TiDB性能调优
Posted _雪辉_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB性能调优相关的知识,希望对你有一定的参考价值。
文章目录
一、 TiDB 常见配置优化
1.1 限制 SQL 内存使用和执行时间
对于关系型数据库来说,SQL 效率毋庸置疑至关重要。可以想象一下,假设在数据库内没有任何控制机制,某条或某几条 SQL 执行时间长且耗用内存高,那么只能依赖告警系统且人工去快速定位 SQL 然后 Kill,期间效率可想而知,而在 TiDB 存在参数能让我们能够很好的限制 SQL 内存使用和执行时间。
1.1.1 执行时间限制
max_execution_time
作用域:GlOBAL | SESSION | SQL HINT
默认值:0
含义:该变量会限制语句的执行时间不能超过 N 毫秒,否则服务器会终止这条语句的执行,SQL Hint 方式具体示例如下:
SQL Hint:
mysql> SELECT /*+ MAX_EXECUTION_TIME(1000) */ * FROM t1 INNER JOIN t2 WHERE ...;
1.1.2 内存使用限制
tidb_mem_quota_query
作用域:SESSION
默认值:32 GB
含义: 该变量是系统变量,用来设置一条查询语句的内存使用阈值。 如果一条查询语句执行过程中使用的内存空间超过该阈值,会触发 TiDB 启动配置文件中 OOMAction 项所指定的行为,配置文件 oom-action 默认值 log,表示打印超过内存阈值 SQL,可通过配置 cancel 实现 Kill SQL 语句,SQL设置具体示例如下:
--设置内存使用限制为10G
mysql> set @@session.tidb_mem_quota_query=10737418240;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%tidb_mem_quota_query%';
+----------------------+-------------+
| Variable_name | Value |
+----------------------+-------------+
| tidb_mem_quota_query | 10737418240 |
+----------------------+-------------+
1 row in set (0.00 sec)
mem-quota-query
作用域:GLOBAL
默认值:32GB
含义:该变量是 TiDB 全局 Global 配置,需在 TiDB 配置文件设置(可在 tidb-ansible conf/tidb.yaml 配置 mem-quota-query 滚更生效),如果一条查询语句执行过程中使用的内存空间超过该阈值,会触发 TiDB 启动配置文件中 OOMAction 项所指定的行为,配置文件 oom-action 默认值 log,表示打印超过内存阈值 SQL,可通过配置 cancel 实现 Kill SQL 语句,具体示例如下:
conf/tidb.yaml
---
# default configuration file for TiDB in yaml format
global:
...
# Only print a log when out of memory quota.
# Valid options: ["log", "cancel"]
# oom-action: "log"
# Set the memory quota for a query in bytes. Default: 32GB
# mem-quota-query: 34359738368
1.2 事务重试设置
TiDB 数据库锁机制有别于传统数据库悲观锁,采用乐观锁,2PC 提交,此处不作具体展开,详情可查看 TiDB事务模型章节。针对事务冲突处理,可根据业务场景按需决定是否事务重试。
tidb_retry_limit
作用域:SESSION | GLOBAL
默认值:10
含义:该变量用来设置最大重试次数。一个事务执行中遇到可重试的错误(例如事务冲突、事务提交过慢或表结构变更)时,会根据该变量的设置进行重试。注意当 tidb_retry_limit = 0 时,也会禁用自动重试,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_retry_limit=0;
Query OK, 0 rows affected (0.01 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_retry_limit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%tidb_retry_limit%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| tidb_retry_limit | 0 |
+------------------+-------+
tidb_disable_txn_auto_retry
作用域:SESSION | GLOBAL
默认值:on
含义:该变量用来设置是否禁用显式事务自动重试,若将变量值设置为 on 时,表示不会自动重试,遇到事务冲突需要在应用层重试。若将变量值设为 off,遇到事务冲突 TiDB 将会自动重试事务,这样在事务提交时遇到的错误更少。需要注意的是,这样可能会导致数据更新丢失。该变量不会影响自动提交的隐式事务和 TiDB 内部执行的事务,它们依旧会根据 tidb_retry_limit 的值来决定最大重试次数,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_disable_txn_auto_retry=OFF;
Query OK, 0 rows affected (0.00 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_disable_txn_auto_retry=OFF;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%tidb_disable_txn_auto_retry%';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| tidb_disable_txn_auto_retry | OFF |
+-----------------------------+-------+
1 row in set (0.01 sec)
1.3 Join 算子优化
TiDB 数据库 SQL 执行,Join 算子天然并发,当系统资源富余时,可根据数据库 TP | AP 应用可适当调整 Join 算子并发提高 SQL 执行效率,提升数据库系统性能。
tidb_distsql_scan_concurrency
作用域:SESSION | GLOBAL
默认值:15
含义:该变量用来设置 scan 操作的并发度,AP 类应用适合较大的值,TP 类应用适合较小的值。 对于 AP 类应用,最大值建议不要超过所有 TiKV 节点的 CPU 核数,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_distsql_scan_concurrency=30;
Query OK, 0 rows affected (0.00 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_distsql_scan_concurrency=30;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%tidb_distsql_scan_concurrency%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| tidb_distsql_scan_concurrency | 30 |
+-------------------------------+-------+
1 row in set (0.01 sec)
tidb_index_lookup_size
作用域:SESSION | GLOBAL
默认值:20000
含义:该变量用来设置 index lookup 操作的 batch 大小,AP 类应用适合较大的值,TP 类应用适合较小的值,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_index_lookup_size=40000;
Query OK, 0 rows affected (0.00 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_index_lookup_size=40000;
Query OK, 0 rows affected (0.01 sec)
mysql> show variables like '%tidb_index_lookup_size%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| tidb_index_lookup_size | 40000 |
+------------------------+-------+
1 row in set (0.00 sec)
tidb_index_lookup_concurrency
作用域:SESSION | GLOBAL
默认值:4
含义:该变量用来设置 index lookup 操作的并发度,AP 类应用适合较大的值,TP 类应用适合较小的值,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_index_lookup_concurrency=8;
Query OK, 0 rows affected (0.00 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_index_lookup_concurrency=8;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%tidb_index_lookup_concurrency%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| tidb_index_lookup_concurrency | 8 |
+-------------------------------+-------+
1 row in set (0.00 sec)
tidb_index_lookup_join_concurrency
作用域:SESSION | GLOBAL
默认值:4
含义:该变量用来设置 index lookup join 算法的并发度,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_index_lookup_join_concurrency=8;
Query OK, 0 rows affected (0.00 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_index_lookup_join_concurrency=8;
Query OK, 0 rows affected (0.01 sec)
mysql> show variables like '%tidb_index_lookup_join_concurrency%';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| tidb_index_lookup_join_concurrency | 8 |
+------------------------------------+-------+
1 row in set (0.00 sec)
tidb_hash_join_concurrency
作用域:SESSION | GLOBAL
默认值:5
含义:该变量用来设置 hash join 算法的并发度,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_hash_join_concurrency=10;
Query OK, 0 rows affected (0.01 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_hash_join_concurrency=10;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%tidb_hash_join_concurrency%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| tidb_hash_join_concurrency | 10 |
+----------------------------+-------+
1 row in set (0.01 sec)
tidb_index_serial_scan_concurrency
作用域:SESSION | GLOBAL
默认值:1
含义:该变量用来设置顺序 scan 操作的并发度,AP 类应用适合较大的值,TP 类应用适合较小的值,SQL设置具体示例如下:
--设置SESSION作用域
mysql> set @@session.tidb_index_serial_scan_concurrency=4;
Query OK, 0 rows affected (0.00 sec)
--设置GLOBAL作用域
mysql> set @@global.tidb_index_serial_scan_concurrency=4;
Query OK, 0 rows affected (0.01 sec)
mysql> show variables like '%tidb_index_serial_scan_concurrency%';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| tidb_index_serial_scan_concurrency | 4 |
+------------------------------------+-------+
1 row in set (0.00 sec)
1.4 常见 Mysql 兼容问题
compatible-kill-query
默认值:false
含义:设置 Kill 语句的兼容性,TiDB 中 Kill sessionID 的行为和 MySQL 中的行为不相同。杀死一条查询,在 TiDB 里需要加上 TiDB 关键词,即 Kill TiDB sessionID。但如果把 compatible-kill-query 设置为 true,则不需要加上 TiDB 关键词。这种区别很重要,因为当用户按下 Ctrl+C 时,MySQL 命令行客户端的默认行为是:创建与后台的新连接,并在该新连接中执行 Kill 语句。如果负载均衡器或代理已将该新连接发送到与原始会话不同的 TiDB 服务器实例,则该错误会话可能被终止,从而导致使用 TiDB 集群的业务中断。只有当确定在 Kill 语句中引用的连接正好位于 Kill 语句发送到的服务器上时,才可以启用 compatible-kill-query ,具体示例如下(修改 tidb-ansible conf/tidb.yaml 配置再滚更):
conf/tidb.yaml
---
# default configuration file for TiDB in yaml format
global:
...
# Make "kill query" behavior compatible with MySQL. It's not recommend to
# turn on this option when TiDB server is behind a proxy.
compatible-kill-query: false
tidb_constraint_check_in_place
* 作用域:SESSION | GLOBAL
* 默认值:0
* 含义:TiDB 支持乐观事务模型,即在执行写入时,假设不存在冲突。冲突检查是在最后 commit 提交时才去检查。这里的检查指 unique key 检查。该变量用来控制是否每次写入一行时就执行一次唯一性检查。注意,开启该变量后,在大批量写入场景下,对性能会有影响。示例:
--默认关闭 tidb_constraint_check_in_place 参数行为
create table t (i int key);
insert into t values (1);
begin;
insert into t values (1);
Query OK, 1 row affected
commit; --commit 时才去做检查,并报错重复主键
ERROR 1062 : Duplicate entry '1' for key 'PRIMARY'
--打开 tidb_constraint_check_in_place 参数行为
set @@tidb_constraint_check_in_place=1;
begin;
insert into t values (1);
ERROR 1062 : Duplicate entry '1' for key 'PRIMARY'
1.5 其他优化项
prepared-plan-cache 以及 txn_local_latches 两个参数主要是 TiDB 配置参数,需要在 TiDB 配置文件中设置,可在 tidb-ansible conf/tidb.yaml 设置,再滚更 tidb-server 节点。
conf/tidb.yaml
-- 执行计划缓存
prepared_plan_cache:
enabled: true -- 是否开启 prepare 语句的 plan cache,默认值 false
capacity: 100 -- 缓存语句的数量
memory-guard-ratio: 0.1 --用于防止超过 performance.max-memory, 超过 max-proc * (1 - prepared-plan-cache.memory-guard-ratio) 会剔除 LRU 中的元素,最小值为 0;最大值为 1,默认值 0.1
-- 事务内存锁相关配置,当本地事务冲突比较多时建议开启
txn_local_latches:
enable:true -- 是否开启事务内存锁相关配置,默认值 false
capacity: 2048000 -- Hash 对应的 slot 数,会自动向上调整为 2 的指数倍。每个 slot 占 32 Bytes
二、TiKV优化
2.1 TiKV 线程池优化
在 TiKV 4.0 中,线程池主要由 gRPC、Scheduler、UnifyReadPool、Store、Apply、RocksDB 以及其它一些占用 CPU 不多的定时任务与检测组件组成。
● gRPC 线程池是 TiKV 所有读写请求的总入口,它会把不同任务类型的请求转发给不同的线程池。
● Scheduler 线程池负责检测写事务冲突,把事务的两阶段提交、悲观锁上锁、事务回滚等请求转化为 key-value 对数组,然后交给 Store 线程进行 Raft 日志复制。
● Raftstore 线程池负责处理所有的 Raft 消息以及添加新日志的提议(Propose)、将日志写入到磁盘,当日志在 Raft Group 中达成多数一致(即 Raft 论文中描述的 Commit Index)后,它就会把该日志发送给 Apply 线程。
● Apply 线程收到从 Store 线程池发来的已提交日志后将其解析为 key-value 请求,然后写入 RocksDB 并且调用回调函数通知 gRPC 线程池中的写请求完成,返回结果给客户端。
● RocksDB 线程池是 RocksDB 进行 Compact 和 Flush 任务的线程池,关于 RocksDB 的架构与 Compact 操作请参考 RocksDB: A Persistent Key-Value Store for Flash and RAM Storage
● UnifyReadPool 是 TiKV 4.0 推出的新特性,它由之前的 Coprocessor 线程池与 Storage Read Pool 合并而来,所有的读取请求包括 kv get、kv batch get、raw kv get、coprocessor 等都会在这个线程池中执行。
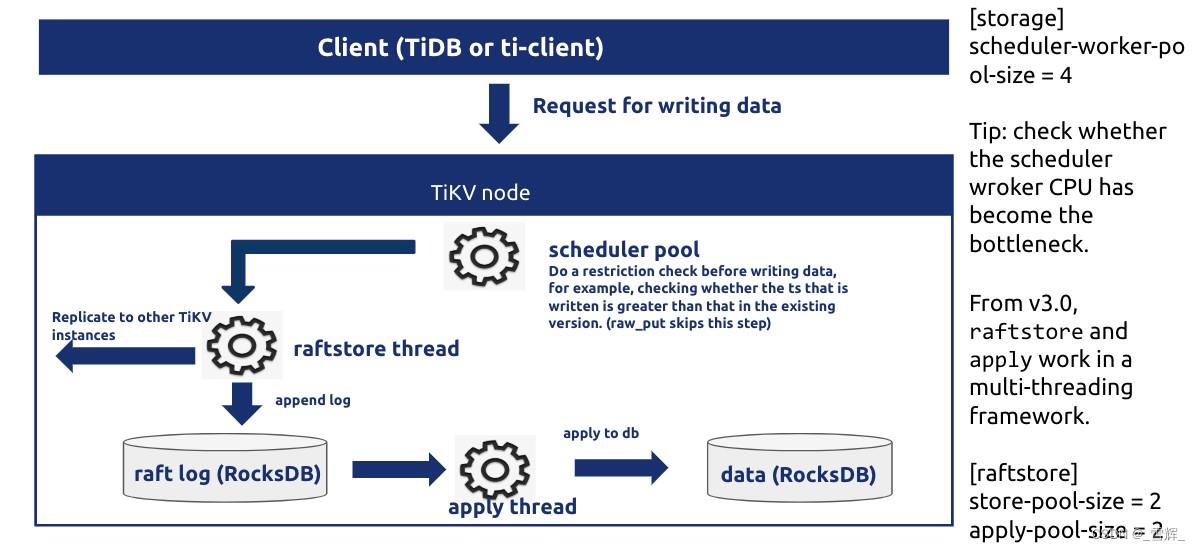
2.1.1 GRPC
gRPC 线程池的大小默认配置(server.grpc-concurrency)是 4。由于 gRPC 线程池几乎不会有多少计算开销,它主要负责网络 IO、反序列化请求,因此该配置通常不需要调整,如果部署的机器 CPU 特别少(小于等于 8),可以考虑将该配置(server.grpc-concurrency)设置为 2,如果机器配置很高,并且 TiKV 承担了非常大量的读写请求,观察到 Grafana 上的监控 Thread CPU 的 gRPC poll CPU 的数值超过了 server.grpc-concurrency 大小的 80%,那么可以考虑适当调大 server.grpc-concurrency 以控制该线程池使用率在 80% 以下。
2.1.2 Scheduler
Scheduler 线程池的大小配置 (storage.scheduler-worker-pool-size) 在 TiKV 检测到机器 CPU 数大于等于 16 时默认为 8,小于 16 时默认为 4。它主要用于将复杂的事务请求转化为简单的 key-value 读写。但是 scheduler 线程池本身不进行任何写操作,如果检测到有事务冲突,那么它会提前返回冲突结果给客户端,否则的话它会把需要写入的 key-value 合并成一条 Raft 日志交给 raftstore 线程进行 raft 日志复制。通常来说为了避免过多的线程切换,最好确保 scheduler 线程池的利用率保持在 50%~75% 之间。(如果线程池大小为 8 的话,那么 Grafana 上的 Thread CPU 的 scheduler worker CPU 应当在 400%~600% 之间较为合理)
2.1.3 Raftstore
Raftstore 线程池是 TiKV 最为复杂的一个线程池,默认大小(raftstore.store-pool-size)为 2,所有的写请求都会先在 store 线程 fsync 的方式写入 RocksDB (除非手动将 raftstore.sync-log 设置为 true;而 raftstore.sync-log 设置为 false,可以提升一部分写性能,但也会造成数据丢失的可能)。由于存在 IO,store 线程理论上不可能达到 100% 的 CPU。为了尽可能地减少写磁盘次数,将多个写请求攒在一起写入 RocksDB,最好控制其 CPU 使用在 40% ~ 60%。千万不要为了提升写性能盲目增大 store 线程池大小,这样可能反而会适得其反,增加了磁盘负担让性能变差。
● 监控 Raft IO 中的 append log duration 表示 Store 线程处理一批 Raft Message 并且将需要持久化的日志写入 RocksDB (这里存储的格式是 Raft 日志格式)中的时间。如果该指标较高(P99 大于 500ms),说明盘比较慢(查看监控 Node Exporter 中的 disk latency 判断盘的性能是否有问题),或者是写入 RocksDB 时触发了 Write Stall 。此时可以查看 RocksDB-raft 中的 write stall duration,该指标正常情况下应该为 0, 若不为 0 则可能发送了 write stall。
2.1.4 UnifyReadPool
UnifyReadPool 负责处理所有的读取请求。默认配置(readpool.unified.max-thread-count)大小为机器 CPU 数的 80%。通常建议根据业务负载特性调整其 CPU 使用率在 60%~90% 之间。
2.1.5 RocksDB
RocksDB 线程池是 RocksDB 进行 Compact 和 Flush 任务的线程池,通常不需要配置,如果机器 CPU 数较少,可将 rocksdb.max-background-jobs 与 raftdb.max-background-jobs 同时改为 4. 如果遇到了 Write Stall ,查看 Grafana 监控上 RocksDB-kv 中的 Write Stall Reason 有哪些指标不为 0。如果是由 pending compaction bytes 相关原因引起的,可将 rocksdb.max-sub-compactions 设置为 2 (该配置表示单次 compaction job 允许使用的子线程数量)。如果原因是 memtable count 相关,建议调大所有列的 max-write-buffer-number (默认为 5)。如果原因是 level0 file limit 相关,建议调大如下参数:
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger
2.2 海量 Region 集群调优
在 TiDB 的架构中,所有数据以一定 range 将数据 key 切分成若干 Region 分布在多个 TiKV 实例上。随着数据的写入,一个集群中会产生上百万个甚至千万个 Region。单个 TiKV 实例上产生过多的 Region 会给集群带来较大的负担,影响整个集群的性能表现。
2.2.1 Raftstore 的工作流程
一个 TiKV 实例上有多个 Region。Region 消息是通过 Raftstore 模块驱动 Raft 状态机来处理的。这些消息包括 Region 上读写请求的处理、Raft log 的持久化和复制、Raft 的心跳处理等。但是,Region 数量增多会影响整个集群的性能。为了解释这一点,需要先了解 TiKV 的核心模块 Raftstore 的工作流程。

注意: 该图仅为示意,不代表代码层面的实际结构。
上图是 Raftstore 处理流程的示意图。如图所示,从 TiDB 发来的请求会通过 gRPC 和 storage 模块变成最终的 KV 读写消息,并被发往相应的 Region,而这些消息并不会被立即处理而是被暂存下来。Raftstore 会轮询检查每个 Region 是否有需要处理的消息。如果 Region 有需要处理的消息,那么 Raftstore 会驱动 Raft 状态机去处理这些消息,并根据这些消息所产生的状态变更去进行后续操作。例如,在有写请求时,Raft 状态机需要将日志落盘并且将日志发送给其他 Region 副本;在达到心跳间隔时,Raft 状态机需要将心跳信息发送给其他 Region 副本。
2.2.2 性能问题
从 Raftstore 处理流程示意图可以看出,需要依次处理各个 Region 的消息。那么在 Region 数量较多的情况下,Raftstore 需要花费一些时间去处理大量 Region 的心跳,从而带来一些延迟,导致某些读写请求得不到及时处理。如果读写压力较大,Raftstore 线程的 CPU 使用率容易达到瓶颈,导致延迟进一步增加,进而影响性能表现。
通常在有负载的情况下,如果 Raftstore 的 CPU 使用率达到了 85% 以上,即可视为达到繁忙状态且成为了瓶颈,同时 Grafana TiKV 监控 Raft Propose 面板 propose wait duration 可能会高达百毫秒级别。
注意: Raftstore 的 CPU 使用率是指单线程的情况。如果是多线程 Raftstore,可等比例放大使用率。 由于 Raftstore 线程中有 I/O 操作,所以 CPU 使用率不可能达到 100%。
性能监控
可在 Grafana 的 TiKV 面板下查看相关的监控 metrics:
Thread-CPU 下的 Raft store CPU
参考值:低于 raftstore.store-pool-size * 85%。
Propose wait duration 是从发送请求给 Raftstore,到 Raftstore 真正开始处理请求之间的延迟时间。如果该延迟时间较长,说明 Raftstore 比较繁忙或者处理 append log 比较耗时导致 Raftstore 不能及时处理请求。
参考值:低于 50-100ms。
2.2.3 性能优化方法
找到性能问题的根源后,可从以下两个方向来解决性能问题:
减少单个 TiKV 实例的 Region 数
减少单个 Region 的消息数
方法一:增加 TiKV 实例
如果 I/O 资源和 CPU 资源都比较充足,可在单台机器上部署多个 TiKV 实例,以减少单个 TiKV 实例上的 Region 个数;或者增加 TiKV 集群的机器数。
方法二:调整 raft-base-tick-interval
除了减少 Region 个数外,还可以通过减少 Region 单位时间内的消息数量来减小 Raftstore 的压力。例如,在 TiKV 配置中适当调大 raft-base-tick-interval:
[raftstore]
raft-base-tick-interval = "2s"
raft-base-tick-interval 是 Raftstore 驱动每个 Region 的 Raft 状态机的时间间隔,也就是每隔该时长就需要向 Raft 状态机发送一个 tick 消息。增加该时间间隔,可以有效减少 Raftstore 的消息数量。 需要注意的是,该 tick 消息的间隔也决定了 election timeout 和 heartbeat 的间隔。示例如下:
raft-election-timeout = raft-base-tick-interval * raft-election-timeout-ticks
raft-heartbeat-interval = raft-base-tick-interval * raft-heartbeat-ticks
如果 Region Follower 在 raft-election-timeout 间隔内未收到来自 Leader 的心跳,就会判断 Leader 出现故障而发起新的选举。raft-heartbeat-interval 是 Leader 向 Follower 发送心跳的间隔,因此调大 raft-base-tick-interval 可以减少单位时间内 Raft 发送的网络消息,但也会让 Raft 检测到 Leader 故障的时间更长。
方法三:提高 Raftstore 并发数
TiKV 默认将 raftstore.store-pool-size 配置为 2。如果 Raftstore 出现瓶颈,可以根据实际情况适当调高该参数值,但不建议设置过高以免引入不必要的线程切换开销。
方法四:开启 Hibernate Region 功能
在实际情况中,读写请求并不会均匀分布到每个 Region 上,而是集中在少数的 Region 上。那么可以尽量减少暂时空闲的 Region 的消息数量,这也就是 Hibernate Region 的功能。无必要时可不进行 raft-base-tick,即不驱动空闲 Region 的 Raft 状态机,那么就不会触发这些 Region 的 Raft 产生心跳信息,极大地减小了 Raftstore 的工作负担。
截至 TiDB v4.0,Hibernate Region 仍是一个实验功能,在 TiKV master 分支上已经默认开启。可根据实际情况和需求来开启该功能。Hibernate Region 的配置说明请参考配置 Hibernate Region。
方法五:开启 Region Merge
注意: Region Merge 在 TiDB v4.0 中默认开启。
开启 Region Merge 也能减少 Region 的个数。与 Region Split 相反,Region Merge 是通过调度把相邻的小 Region 合并的过程。在集群中删除数据或者执行 Drop Table/Truncate Table 语句后,可以将小 Region 甚至空 Region 进行合并以减少资源的消耗。
通过 pd-ctl 设置以下参数即可开启 Region Merge 以及调整 Region Merge 速度:
pd-ctl config set max-merge-region-size 20
pd-ctl config set max-merge-region-keys 200000
pd-ctl config set merge-schedule-limit 8
2.2.4 其他常见优化设置
Block-cache TiKV 使用了 RocksDB 的 Column Family (CF) 特性,KV 数据最终存储在默认 RocksDB 内部的 default、write、lock 3 个 CF 内。
default CF 存储的是真正的数据,与其对应的参数位于 [rocksdb.defaultcf] 项中。
write CF 存储的是数据的版本信息(MVCC)、索引、小表相关的数据,相关的参数位于 [rocksdb.writecf] 项中。
lock CF 存储的是锁信息,系统使用默认参数。
Raft RocksDB 实例存储 Raft log。default CF 主要存储的是 Raft log,与其对应的参数位于 [raftdb.defaultcf] 项中。
TiDB 3.0 版本及以上所有 CF 共享一个 Block-cache,用于缓存数据块,加速 RocksDB 的读取速度,TiDB 2.1 版本及以下通过参数 block-cache-size 控制每个 CF Block-cache 大小,Block-cache 越大,能够缓存的热点数据越多,对读取操作越有利,同时占用的系统内存也会越多。
每个 CF 有各自的 Write-buffer,大小通过 write-buffer-size 控制。
TiDB 3.0 版本及以上部署 TiKV 多实例情况下,需要修改 conf/tikv.yml 中 block-cache-size 下面的 capacity 参数:
storage:
block-cache:
capacity: "1GB"
注意: TiKV 实例数量指每个服务器上 TiKV 的进程数量。 推荐设置:capacity = MEM_TOTAL * 0.5 / TiKV 实例数量
- Sync-log
通过使用 Raft 一致性算法,数据在各 TiKV 节点间复制为多副本,以确保某个节点挂掉时数据的安全性。只有当数据已写入超过 50% 的副本时,应用才返回 ACK(三副本中的两副本)。但理论上两个节点也可能同时发生故障,所以除非是对性能要求高于数据安全的场景,一般都强烈推荐开启 sync-log。一般来说,开启 sync-log 会让性能损耗 30% 左右。
可以修改 conf/tikv.yml 中 raftstore 下面的 sync-log 参数:
[raftstore]
sync-log = true
以上是关于TiDB性能调优的主要内容,如果未能解决你的问题,请参考以下文章