融合图像使其可以包含更多可见光图像的细节信息,损失函数包含内容损失和判别器损失,不过该模型对细节的保留不是很好。FusionGANv2加深了生成器和判别器网络,使该模型可以保留更多细节,也提出新的损失函数:细节损失和目标边缘增强损失,这样一来融合图像重建了更多场景信息,锐化了目标边缘。IFCNN使用两层卷积层提取深度特征,元素级融合规则(元素最大值,元素总和,元素平均值)融合卷积层得到的深度特征,但是该模型结构过于简单,不能提取很深层的特征,融合策略也不是最有的。
本文模型
本文提出的RFN-Nest模型是端对端模型,包含的结构主要有编码器、残差融合网络(RFN)和解码器,如下图,卷积层上的数字分别表示:卷积核尺寸、输入通道数、输出通道数。


编码器
编码器有最大池化层将原始图像下采样为多尺度,RFN将每个尺度的多模态深度特征进行融合。浅层特征保护细节信息,深层特征传递语义信息(对重建显著性特征很重要)。最后融合图像通过基于nest connection的解码层网络进行重建。网络的输入层分别为红外图像和可见光图像,输出即为融合图像,4个RFN是四个尺度上的融合网络,4个网络模型结构相同,权重不同。
残差融合网络Residual fusion network (RFN)
RFN基于残差结构,如下图。

该结构的输入即为前面编码器提取得到的深度特征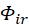
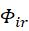 和
和
 ,每一个尺度都有对应的深度特征。Conv1-6是6个卷积层,可以看到Conv1和Conv2的输出会进行拼接,作为Conv3的输入,Conv6则是用于该模块第一个用于融合的层。使用该结构可以通过我们提出的训练策略进行优化,最后的输出送入解码层。
,每一个尺度都有对应的深度特征。Conv1-6是6个卷积层,可以看到Conv1和Conv2的输出会进行拼接,作为Conv3的输入,Conv6则是用于该模块第一个用于融合的层。使用该结构可以通过我们提出的训练策略进行优化,最后的输出送入解码层。
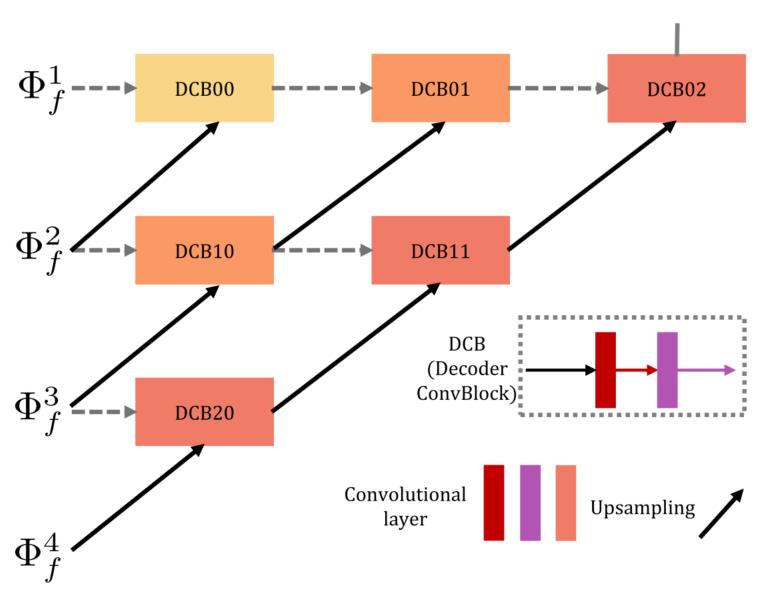
解码器
解码器的结构如下图,以nest connection为基础而来的。
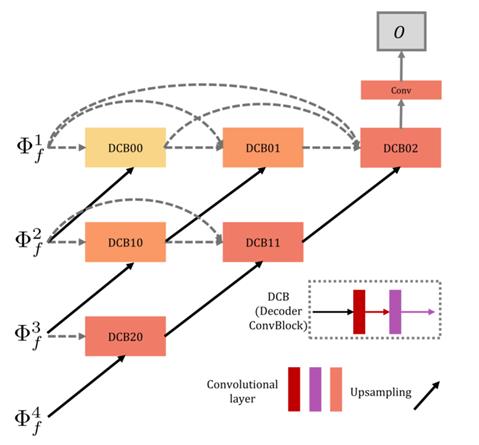
解码器的输入是所有RFN的输出特征,DCB即为解码器卷积层模块decoder convolutional block,每个这样的模块包含2个卷积层。每列都有short connection连接每个卷积模块,cross-layer links则连接了不同尺度的深度特征。解码器最终的输出就是重建后的图像了。
两步训练策略
模型中编码器和解码器在分别用于特征提取和重建都很重要,所以需要两步训练策略保证每个步骤都能达到预期效果。
第一步先将编码器-解码器结构作为自编码器重建输入图像进行训练,第二步训练多个RFN网络进行多尺度深度特征融合。自编码器的训练如下图。

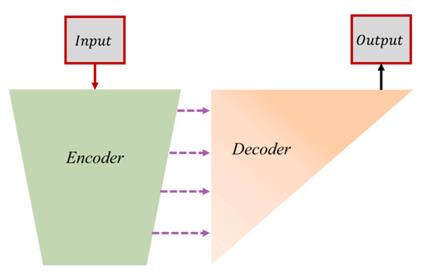
解码器有了cross-layer connections后可以充分利用多尺度深度特征进行图像重建了。该阶段使用的损失函数如下
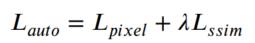
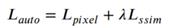
右边两项分别代表像素损失、输入输出图像之间的结构相似性损失(SSIM),λ是平衡这两个损失的超参数。像素损失的计算方法如下
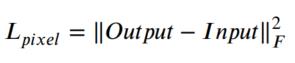
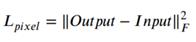
F为Frobenius norm,上面的损失函数约束了重建图像在像素级别与输入图像更相似。
SSIM 损失定义如下
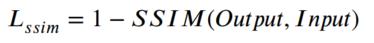

SSIM函数是结构相似性,可以量化两个图像之间的结构相似性。
第二步是训练RFN,用于学习融合策略。这一步将编码器-解码器结构固定,再用适当的损失函数来训练RFN,过程如下。

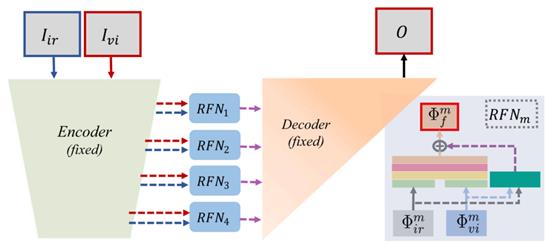
因为编码器和解码器都固定了,所以提取的深度特征和重建图像都是固定的,只需要对中间的RFN进行训练即可,提出了新的损失函数,定义为
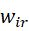

右边两项分别是背景细节保护损失函数和目标特征增强损失函数,α用于平衡这两个损失函数。在红外与可将光图像融合中,由于红外图像大多分辨率较差,所以细节信息可见光图像较多。细节保护损失函数也将从可将光图像中保护细节和结构特征作为目标,定义如下
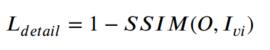

红外图像一般包含的显著性目标特征更多,所以目标特征增强损失函数用于融合特征来保护显著性结构,定义如下
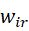

上式M也就是多尺度深度特征的数量,本文是4。因为不同尺度特征图大小不同,也需要向量
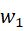 来平衡不同尺度的损失。
来平衡不同尺度的损失。
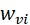 和
和 分别控制融合特征中可见光和红外图像的占比。因为可见光信息被背景细节保护损失函数约束,同时目标特征增强损失函数保护了红外图像的显著性信息,所以
分别控制融合特征中可见光和红外图像的占比。因为可见光信息被背景细节保护损失函数约束,同时目标特征增强损失函数保护了红外图像的显著性信息,所以
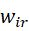 一般会大一些。
一般会大一些。
实验部分
第一步用COCO数据集进行自编码器的训练,选择8万张图作为训练集,对这些图进行灰度化并重采样为256×256。λ设置为100,batch设置为4,epoch为2,学习率为1×10-4 。第二步训练用KAIST数据集训练RFN模块,选择了八万张图像可见光与红外图像对进行训练,也对这些图进行灰度化并重采样为256×256,batch设置为4,epoch为2,学习率为1×10-4。
。第二步训练用KAIST数据集训练RFN模块,选择了八万张图像可见光与红外图像对进行训练,也对这些图进行灰度化并重采样为256×256,batch设置为4,epoch为2,学习率为1×10-4。
测试数据来自于TNO和VOT2020-RGBT,TNO有21张图片对,VOT2020有40个图片对。用6种指标进行评估,即entropy(𝐸𝑛); standard deviation (𝑆𝐷);mutual information(𝑀𝐼); modified fusion artifacts measure (𝑁𝑎𝑏𝑓 ); the sum of the correlations of differences(𝑆𝐶𝐷); the multi-scale structural similarity (MS-SSIM)。
消融实验:
1.主要针对背景细节保护损失函数和目标特征增强损失函数,也有可见光和红外特征的相对权重对融合性能的影响。因为节保护损失和特征增强损失差异巨大,所以α也需要设置的较大才可,同时也因为细节保护损失保护可见光的细节,最终α的范围设置为0和700进行分析。目标特征增强损失函数中研究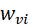 和
和 带来的影响,范围设置为0.5至6.0,下图α=0时这两个参数不同的融合结果,只使用目标特征增强损失函数训练。
带来的影响,范围设置为0.5至6.0,下图α=0时这两个参数不同的融合结果,只使用目标特征增强损失函数训练。


取参数较为平衡的几组结果(黄色和粉色框)进行评价,结果如下表。


α为700时主要是背景细节保护损失函数起作用了,这样就需要提高wir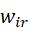 的大小来保护更多红外显著性信息,结果对应于上图的红框。最终两个α值下的融合结果如下图。
的大小来保护更多红外显著性信息,结果对应于上图的红框。最终两个α值下的融合结果如下图。

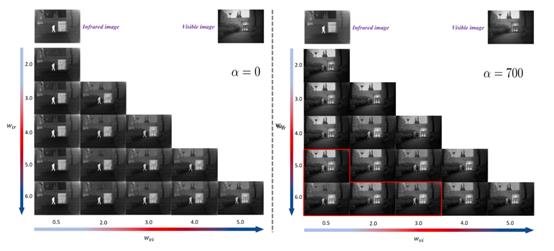
上图右半部分的融合结果保留了更多细节信息,红外显著性特征也保留着。左半部分的细节信息则保留的较少。指标计算均在上表中。上面结果显示了如果不使用细节保护损失,融合结果的细节信息不好。最佳结果应该是𝛼 = 700, 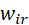 = 6.0 和 = 3.0 这组。因此后续实验也使用这组参数进行。
= 6.0 和 = 3.0 这组。因此后续实验也使用这组参数进行。
2.α的影响:上面的实验结果可以看出α在不为0的情况下结果表现较好,因此这部分讨论α取值对实验的影响。首先将 = 6.0 和 = 3.0 这两个参数固定,然后
= 6.0 和 = 3.0 这两个参数固定,然后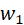
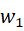 的取值设置为1, 10, 100, 1000 ,最优α值的搜索范围设置为10, 100, 200, 500, 700, 1000 ,结果如下图和下表,可以看出α设置为最大的1000时红外图像的显著性信息基本看不见了,只有500和700时才能较好同时保留细节信息和显著性信息。最终的指标显示α=700时最优,因此后续实验将α固定为700。
的取值设置为1, 10, 100, 1000 ,最优α值的搜索范围设置为10, 100, 200, 500, 700, 1000 ,结果如下图和下表,可以看出α设置为最大的1000时红外图像的显著性信息基本看不见了,只有500和700时才能较好同时保留细节信息和显著性信息。最终的指标显示α=700时最优,因此后续实验将α固定为700。



3.训练策略:该部分讨论两阶段训练的有效性。一阶段训练法是同时训练编码器-解码器-RFN,使用前述最优参数进行训练,得到的结果如下图。


可以看出可见光细节在一阶段训练法中被大大增强,红外显著性信息基本丢失,相反右边的两阶段训练就对这两种信息都保留的很好。作者认为这样的原因是编码器-解码器的特征提取和重建能力不足,顺便对他提出的RFN称赞不绝。
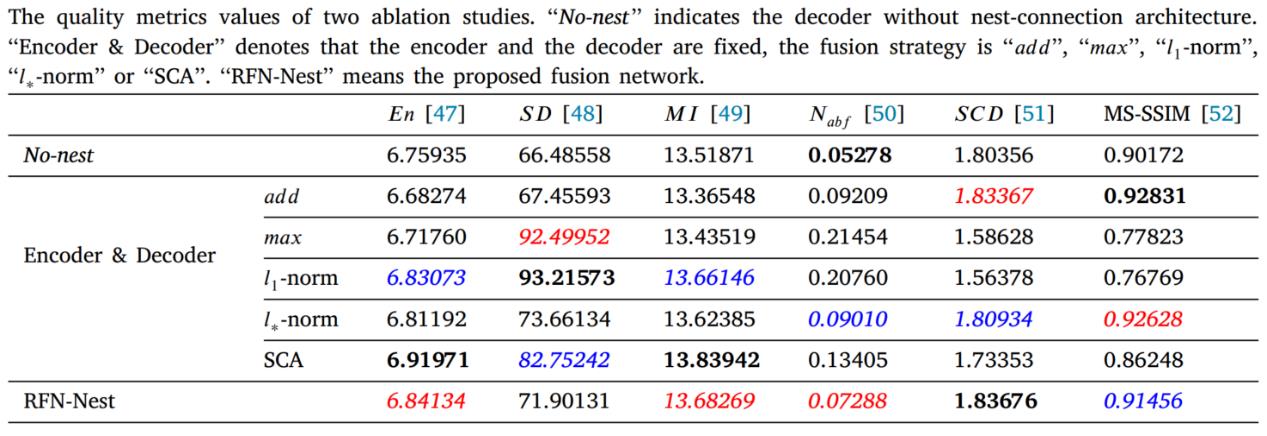
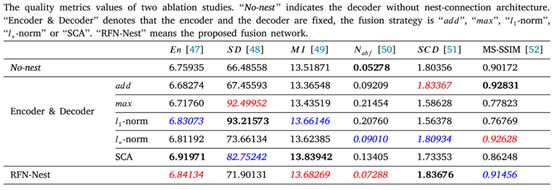
4.解码器nest connection:本阶段讨论解码器中nest connection带来的影响。下图是不包含nest connection的解码器结构,用上面介绍过的参数来训练这个不带nest connection的解码器。

最终训练得到的模型结果如下表,non-nest即上述没有nest connection的解码器,粗体黑、红、蓝分别代表第一、二、三好的结果。指标显示具有nest connection的解码器可以保护更多特征信息,产生的融合图像也更平滑。
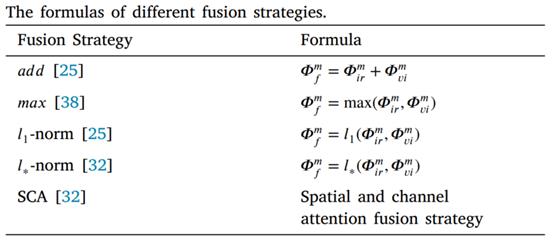
5.融合策略:本部分探究提出的RFN在融合策略方面的优势,选择了 𝑎𝑑𝑑、𝑚𝑎𝑥、𝑙1-norm、𝑙∗-norm、SCA这几种先前的融合方法作为对比,这四种方式的计算方法如下。SCA是NestFuse模型中曾经用过的方法。

这几个方法的结果如下图。基于RFN的模型保护了可见光更多的细节信息(蓝框)和更好的人造光源(红框)。最终TNO数据集中21个图像对的结果在上面的表中,基于RFN的方法在其中5个指标都是最优的,表明融合策略可学习时细节信息将被增强(En和SD)。


6.与SOTA模型的对比:选取TNO的21个图像对作为测试集和其他11个模型进行对比,指标计算见下表,两图是其中两个图片对的测试结果对比。
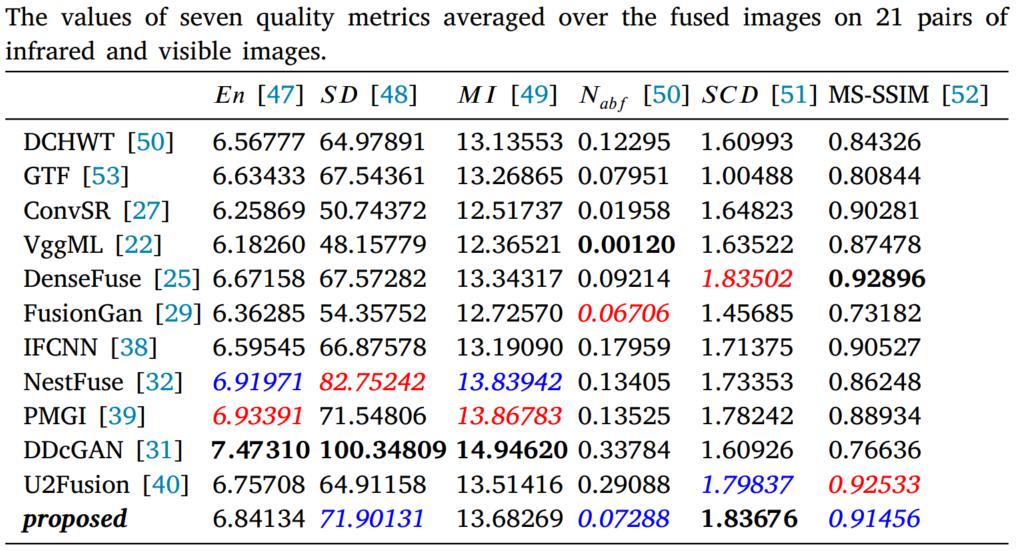




上图结果可以看出,DCHWT包含噪声较多。GTF和FusionGAN的融合结果更平滑,细节信息更多,但是直观看更像红外图,尤其是背景部分。ConvSR、VggML、DenseFuse、IFCNN、NestFuse、PMGI、U2Fusion都保留了更多的可见光信息,对红外显著性信息削弱的较多。DDcGAN的结果噪声较多,并且红外目标被模糊。
作者又对另外40个图片对进行了测试,得到了下表的对比结果。
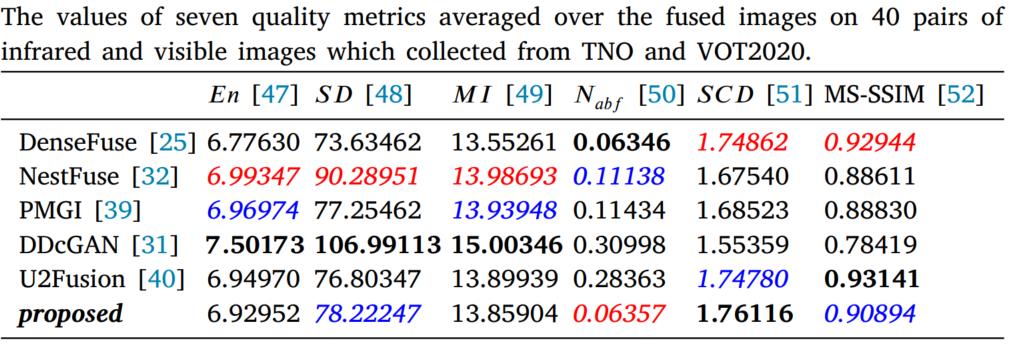
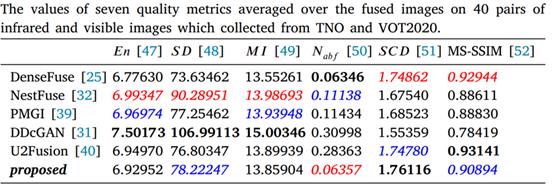

上面实验显示很多方法都不能有效处理天空中的云这种纹理信息,融合结果不自然。注意和之前的方法一样DDcGAN还是引入和过多噪声并且模糊了红外目标。
此外作者对RGBT追踪进行了实验,这里不再介绍,有兴趣的可以研究原文。
以上是关于红外与可见光图像融合论文阅读的主要内容,如果未能解决你的问题,请参考以下文章