微信小游戏背后的技术优化
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微信小游戏背后的技术优化相关的知识,希望对你有一定的参考价值。

作者:chrongzhang,腾讯 WXG 客户端开发工程师
这是一篇介绍微信小游戏客户端底层,如果进行优化,可以让所有小游戏获得更好性能的文章。不是你想像的怎么优化某个小游戏的文章。来都来了,就了解一下吧:)
小游戏主要分为渲染和逻辑两部分。渲染优化能让渲染相关的指令(WebGL/GFX)得到更高效的执行,逻辑优化是让除渲染之外的代码也能更高效的执行,本篇主要讲述逻辑相关的优化。
基础功能优化
V8
微信小游戏是在 2017 年 12 月 28 日上线的,当时微信安卓客户端使用的 V8 版本还是 5.5。而 Google 在 V8 上的迭代速度是很快的,其中一个大的版本变更是从 5.9 版本开始,编译器由原来的 FullCodeGenerator + Crankshaft 变更成更加高效的 Ignition + TurboFan。
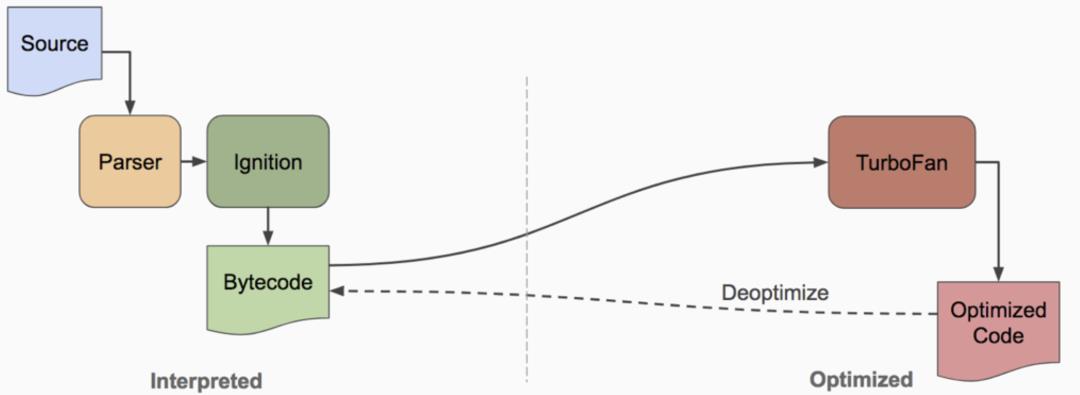
V8 引擎之所以性能高,在于其出色的 JIT 执行效率。JIT 依赖了一个可以在运行时优化代码的动态编译器。V8 早期的 JIT 编译器是 FullCodegen,后来是 Crankshaft,然后是一直沿用至今的 Turbofan。
升级 V8,可以获得更高的执行性能(TurboFan)、更快的启动速度(Snapshot + Code Caching)、更低的内存占用(64 位压缩指针)。小游戏上线至今,客户端使用的 V8 也一直在升级当中,从最初的 5.5,升级到 6.6,然后是 7.6,直到目前的 8.0。
JSBinding
微信小游戏对开发者暴露的是 JS 的接口,开发者调用某些 JS 函数时,最终会调用到客户端底层的原生能力。而从 JS 到客户端底层之间的桥接能力,就是所谓的 JS 绑定。JS 绑定又分为两种:裸绑定和非裸绑定。裸绑定是通过 V8/javascriptCore 提供的原生接口,将某个 JS 函数和原生函数实现绑定到一起,这是最直接,也是最高效的绑定方式。
非裸绑定是指通过某个 JS 和原生的通信的桥梁(evaluate/prompt/postMessage 等等),在此基础上再封装和转发具体的函数调用。由于存在中间一层的转发处理,会有额外的消耗。因此小游戏对外提供的 WebGL 等接口的实现,都采用了裸绑定的方式。直接用原生裸绑定的 API,又会存在以下问题:
原生 API 使用较复杂
不方便实现更高层次的类绑定
V8 和 JavaScriptCore 的 API 差异很大,两个平台需要重复实现绑定
于是,我们实现了一套通用的绑定库: jsbinding,公司内是开源的,未来计划对外也开源。
具有如下特点:
简单易用,支持类绑定
裸绑定,性能高
同时支持 V8 和 JavaScriptCore
支持 node addon 绑定实现
未来甚至计划提供 WebAssembly 的绑定实现,是不是还有点小期待呢?
NodeJs/libuv
安卓客户端已经全面拥抱 node。集成 node runtime 后,拥有了如下能力:
node 内置能力(如文件、setTimeout 等)
libuv 异步 IO 处理的能力
node 很多内置能力,是通过原生来实现的(node addon),属于裸绑定,性能较高。有了 libuv 事件驱动后,可以更加灵活和高效的处理一些异步事件。比如 WebSocket 的回调,之前的处理流程是,在子线程收到 socket 消息后,将消息内容通过 JNI 调用到 Java 层,Java 层再抛到 JS 线程(也是 JVM 线程),回调到 JS。而如果使用 libuv,可以在子线程通过 uv_async_send 封装的 ASyncCall 机制,在底层就直接抛到 JS 线程回调到 JS,避免了中间频繁的 JNI 调用和数据传输的开销。
调用链路优化
我们都知道,两点之间,直线最短。代码也是一样,调用链路越短,越直接,中间的开销就越小。
JsApi 优化
1. JsApi 调用优化
首先来看看之前 JsApi 的调用链路:
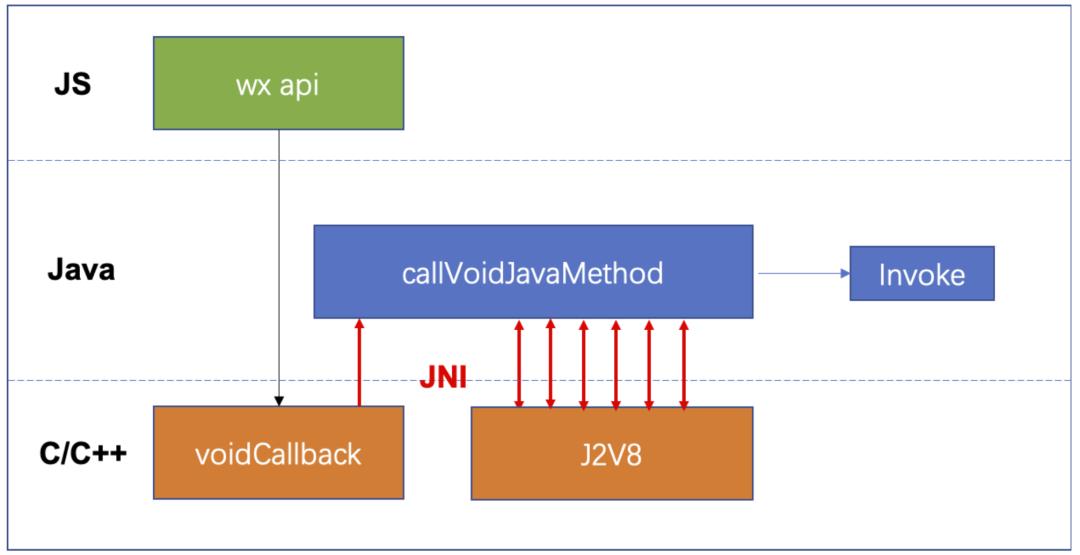
一个 js api 的调用(WeixinJSCore.invokeHandler),首先会调用到 C/C++ 统一的回调函数 voidCallback,然后再通过 JNI 调用到 Java 的统一处理函数 callVoidJavaMethod。在这个函数里,需要根据 methodID 从 map 中找到对应的 Java Method,然后再通过多次 JNI 调用 J2V8 各种接口将 js api 的参数转换为 Java 类型参数,最后再调用到具体 API 的 Java 实现函数 Invoke。
这个调用链路显然不是前面提到的裸绑定的实现方法,因为中间还夹了一层 Java 的中转处理层,产生了一些性能消耗。
针对 invokeHandler,缩短调用链路,减少 JNI 调用优化后,流程如下:
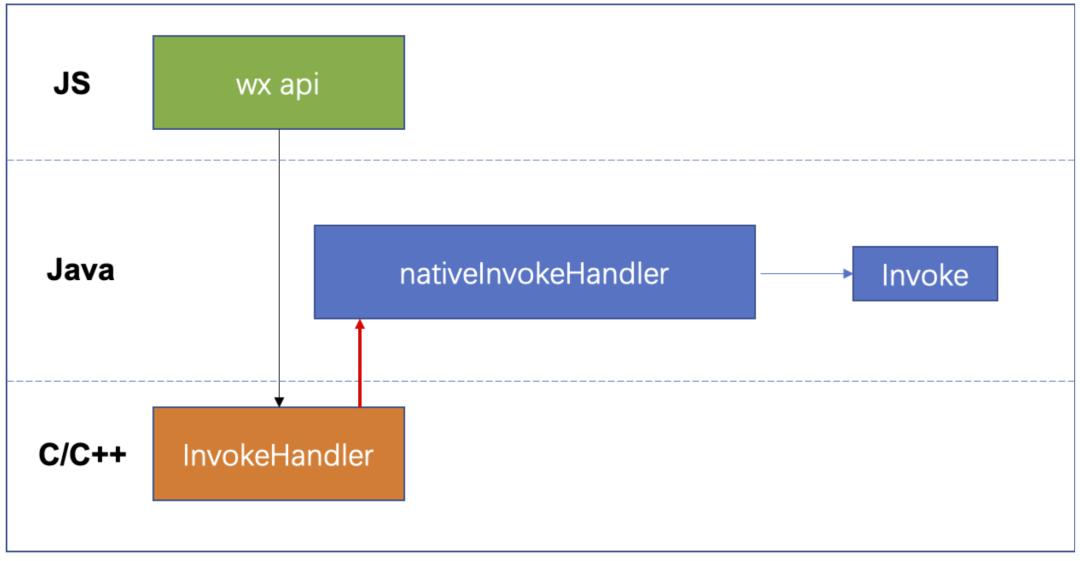
针对 js 的 WeixinJSCore.invokeHandler 接口提供专门的 C++ 裸绑定接口 InvokeHandler,取出所有参数后,只需要一次 JNI 调用到 nativeInvokeHandler,然后调到具体 API 的 Java 实现函数 Invoke。
除此之外,针对异步 JsApi 调用,之前的流程是在 java 层抛到另一个线程执行。有了 libuv Looper 后,优化成在底层起一个 uv 的 worker 线程,通过 ASyncCall 将任务抛到 worker 线程,这样 worker 里只需要执行同步的 api 流程,流程上简化了,效率上比抛 Java 层线程更高。
2. JsApi 回调优化
当框架层需要触发 JS 回调时,之前的做法是拼好一段 JS 字符串然后 evaluate:
evaluateJavascript(String.format(
"typeof WeixinJSBridge !== 'undefined' && " +
"WeixinJSBridge.invokeCallbackHandler(%d, %s)",
callbackId, data
));
这里的本质是去调用 JS 里的统一回调处理函数 WeixinJSBridge.invokeCallbackHandler,采取了直接执行一段 JS 的方法。优点是实现简单,缺点是效率不高。
因为让 JS 引擎执行一段 JS 代码时,需要先编译,parse 抽象语法树,生成 Ignition 字节码,甚至启用到 TurboFan 编译优化器,最后才真正执行到想调用的 JS 函数。
同时每个回调都拼一个字符串执行,在 JS 引擎内部会积攒大量临时字符串,占用内存资源。
优化的方法其实也很简单,就是通过 jsbinding 预先查找好 WeixinJSBridge.invokeCallbackHandler 函数,在需要回调这个 JS 函数时,直接调用即可。
// 查找到 invokeCallbackHandler 函数后,保存下来
mm::JSObject func =
JS_GET_AS(mm::JSObject, js_bridge, "invokeCallbackHandler");
js_func_holder_ = JS_NEW_OBJECT_HOLDER(func);
// ...
// 当需要回调时,直接调用
JS_CALL(js_func_holder_->Get(), nullptr, nullptr,
js_bridge, callbackId, data);
并行调用优化
开发者在执行某些耗时较重的任务时,可以使用多线程 Worker,类比标准 H5 的 WebWorker。
// 主线程初始化 Worker
const worker = wx.createWorker('workers/request/index.js') // 文件名指定 worker 的入口文件路径,绝对路径
// 向 Worker 发送消息
worker.postMessage(
msg: 'hello worker'
)
// workers/request/index.js
// 在 Worker 线程执行上下文会全局暴露一个 `worker` 对象
worker.onMessage(function (res)
console.log(res)
)
之前的 Worker 有个限制,只能执行一些纯逻辑运算的代码,不支持 JsApi 的调用。这很大程度限制了 Worker 的使用,于是我们也在不断的扩展 Worker 的能力,增加了音频、网络、文件等能力。
// Worker 线程
var audio = worker.createInnerAudioContext()
audio.src = url
audio.play()
未来 Worker 将会赋予更多能力,提高开发者并行化处理的效率。
数据传输优化
开发者在 JS 层的数据(ArrayBuffer)需要传到客户端底层,同时客户端底层的数据也需要传到 JS 上层,这中间涉及到数据的高效传输。在渲染优化时,可以通过 wgfx 提供的 createNativeBuffer 接口,创建一块 JS 和 Naitve 共享的内存,双方可直接读写该内存而无需额外的传输,极大的提高了效率。
NativeBuffer 的共享内存传输机制,可以应用到多个需要频繁传输数据的场景,比如 Camera 传输的数据、JS 的 WebGL CommandBuffer 传输等等。
还有一种情况是前面提到的 Worker 之间传输数据,如果通过默认的 postMessage 来传输,效率是非常低的,不利于传输较大的 ArrayBuffer 数据。为了解决这个问题,我们提供了类似标准 H5 的 SharedArrayBuffer 的能力,用来 Worker 之间高效的传输数据。
// game.js
const sab = wx.createSharedArrayBuffer(2)
worker.postMessage(
sab
)
// worker.js
worker.onMessage(function (res)
res.sab.lock(() =>
setTimeout(() =>
res.sab.unlock()
, 3000)
)
)
总结
小游戏的性能瓶颈,很大程度局限于 JavaScript,而我们所做的各种优化,是希望能尽量抹平 JavaScript 本身带来的性能损耗,接近并向原生性能靠齐,极具困难和挑战。
在 ios 上,我们也为让 JavaScript 拥有 JIT 能力做了深入探索。同时,我们也在 WebAssembly 上也进行了深入的探索和支持,未来有机会再进行分享。
为了小游戏有更好的运行性能,开发者能更好的发挥其创意,我们所有的性能优化还将持续不断的迭代下去。
以上是关于微信小游戏背后的技术优化的主要内容,如果未能解决你的问题,请参考以下文章