Elasticsearch7.8.0版本进阶——文档分析 & 分析器
Posted 小志的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch7.8.0版本进阶——文档分析 & 分析器相关的知识,希望对你有一定的参考价值。
目录
一、文档分析过程
- 将一块文本分成适合于倒排索引的独立的词条。
- 将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall分析器执行上面的工作。
二、分析器
分析器实际上是将三个功能封装到了一个包里
- 字符过滤器
首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个
字符过滤器可以用来去掉 html,或者将 & 转化成 and。 - 分词器
其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,
可能会将文本拆分成词条。 - Token 过滤器
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化
Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump
和 leap 这种同义词)。
三、内置分析器
Elasticsearch 还附带了可以直接使用的预包装的分析器。接下来我们会列出最重要的分
析器。为了证明它们的差异,我们看看每个分析器会从下面的字符串得到哪些词条:
"Set the shape to semi-transparent by calling set_trans(5)"
3.1、标准分析器
-
标准分析器是 Elasticsearch 默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写。它会产生:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
3.2、简单分析器
-
简单分析器在任何不是字母的地方分隔文本,将词条小写。它会产生:
set, the, shape, to, semi, transparent, by, calling, set, trans
3.3、空格分析器
-
空格分析器在空格的地方划分文本。它会产生:
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
3.4、语言分析器
-
特定语言分析器可用于 很多语言。它们可以考虑指定语言的特点。例如:英语分析器附带了一组英语无用词(常用单词,例如 and 或者 the ,它们对相关性没有多少影响),它们会被删除。英语 分词器会产生下面的词条:
set, shape, semi, transpar, call, set_tran, 5注意:transparent、 calling 和 set_trans 已经变为词根格式。
四、分析器使用场景
当我们 索引 一个文档,它的全文域被分析成词条以用来创建倒排索引。 但是,当我们在全文域 搜索 的时候,我们需要将查询字符串通过 相同的分析过程 ,以保证我们搜索的词条格式与索引中的词条格式一致。
全文查询,理解每个域是如何定义的,因此它们可以做正确的事:
- 当你查询一个 全文 域时, 会对查询字符串应用相同的分析器,以产生正确的搜索词条列表。
- 当你查询一个 精确值 域时,不会分析查询字符串,而是搜索你指定的精确值。
五、分析器的测试示例
-
启动es服务,在消息体里,指定分析器和要分析的文本
GET http://localhost:9200/_analyze "analyzer": "standard", "text": "Text to analyze"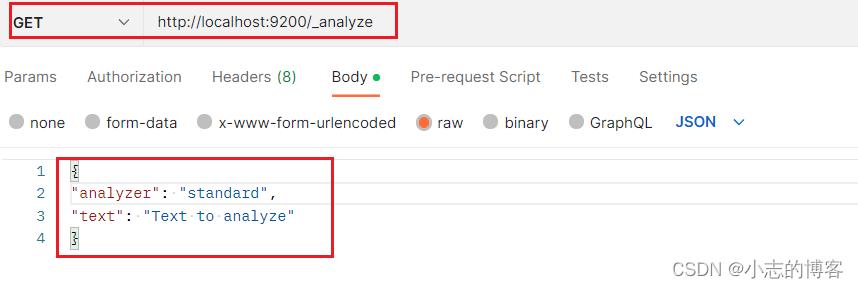
-
输出结果如下:每个元素代表一个单独的词条。
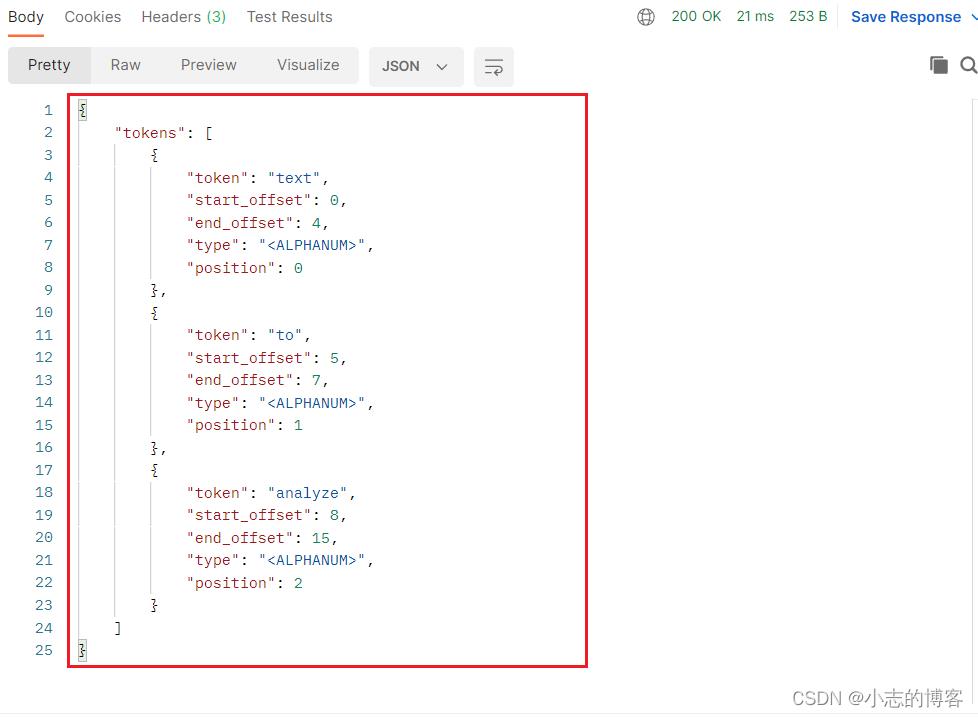
-
输出结果的解释
输出结果key 输出结果key的解释 token 实际存储到索引中的词条 start_offset 字符在原始字符串中的开始位置 end_offset 字符在原始字符串中的结束位置 position 词条在原始文本中出现的位置
以上是关于Elasticsearch7.8.0版本进阶——文档分析 & 分析器的主要内容,如果未能解决你的问题,请参考以下文章