开源软件:NoSql数据库 - 图数据库 Cassandra
Posted 非淡泊无以明志,非宁静无以致远 - 长安快马
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源软件:NoSql数据库 - 图数据库 Cassandra相关的知识,希望对你有一定的参考价值。
转载原文:http://www.cnblogs.com/loveis715/p/5299495.html
在前面的一篇文章《图形数据库Neo4J简介》中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法。而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介绍。
接触Cassandra的原因与接触Neo4J的原因相同:我们的产品需要能够记录一系列关系型数据库所无法快速处理的大量数据。Cassandra,以及后面将要介绍的MongoDB,都是我们在技术选型过程中的一个备选方案。虽然说最后我们并没有选择Cassandra,但是在整个技术选型过程中所接触到的一系列内部机制,思考方式等都是非常有趣的。而且在整个选型过程中也借鉴了CAM(Cloud Availability Manager)组在实际使用过程中所得到的一些经验。因此我在这里把自己的笔记总结成一篇文章,分享出来。
技术选型
技术选型常常是一个非常严谨的过程。由于一个项目通常是由数十位甚至上百位开发人员协同开发的,因此一个精准的技术选型常常能够大幅提高整个项目的开发效率。在尝试为某一类需求设计解决方案时,我们常常会有很多种可以选择的技术。为了能够精准地选择一个适合于这些需求的技术,我们就需要考虑一系列有关学习曲线,开发,维护等众多方面的因素。这些因素主要包括:
- 该技术所提供的功能是否能够完整地解决问题。
- 该技术的扩展性如何。是否允许用户添加自定义组成来满足特殊的需求。
- 该技术是否有丰富完整的文档,并且能够以免费甚至付费的形式得到专业的支持。
- 该技术是否有很多人使用,尤其是一些大型企业在使用,并存在着成功的案例。
在该过程中,我们会逐渐筛选市面上所能找到的各种技术,并最终确定适合我们需求的那一种。
针对我们刚刚所提到的需求——记录并处理系统自动生成的大量数据,我们在技术选型的初始阶段会有很多种选择:Key-Value数据库,如Redis,Document-based数据库,如MongoDB,Column-based数据库,如Cassandra等。而且在实现特定功能时,我们常常可以通过以上所列的任何一种数据库来搭建一个解决方案。可以说,如何在这三种数据库之间选择常常是NoSQL数据库初学者所最为头疼的问题。导致这种现象的一个原因就是,Key-Value,Document-based以及Column-based实际上是对NoSQL数据库的一种较为泛泛的分类。不同的数据库提供商所提供的NoSQL数据库常常具有略为不同的实现方式,并提供了不同的功能集合,进而会导致这些数据库类型之间的边界并不是那么清晰。
恰如其名所示,Key-Value数据库会以键值对的方式来对数据进行存储。其内部常常通过哈希表这种结构来记录数据。在使用时,用户只需要通过Key来读取或写入相应的数据即可。因此其在对单条数据进行CRUD操作时速度非常快。而其缺陷也一样明显:我们只能通过键来访问数据。除此之外,数据库并不知道有关数据的其它信息。因此如果我们需要根据特定模式对数据进行筛选,那么Key-Value数据库的运行效率将非常低下,这是因为此时Key-Value数据库常常需要扫描所有存在于Key-Value数据库中的数据。
因此在一个服务中,Key-Value数据库常常用来作为服务端缓存使用,以记录一系列经由较为耗时的复杂计算所得到的计算结果。最著名的就是Redis。当然,为Memcached添加了持久化功能的MemcacheDB也是一种Key-Value数据库。
Document-based数据库和Key-Value数据库之间的不同主要在于,其所存储的数据将不再是一些字符串,而是具有特定格式的文档,如XML或JSON等。这些文档可以记录一系列键值对,数组,甚至是内嵌的文档。如:

1 {
2 Name: "Jefferson",
3 Children: [{
4 Name:"Hillary",
5 Age: 14
6 }, {
7 Name:"Todd",
8 Age: 12
9 }],
10 Age: 45,
11 Address: {
12 number: 1234,
13 street: "Fake road",
14 City: "Fake City",
15 state: "NY",
16 Country: "USA"
17 }
18 }
有些读者可能会有疑问,我们同样也可以通过Key-Value数据库来存储JSON或XML格式的数据,不是么?答案就是Document-based数据库常常会支持索引。我们刚刚提到过,Key-Value数据库在执行数据的查找及筛选时效率非常差。而在索引的帮助下,Document-based数据库则能够很好地支持这些操作了。有些Document-based数据库甚至允许执行像关系型数据库那样的JOIN操作。而且相较于关系型数据库,Document-based数据库也将Key-Value数据库的灵活性得以保留。
而Column-based数据库则与前面两种数据库非常不同。我们知道,一个关系型数据库中所记录的数据常常是按照行来组织的。每一行中包含了表示不同意义的多个列,并被顺序地记录在持久化文件中。我们知道,关系型数据库中的一个常见操作就是对具有特定特征的数据进行筛选及操作,而且该操作常常是通过WHERE子句来完成的:
1 SELECT * FROM customers WHERE country=\'Mexico\';
在一个传统的关系型数据库中,该语句所操作的表可能如下所示:
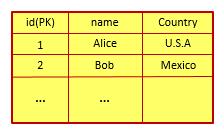
而在该表所对应的数据库文件中,每一行中的各个数值将被顺序记录,从而形成了如下图所示的数据文件:
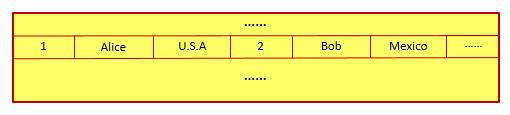
因此在执行上面的SQL语句时,关系型数据库并不能连续操作文件中所记录的数据:

这大大降低了关系型数据库的性能:为了运行该SQL语句,关系型数据库需要读取每一行中的id域和name域。这将导致关系型数据库所要读取的数据量显著增加,也需要在访问所需数据时执行一系列偏移量计算。况且上面所举的例子仅仅是一个最简单的表。如果表中包含了几十列,那么数据读取量将增大几十倍,偏移量计算也会变得更为复杂。
那么我们应该如何解决这个问题呢?答案就是将一列中的数据连续地存在一起:
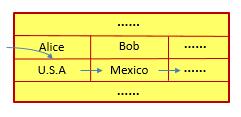
而这就是Column-based数据库的核心思想:按照列来在数据文件中记录数据,以获得更好的请求及遍历效率。这里有两点需要注意:首先,Column-based数据库并不表示会将所有的数据按列进行组织,也没有那个必要。对某些需要执行请求的数据进行按列存储即可。另外一点则是,Cassandra对Query的支持实际上是与其所使用的数据模型关联在一起的。也就是说,对Query的支持很有限。我们马上就会在下面的章节中对该限制进行介绍。
至此为止,您应该能够根据各种数据库所具有的特性来为您的需求选择一个合适的NoSQL数据库了。
Cassandra初体验
OK,在简单地介绍了Key-Value,Document-based以及Column-based三种不同类型的NoSQL数据库之后,我们就要开始尝试着使用Cassandra了。鉴于我个人在使用一系列NoSQL数据库时常常遇到它们的版本更新缺乏API后向兼容性这一情况,我在这里直接使用了Datastax Java Driver的样例。这样读者也能从该页面中查阅针对最新版本客户端的示例代码。
一段最简单的读取一条记录的Java代码如下所示:
Cluster cluster = null;
try {
// 创建连接到Cassandra的客户端
cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.build();
// 创建用户会话
Session session = cluster.connect();
// 执行CQL语句
ResultSet rs = session.execute("select release_version from system.local");
// 从返回结果中取出第一条结果
Row row = rs.one();
System.out.println(row.getString("release_version"));
} finally {
// 调用cluster变量的close()函数并关闭所有与之关联的链接
if (cluster != null) {
cluster.close();
}
}
看起来很简单,是么?其实在客户端的帮助下,操作Cassandra实际上并不是非常困难的一件事。反过来,如何为Cassandra所记录的数据设计模型才是最需要读者仔细考虑的。与大家所最为熟悉的关系型数据库建模方式不同,Cassandra中的数据模型设计需要是Join-less的。简单地说,那就是由于这些数据分布在Cassandra的不同结点上,因此这些数据的Join操作并不能被高效地执行。
那么我们应该如何为这些数据定义模型呢?首先我们要了解Cassandra所支持的基本数据模型。这些基本数据模型有:Column,Super Column,Column Family以及Keyspace。下面我们就对它们进行简单地介绍。
Column是Cassandra所支持的最基础的数据模型。该模型中可以包含一系列键值对:
1 {
2 "name": "Auther Name",
3 "value": "Sam",
4 "timestamp": 123456789
5 }
Super Column则包含了一系列Column。在一个Super Column中的属性可以是一个Column的集合:
1 {
2 "name": "Cassandra Introduction",
3 "value": {
4 "auther": { "name": "Auther Name", "value": "Sam", "timestamp": 123456789},
5 "publisher": { "name": "Publisher", "value": "China Press", "timestamp": 234567890}
6 }
7 }
这里需要注意的是,Cassandra文档已经不再建议过多的使用Super Column,而原因却没有直接说明。据说这和Super Column常常需要在数据访问时执行反序列化相关。一个最为常见的证据就是,网络上常常会有一些开发人员在Super Column中添加了过多的数据,并进而导致和这些Super Column相关的请求运行缓慢。当然这只是猜测。只不过既然官方文档都已经开始对Super Column持谨慎意见,那么我们也需要在日常使用过程中尽量避免使用Super Column。
而一个Column Family则是一系列Column的集合。在该集合中,每个Column都会有一个与之相关联的键:
1 Authers = {
2 “1332”: {
3 "name": "Auther Name",
4 "value": "Sam",
5 "timestamp": 123456789
6 },
7 “1452”: {
8 “name”: “Auther Name”,
9 “value”: “Lucy”,
10 “timestamp”: 012343437
11 }
12 }
上面的Column Family示例中所包含的是一系列Column。除此之外,Column Family还可以包含一系列Super Column(请谨慎使用)。
最后,Keyspace则是一系列Column Family的集合。
发现了么?上面没有任何一种方法能够通过一个Column(Super Column)引用另一个Column(Super Column),而只能通过Super Column包含其它Column的方式来完成这种信息的包含。这与我们在关系数据库设计过程中通过外键与其它记录相关联的使用方法非常不同。还记得之前我们通过外键来创建数据关联这一方法的名称么?对的,Normalization。该方法可以通过外键所指示的关联关系有效地消除在关系型数据库中的冗余数据。而在Cassandra中,我们要使用的方法就是Denormalization,也即是允许可以接受的一定程度的数据冗余。也就是说,这些关联的数据将直接记录在当前数据类型之中。
在使用Cassandra时,哪些不该抽象为Cassandra数据模型,而哪些数据应该有一个独立的抽象呢?这一切决定于我们的应用所常常执行的读取及写入请求。想想我们为什么使用Cassandra,或者说Cassandra相较于关系型数据库的优势:快速地执行在海量数据上的读取或写入请求。如果我们仅仅根据所操作的事物抽象数据模型,而不去理会Cassandra在这些模型之上的执行效率,甚至导致这些数据模型无法支持相应的业务逻辑,那么我们对Cassandra的使用也就没有实际的意义了。因此一个较为正确的做法就是:首先根据应用的需求来定义一个抽象概念,并开始针对该抽象概念以及应用的业务逻辑设计在该抽象概念上运行的请求。接下来,软件开发人员就可以根据这些请求来决定如何为这些抽象概念设计模型了。
在抽象设计模型时,我们常常需要面对另外一个问题,那就是如何指定各Column Family所使用的各种键。在Cassandra相关的各类文档中,我们常常会遇到以下一系列关键的名词:Partition Key,Clustering Key,Primary Key以及Composite Key。那么它们指的都是什么呢?
Primary Key实际上是一个非常通用的概念。在Cassandra中,其表示用来从Cassandra中取得数据的一个或多个列:
1 create table sample ( 2 key text PRIMARY KEY, 3 data text 4 );
在上面的示例中,我们指定了key域作为sample的PRIMARY KEY。而在需要的情况下,一个Primary Key也可以由多个列共同组成:
1 create table sample {
2 key_one text,
3 key_two text,
4 data text,
5 PRIMARY KEY(key_one, key_two)
6 };
在上面的示例中,我们所创建的Primary Key就是一个由两个列key_one和key_two组成的Composite Key。其中该Composite Key的第一个组成被称为是Partition Key,而后面的各组成则被称为是Clustering Key。Partition Key用来决定Cassandra会使用集群中的哪个结点来记录该数据,每个Partition Key对应着一个特定的Partition。而Clustering Key则用来在Partition内部排序。如果一个Primary Key只包含一个域,那么其将只拥有Partition Key而没有Clustering Key。
Partition Key和Clustering Key同样也可以由多个列组成:
1 create table sample {
2 key_primary_one text,
3 key_primary_two text,
4 key_cluster_one text,
5 key_cluster_two text,
6 data text,
7 PRIMARY KEY((key_primary_one, key_primary_two), key_cluster_one, key_cluster_two)
8 };
而在一个CQL语句中,WHERE等子句所标示的条件只能使用在Primary Key中所使用的列。您需要根据您的数据分布决定到底哪些应该是Partition Key,哪些应该作为Clustering Key,以对其中的数据进行排序。
一个好的Partition Key设计常常会大幅提高程序的运行性能。首先,由于Partition Key用来控制哪个结点记录数据,因此Partition Key可以决定是否数据能够较为均匀地分布在Cassandra的各个结点上,以充分利用这些结点。同时在Partition Key的帮助下,您的读请求应尽量使用较少数量的结点。这是因为在执行读请求时,Cassandra需要协调处理从各个结点中所得到的数据集。因此在响应一个读操作时,较少的结点能够提供较高的性能。因此在模型设计中,如何根据所需要运行的各个请求指定模型的Partition Key是整个设计过程中的一个关键。一个取值均匀分布的,却常常在请求中作为输入条件的域,常常是一个可以考虑的Partition Key。
除此之外,我们也应该好好地考虑如何设置模型的Clustering Key。由于Clustering Key可以用来在Partition内部排序,因此其对于包含范围筛选的各种请求的支持较好。
Cassandra内部机制
在本节中,我们将对Cassandra的一系列内部机制进行简单地介绍。这些内部机制很多都是业界所常用的解决方案。因此在了解了Cassandra是如何使用它们的之后,您就可以非常容易地理解其它类库对这些机制的使用,甚至在您自己的项目中借鉴及使用它们。
这些常见的内部机制有:Log-Structured Merge-Tree,Consistent Hash,Virtual Node等。
Log-Structured Merge-Tree
最有意思的一个数据结构莫过于Log-Structured Merge-Tree。Cassandra内部使用类似的结构来提高服务实例的运行效率。那它是如何工作的呢?
简单地说,一个Log-Structured Merge-Tree主要由两个树形结构的数据组成:存在于内存中的C0,以及主要存在于磁盘中的C1:
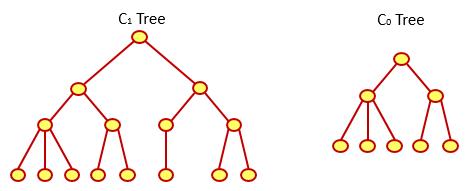
在添加一个新的结点时,Log-Structured Merge-Tree会首先在日志文件中添加一条有关该结点插入的记录,然后再将该结点插入到树C0中。添加到日志文件中的记录主要是基于数据恢复的考虑。毕竟C0树处于内存中,非常容易受到系统宕机等因素的影响。而在读取数据时,Log-Structured Merge-Tree会首先尝试从C0树中查找数据,然后再在C1树中查找。
在C0树满足一定条件之后,如其所占用的内存过大,那么它所包含的数据将被迁移到C1中。在Log-Structured Merge-Tree这个数据结构中,该操作被称为是rolling merge。其会把C0树中的一系列记录归并到C1树中。归并的结果将会写入到新的连续的磁盘空间。
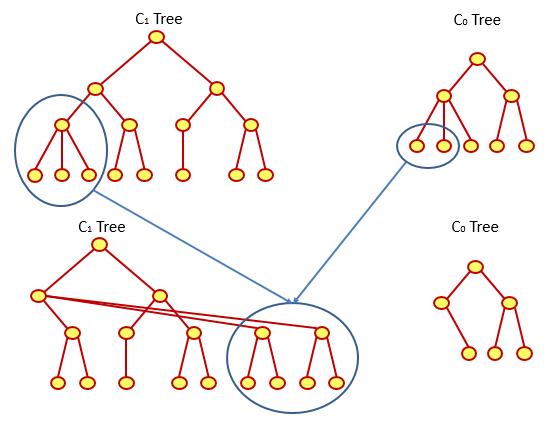
几乎是论文中的原图
就单个树来看,C1和我们所熟悉的B树或者B+树有点像,是不?
不知道您注意到没有。上面的介绍突出了一个词:连续的。这是因为C1树中同一层次的各个结点在磁盘中是连续记录的。这样磁盘就可以通过连续读取来避免在磁盘上的过多寻道,从而大大地提高了运行效率。
Memtable和SSTable
好,刚刚我们已经提到了Cassandra内部使用和Log-Structured Merge-Tree类似的数据结构。那么在本节中,我们就将对Cassandra的一些主要数据结构及操作流程进行介绍。可以说,如果您大致理解了上一节对Log-Structured Merge-Tree的讲解,那么理解这些数据结构也将是非常容易的事情。
在Cassandra中有三个非常重要的数据结构:记录在内存中的Memtable,以及保存在磁盘中的Commit Log和SSTable。Memtable在内存中记录着最近所做的修改,而SSTable则在磁盘上记录着Cassandra所承载的绝大部分数据。在SSTable内部记录着一系列根据键排列的一系列键值对。通常情况下,一个Cassandra表会对应着一个Memtable和多个SSTable。除此之外,为了提高对数据进行搜索和访问的速度,Cassandra还允许软件开发人员在特定的列上创建索引。
鉴于数据可能存储于Memtable,也可能已经被持久化到SSTable中,因此Cassandra在读取数据时需要合并从Memtable和SSTable所取得的数据。同时为了提高运行速度,减少不必要的对SSTable的访问,Cassandra提供了一种被称为是Bloom Filter的组成:每个SSTable都有一个Bloom Filter,以用来判断与其关联的SSTable是否包含当前查询所请求的一条或多条数据。如果是,Cassandra将尝试从该SSTable中取出数据;如果不是,Cassandra则会忽略该SSTable,以减少不必要的磁盘访问。
在经由Bloom Filter判断出与其关联的SSTable包含了请求所需要的数据之后,Cassandra就会开始尝试从该SSTable中取出数据了。首先,Cassandra会检查Partition Key Cache是否缓存了所要求数据的索引项Index Entry。如果存在,那么Cassandra会直接从Compression Offset Map中查询该数据所在的地址,并从该地址取回所需要的数据;如果Partition Key Cache并没有缓存该Index Entry,那么Cassandra首先会从Partition Summary中找到Index Entry所在的大致位置,并进而从该位置开始搜索Partition Index,以找到该数据的Index Entry。在找到Index Entry之后,Cassandra就可以从Compression Offset Map找到相应的条目,并根据条目中所记录的数据的位移取得所需要的数据:
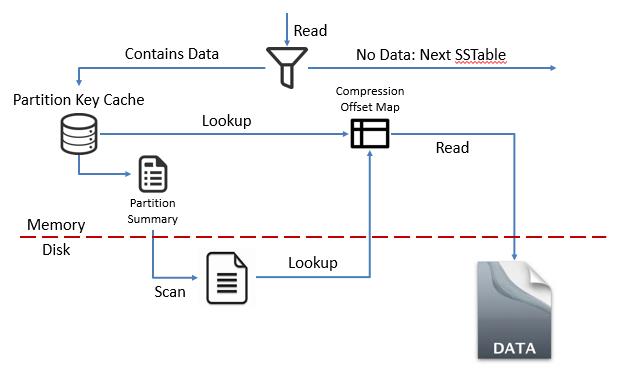
较文档中原图略作调整
发现了么?实际上SSTable中所记录的数据仍然是顺序记录的各个域,但是不同的是,它的查找首先经由了Partition Key Cache以及Compression Offset Map等一系列组成。这些组成仅仅包含了一系列对应关系,也就是相当于连续地记录了请求所需要的数据,进而提高了数据搜索的运行速度,不是么?
Cassandra的写入流程也与Log-Structured Merge-Tree的写入流程非常类似:Log-Structured Merge-Tree中的日志对应着Commit Log,C0树对应着Memtable,而C1树则对应着SSTable的集合。在写入时,Cassandra会首先将数据写入到Memtable中,同时在Commit Log的末尾添加该写入所对应的记录。这样在机器断电等异常情况下,Cassandra仍能通过Commit Log来恢复Memtable中的数据。
在持续地写入数据后,Memtable的大小将逐渐增长。在其大小到达某个阈值时,Cassandra的数据迁移流程就将被触发。该流程一方面会将Memtable中的数据添加到相应的SSTable的末尾,另一方面则会将Commit Log中的写入记录移除。
这也就会造成一个容易让读者困惑的问题:如果是将新的数据写入到SSTable的末尾,那么数据迁移的过程该如何执行对数据的更新?答案就是:在需要对数据进行更新时,Cassandra会在SSTable的末尾添加一条具有当前时间戳的记录,以使得其能够标明自身为最新的记录。而原有的在SSTable中的记录随即宣告失效。
这会导致一个问题,那就是对数据的大量更新会导致SSTable所占用的磁盘空间迅速增长,而且其中所记录的数据很多都已经是过期数据。因此在一段时间之后,磁盘的空间利用率会大幅下降。此时我们就需要通过压缩SSTable的方式释放这些过期数据所占用的空间:
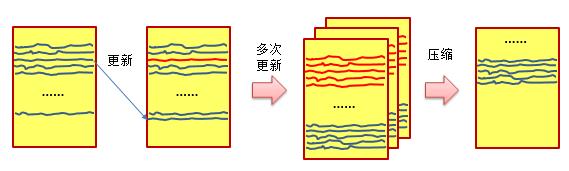
现在有一个问题,那就是我们可以根据重复数据的时间戳来判断哪条是最新的数据,但是我们应该如何处理数据的删除呢?在Cassandra中,对数据的删除是通过一个被称为tombstone的组成来完成的。如果一条数据被添加了一个tombstone,那么其在下次压缩时就被认为是一条已经被删除的数据,从而不会添加到压缩后的SSTable中。
在压缩过程中,原有的SSTable和新的SSTable同时存在于磁盘上。这些原有的SSTable用来完成对数据读取的支持。一旦新的SSTable创建完毕,那么老的SSTable就将被删除。
在这里我们要提几点在日常使用Cassandra的过程中需要注意的问题。首先是,由于通过Commit Log来重建Memtable是一个较为耗时的过程,因此我们在需要重建Memtable的一系列操作前需要尝试手动触发归并逻辑,以将该结点上Memtable中的数据持久化到SSTable中。最常见的一种需要重建Memtable的操作就是重新启动Cassandra所在的结点。
另一个需要注意的地方是,不要过度地使用索引。虽然说索引可以大幅地增加数据的读取速度,但是我们同样需要在数据写入时对其进行维护,造成一定的性能损耗。在这点上,Cassandra和传统的关系型数据库没有太大区别。
Cassandra集群
当然,使用单一的数据库实例来运行Cassandra并不是一个好的选择。单一的服务器可能导致服务集群产生单点失效的问题,也无法充分利用Cassandra的横向扩展能力。因此从本节开始,我们就将对Cassandra集群以及集群中所使用的各种机制进行简单地讲解。
在一个Cassandra集群中常常包含着以下一系列组成:结点(Node),数据中心(Data Center)以及集群(Cluster)。结点是Cassandra集群中用来存储数据的最基础结构;数据中心则是处于同一地理区域的一系列结点的集合;而集群则常常由多个处于不同区域的数据中心所组成:
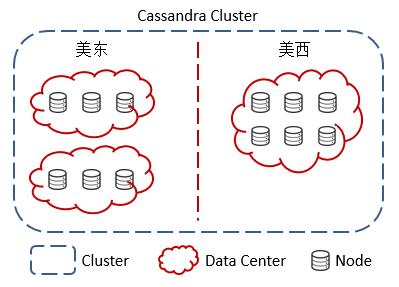
上图所展示的Cassandra集群由三个数据中心组成。这三个数据中心中的两个处于同一区域内,而另一个数据中心则处于另一个区域中。可以说,两个数据中心处于同一区域的情况并不多见,但是Cassandra的官方文档也没有否定这种集群搭建方式。每个数据中心则包含了一系列结点,以用来存储Cassandra集群所要承载的数据。
有了集群,我们就需要使用一系列机制来完成集群之间的相互协作,并考虑集群所需要的一系列非功能性需求了:结点的状态维护,数据分发,扩展性(Scalability),高可用性,灾难恢复等。
对结点的状态进行探测是高可用性的第一步,也是在结点间分发数据的基础。Cassandra使用了一种被称为是Gossip的点对点通讯方案,以在Cassandra集群中的各个结点之间共享及传递各个结点的状态。只有这样,Cassandra才能知道到底哪些结点可以有效地保存数据,进而将对数据的操作分发给各结点。
在保存数据的过程中,Cassandra会使用一个被称为是Partitioner的组成来决定数据到底要分发到哪些结点上。而另一个和数据存储相关的组成就是Snitch。其会提供根据集群中所有结点的性能来决定如何对数据进行读写。
这些组成内部也使用了一系列业界所常用的方法。例如Cassandra内部通过VNode来处理各硬件的性能不同,从而在物理硬件层次上形成一种类似《企业级负载平衡简介》一文所中提到过的Weighted Round Robin的解决方案。再比如其内部使用了Consistent Hash,我们也在《Memcached简介》一文中给出过介绍。
好了,简介完成。在下面几节中,我们就将对Cassandra所使用的这些机制进行介绍。
Gossip
首先就是Gossip。其是用来在Cassandra集群中的各个结点之间传输结点状态的协议。它每秒都将运行一次,并将当前Cassandra结点的状态以及其所知的其它结点的状态与至多三个其它结点交换。通过这种方法,Cassandra的有效结点能很快地了解当前集群中其它结点的状态。同时这些状态信息还包含一个时间戳,以允许Gossip判断到底哪个状态是更新的状态。
除了在集群中的各个结点之间交换各结点的状态之外,Gossip还需要能够应对对集群进行操作的一系列动作。这些操作包括结点的添加,移除,重新加入等。为了能够更好地处理这些情况,Gossip提出了一个叫做Seed Node的概念。其用来为各个新加入的结点提供一个启动Gossip交换的入口。在加入到Cassandra集群之后,新结点就可以首先尝试着跟其所记录的一系列Seed Node交换状态。这一方面可以得到Cassandra集群中其它结点的信息,进而允许其与这些结点进行通讯,又可以将自己加入的信息通过这些Seed Node传递出去。由于一个结点所得到的结点状态信息常常被记录在磁盘等持久化组成中,因此在重新启动之后,其仍然可以通过这些持久化后的结点信息进行通讯,以重新加入Gossip交换。而在一个结点失效的情况下,其它结点将会定时地向该结点发送探测消息,以尝试与其恢复连接。但是这会为我们永久地移除一个结点带来麻烦:其它Cassandra结点总觉得该结点将在某一时刻重新加入集群,因此一直向该结点发送探测信息。此时我们就需要使用Cassandra所提供的结点工具了。
那么Gossip是如何判断是否某个结点失效了呢?如果在交换过程中,参与交换的另一方很久不回答,那么当前结点就会将目标结点标示为失效,并进而通过Gossip协议将该状态传递出去。由于Cassandra集群的拓扑结构可能非常复杂,如跨区域等,因此其用来判断一个结点是否失效的标准并不是在多长时间之内没有响应就判定为失效。毕竟这会导致很大的问题:两个在同一个Lab中的结点进行状态交换会非常快,而跨区域的交换则会比较慢。如果我们设置的时间较短,那么跨区域的状态交换常常会被误报为失效;如果我们所设置的时间较长,那么Gossip对结点失效的探测灵敏度将降低。为了避免这种情况,Gossip使用的是一种根据以往结点间交换历史等众多因素综合起来的决策逻辑。这样对于两个距离较远的结点,其将拥有较大的时间窗,从而不会产生误报。而对于两个距离较近的结点,Gossip将使用较小的时间窗,从而提高探测的灵敏度。
Consistent Hash
接下来我们要讲的是Consistent Hash。在通常的哈希算法中常常包含着桶这个概念。每次哈希计算都是在决定特定数据需要存储在哪个桶中。而如果桶的数量发生了变化,那么之前的哈希计算结果都将失效。而Consistent Hash则很好地解决了该问题。
那Consistent Hash是如何工作的呢?首先请考虑一个圆,在该圆上分布了多个点,以表示整数0到1023。这些整数平均分布在整个圆上:
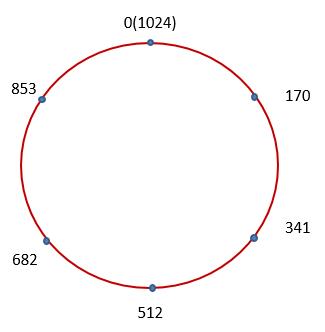
在上图中,我们突出地显示了将圆六等分的六个蓝点,表示用来记录数据的六个结点。这六个结点将各自负责一个范围。例如512这个蓝点所对应的结点就将记录从哈希值为512到681这个区间的数据。在Cassandra以及其它的一些领域中,这个圆被称为是一个Ring。接下来我们就对当前需要存储的数据执行哈希计算,并得到该数据所对应的哈希值。例如一段数据的哈希值为900,那么它就位于853和1024之间:
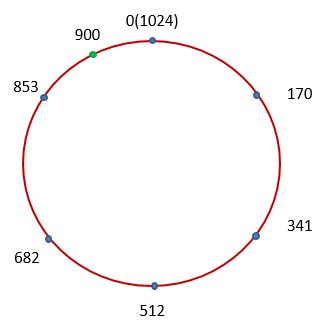
因此该数据将被蓝点853所对应的结点记录。这样一旦其它结点失效,该数据所在的结点也不会发生变化:
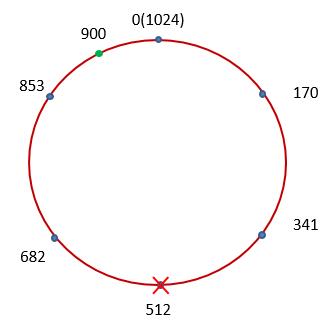
那每段数据的哈希值到底是如何计算出来的呢?答案是Partitioner。其输入为数据的Partition Key。而其计算结果在Ring上的位置就决定了到底是由哪些结点来完成对数据的保存。
Virtual Node
上面我们介绍了Consistent Hash的运行原理。但是这里还有一个问题,那就是失效的那个结点上的数据该怎么办?我们就无法访问了么?这取决于我们对Cassandra集群数据复制方面的设置。通常情况下,我们都会启用该功能,从而使得多个结点同时记录一份数据的拷贝。那么在其中一个结点失效的情况下,其它结点仍然可以用来读取该数据。
这里要处理的一个情况就是,各个物理结点所具有的容量并不相同。简单地说,如果一个结点所能提供的服务能力远小于其它结点,那么为其分配相同的负载将使得它不堪重负。为了处理这种情况,Cassandra提供了一种被称为VNode的解决方案。在该解决方案中,每个物理结点将根据其实际容量被划分为一系列具有相同容量的VNode。每个VNode则用来负责Ring上的一段数据。例如对于刚刚所展示的具有六个结点的Ring,各个VNode和物理机之间的关系则可能如下所示:
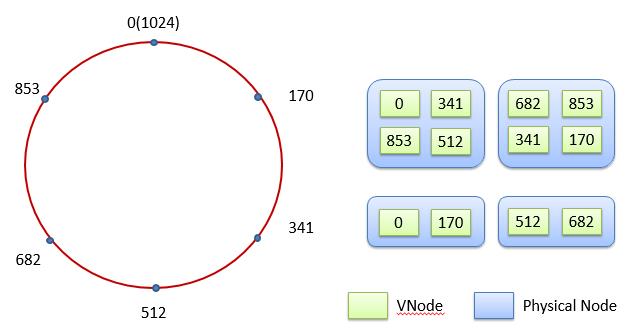
在使用VNode时,我们常常需要注意的一点就是Replication Factor的设置。从其所表示的意义来讲,Cassandra中的Replication Factor和其它常见数据库中所使用的Replication Factor没有什么不同:其所具有的数值用来表示记录在Cassandra中的数据有多少份拷贝。例如在其被设置为1的情况下,Cassandra将只会保存一份数据。如果其被设置为2,那么Cassandra将多保存一份这些数据的拷贝。
在决定Cassandra集群所需要使用的Replication Factor时,我们需要考虑以下一系列因素:
- 物理机的数量。试想一下,如果我们将Replication Factor设置为超过物理机的数量,那么必然会有物理机保存了同一份数据的两部分拷贝。这实际上没有太大的作用:一旦该物理机出现异常,那就会一次损失多份数据。因此就高可用性这一点来说,Replication Factor的数值超过物理机的数量时,多出的这些数据拷贝意义并不大。
- 物理机的异构性。物理机的异构性常常也会影响您所设Replication Factor的效果。举一个极端的例子。如果说我们有一个Cassandra集群而且其由五台物理机组成。其中一台物理机的容量是其它物理机的4倍。那么将Replication Factor设置为3时将会出现具有较大容量的物理机上存储了同样的数据这种问题。其并不比设置为2好多少。
因此在决定一个Cassandra集群的Replication Factor时,我们要仔细地根据集群中物理机的数量和容量设置一个合适的数值。否则其只会导致更多的无用的数据拷贝。
注:这篇文章写于15年8月。鉴于NoSQL数据库发展非常快,而且常常具有一系列影响后向兼容性的更改(如Spring Data Neo4J已经不支持@Fetch)。因此如果您发现有什么描述已经发生了改变,请帮留下评论,以便其它读者参考。在此感激不尽
以上是关于开源软件:NoSql数据库 - 图数据库 Cassandra的主要内容,如果未能解决你的问题,请参考以下文章