统一观测丨使用 Prometheus 监控云原生网关,我们该关注哪些指标?
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统一观测丨使用 Prometheus 监控云原生网关,我们该关注哪些指标?相关的知识,希望对你有一定的参考价值。
Metrics 指标在可观测体系的应用
可观测体系的概念由来已有,随着分布式微服务迅猛发展,对可观测体系的依赖也越来越深,可观测体系通常包括 Metrics、Tracing、Logging 三类数据,再外加报警机制,即可构成完整的监控报警机制,业界对可观测也有系统性说明,如下:

回到我们日常问题排查,基本路径大致分为 Detect(检测)、Troubleshoot(问题初步定位)、Pinpoint(精确定位)三个阶段,其分别对应可观测的三部分内容:Metrics、Traces、Logs,相信读到这里您已经理解 Metrics 指标的重要性了,它是我们发现问题的首要手段。
Metrics 指标的分类
我们希望使用指标来检测问题,首先我们要定义各种指标,指标的定义多种多样,不同的业务应用也都会有其符合自身要求的一些指标,但我们仍然可以对指标做一些粗粒度的分类,如下:
其中最受关注的无疑是核心业务指标,其重要性毋庸置疑,例如所有业务都会具备的三大核心指标:QPS、成功率、RT,其次是基础指标与其他指标。所以任何应用一定要保证核心业务指标准确与实时。同时,搭配基础指标才能对问题发现实现事半功倍的效果,尤其是程序运行期的一些问题。
Metrics 指标在网关场景的应用
聚焦于网关的可观测场景,网关的职责是高效的将符合某组特性的流量转发给目标服务,核心主要在于对网络流量的处理,三大核心指标:QPS、成功率、RT 依然是反映服务核心运行状况的核心指标。
值得说明的是,在网关场景中三大指标并不能完全真实反映网关实际运行状况,三大指标异常抖动常常跟后端服务抖动相关。因此,实际观测中我们将网关分为 Downstream 指标(观测 Client 侧的指标集合)、Upstream 指标(观测上游 Service 服务维度的指标集合)、路由指标(观测路由转发规则维度的指标集合)。同时,网关作为流量入口还有一些功能性指标,如解压缩 GZip、认证鉴权 Authz 等指标。
实际应用中还会有其他网络指标如接手、发送的数据量等,限于篇幅就不进行赘述。
MSE 云原生网关在可观测体系的实践
在虚拟化时期的微服务架构下,业务通常采用流量网关 + 微服务网关两层架构,流量网关负责南北向流量调度和安全防护,微服务网关负责东西向流量调度和服务治理。而在容器和 K8s 主导的云原生时代,Ingress 成为 K8s 生态的网关标准,赋予了网关新使命,使流量网关 + 微服务网关合二为一成为可能。MSE 云原生网关正是在这种背景下诞生,其基于阿里开源 Higress[1] 构建,在能力不打折的情况下将两层网关二合一,不仅可以节省 50% 的资源部署成本,还极大降低运维及使用成本。
MSE 云原生网关[2]与阿里云应用实时监控服务 ARMS、Prometheus 监控深度集成,在网关场景下提供 Metrics、Tracing、Logging 完整可观测体系,为用户带来一站式可观测体系能力,降低可观测的使用门槛。
接下来我们简要介绍下 Metrics 指标在 MSE 云原生网关的实际应用。
MSE 云原生网关 Metrics 指标大盘介绍
基础指标
对于 CPU、Memory 等基础指标建立了独立指标大盘“资源监控”,方便一键查看网关当前的资源使用情况。
核心指标
对于核心的业务指标也构建了独立指标大盘,包括“全局看板”、“业务 TOP 榜”、“访问中心”、“灰度对比看板”。
全局看板
“全局看板”提供网关整体的指标大盘,帮忙用户从全局视角查看网关当前的运行情况。
业务TOP榜
提供网关视角的当前 Top 10 的后端服务处理请求的大盘,帮忙用户快速查看当前高吞吐的服务详情。
访问中心
提供网关当前 Downstream、Upstream、Service 与功能性的指标大盘,指标有 Downstream 的 QPS\\RT\\成功率\\连接数等,也提供 Upstream 的连接数、RT P99、RT P90 等,而且还有 GZIP 压缩、鉴权等指标。
灰度对比看板
提供使用多服务方案做灰度发布时对比查看流量情况。
细粒度服务级的指标
MSE 云原生网关也提供单个服务级的指标,例如常规的在单个服务中划分多个版本进行灰度,然后对各个版本做指标观测。
细粒度路由级的指标
在网关中路由规则代表包含某些特征的一组流量,通常运维时或者问题定位时我们也需要能够查看具体的某组路由流量情况,MSE 云原生网关也提供路由级的指标。
MSE 云原生网关告警规则介绍
Metrics 指标是用于观测应用运行态的重要手段,在指标异常时我们希望能主动发现,这就离不开告警,MSE 云原生网关集成阿里云 ARMS 后也内置了一些告警模板,内置告警模板是我们根据日常网关运维经验提炼的一些核心告警规则,例如网关的核心指标:CPU 使用率、内存使用率、请求成功率、请求 RT 等,方便用户快速配置告警,同时用户也可以根据自身需求自定义新的告警模板,这里就不再一一展开。

使用同比/环比数据发现异常
网关作为流量入口,在单一服务的异常中,异常流量造成的绝对值变化可能并不明显,此时配置同比/环比的告警是相当重要的,比如配置服务流量同比下跌,错误数同比上涨等告警,能够有效发现绝对值变化不明显,同一维度相对变化明显的异常。
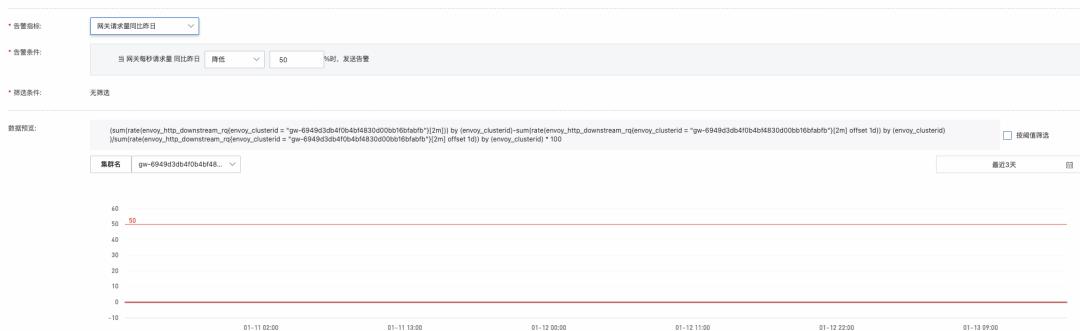
Metrics 指标在网关问题排查中的应用
问题 1:后端服务抖动导致的成功率下降
网关作为流量入口,在后端服务出现rt抖动时,网关往往是客户想到的首要排查对象,如何基于 Metrics 指标在网关场景中快速定位问题是非常重要的,如下图是基于 MSE 云原生网关提供的指标大盘来快速定位问题的大致流程。
后端服务抖动常见的原因有下面两点:
- 由于 Java gc 或者类加载导致纪录的耗时和实际有偏差。
- 后端应用内核参数配置不合理无法及时 accept 连接,导致网关纪录的服务耗时迅速增长。
问题 2:后端服务新增灰度版本后请求RT大幅增加
单服务使用不同版本进行灰度测试的场景很常见,例如下面有服务 go-httpbin,当前版本是 go-httpbin-v1,新增了 go-httpbin-v2 版本进行新功能灰度测试。
go-httpbin-v2 版本上线后用户反馈 go-httpbin 服务的请求处理时间变慢了,即请求 RT 变长了,如何通过观测指标快速查看新版本的请求情况呢?可以通过 MSE 云原生网关路由级的指标查看,如下图:
链接网关指标观测场景下,如何接入阿里云 Prometheus 监控
Prometheus 监控支持企业云监控集成和云产品自监控集成,您可以通过 Prometheus 监控提供的指标、大盘以及告警来查看这些云产品的监控数据。目前,您可以在对应的 MSE 云原生网关云产品控制台开启 Prometheus 监控,开启之后,该云产品会显示在 Prometheus 服务的云产品自监控集成页面的已集成区域,则表示该云产品已成功接入。
- 登录 Prometheus 控制台。
- 在左侧导航栏单击实例列表,进入 Prometheus 监控的实例列表页面。
- 在实例列表中单击实例名称为云服务实例的 Prometheus 实例,进入集成中心页面。
4.您可以在对应的 MSE 云原生网关云产品控制台开启 Prometheus 监控,开启之后,该云产品会显示在 Prometheus 服务的云产品自监控集成页面的已集成区域,则表示该云产品已成功接入,即可在 Prometheus 看到相关大盘。
自建 Prometheus 与阿里云 Prometheus 监控的优劣对比
Prometheus 作为目前最主流的可观测开源项目之一,已经被众多企业所广泛应用。但在实际生产过程中,还是遇到各种各样问题,其中包括:
- 由于安全、组织管理等因素,用户业务通常部署在多个相互隔离的 VPC,需要在多个 VPC 内都重复、独立部署 Prometheus,导致部署和运维成本高。
- 每套完整的自建观测系统都需要安装并配置 Prometheus、Grafana、AlertManager 等组件,部署过程复杂、实施周期长,并且每次升级都需要对每个组件进行维护。
- 随着监控规模不断扩大,资源消耗呈非线性快速增加,系统可用性无法得到保障。
- 对于云原生网关,自建 Prometheus 无法监控到,导致无法实现一站式、全局视角的监控建设。
- 开源分享的网关大盘不够专业,却少开箱即用的丰富指标,不能帮助用户更迅速的的了解网关的整体运行
针对以上问题,阿里云 Proemtheus 监控进行了以下几个方面的优化:
一、性能强化&降低资源消耗,压降 IT 运维成本
为了进一步进行性能优化,阿里云 Prometheus 监控将 Agent 部署在用户侧,保留原生采集能力同时, 尽量使用最少资源;通过采集存储分离架构,提高整体性能;采集组件优化,提升单副本采集能力,降低资源消耗;通过多副本横向扩展均衡分解采集任务,实现动态扩缩,解决开源水平扩展问题。采集/数据处理/存储组件支持多副版本,保证核心数据链路高可用;基于集群规模可直接进行弹性扩容;支持数据重传,彻底解决丢弃逻辑弊病,确保数据完整性与准确性。
同时,为了应对大规模数据、长时间区间的查询场景,通过 DAG 执行优化、算子下推,提升大规模数据查询性能并支持长时间区间秒级查询;通过 Global DataSource 和 Global View 实现对多集群统一监控与跨集群聚合查询。
在提供企业级能力强化同时,全方位降低企业使用 Prometheus 的 IT 运维成本。通过包年包月、按量付费等多种计费方式让费用支出与规划更加清晰与灵活,相较于开源版本节省 37% 以上。
二、与 MSE 云原生网关等云服务深度集成
云产品在各自控制台都提供自身产品的可观测性,但这些云产品的指标及看板散落在各控制台,且无法进行精细化的指标数据应用。Prometheus 服务提供云产品监控功能,将这些数据进行统一展现、查询、告警,为运维团队提供更加便捷的日常运维监控界面。
三、Grafana 看板增强,让云服务监控更简单
想要更好、更快速的呈现相关指标图表,阿里云 Prometheus 监控预置 Grafana 组件,预置常见云服务、应用等看板模板,如应用实时监控服务 ARMS、云监控 CMS、日志服务 SLS、阿里云 Elasticsearch 等云服务,提供各种云服务的数据源配置及预置大盘,实现各种可观测数据的统一展示。如容器、消息队列 Kafka 等,进一步提供 GrafanaPro 大盘,帮助运维进行更加精细化的指标观测。在预置看板之外,可以通过 Grafana 官方自由增加新插件,添加新的可视化模板以及数据源,进一步满足个性化运维监控需求。
总结 & 产品优惠
MSE 云原生网关默认提供了丰富的 Metrics 指标大盘,配合阿里云 Prometheus 监控提供开箱即用的完整可观测性能力,能够帮助用户快捷、高效的搭建自身的微服务网关与对应的可观测体系。后续我们会持续在产品的性能、易用性、稳定性和生态方面持续打磨,以便用户无门槛的享受到云原生技术的红利。目前,Prometheus 监控及 MSE 提供多种优惠活动:
- Prometheus 监控 包年包月中小规格首月免费
- MSE 云原生网关、注册配置中心专业版首购8折优惠,首购1年及以上7折优惠
相关链接
[1] Higress
[2] MSE 云原生网关
作者:如葑
本文为阿里云原创内容,未经允许不得转载。
以上是关于统一观测丨使用 Prometheus 监控云原生网关,我们该关注哪些指标?的主要内容,如果未能解决你的问题,请参考以下文章
统一观测丨使用 Prometheus 监控 Nginx Ingress 网关最佳实践
在微服务架构下基于 Prometheus 构建一体化监控平台的最佳实践
云原生在京东丨云原生时代下的监控:如何基于云原生进行指标采集?