SQL笔记 --- 数据库设计步骤
目录
总体设计过程
需求分析
概念结构设计
逻辑结构设计
数据库物理设计
数据库实施
数据库运行和维护
总体设计过程
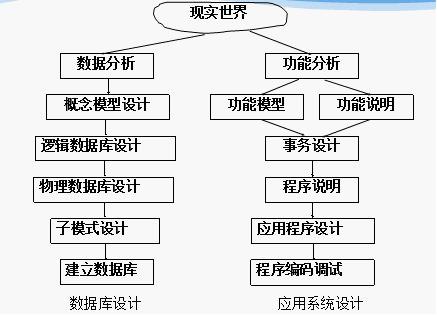
数据库设计步骤:
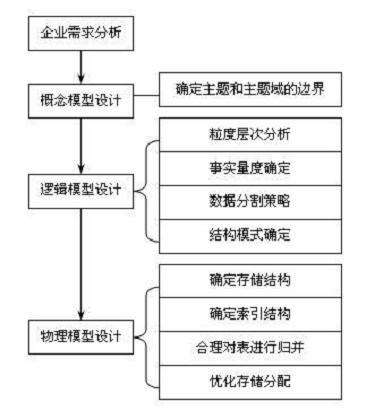
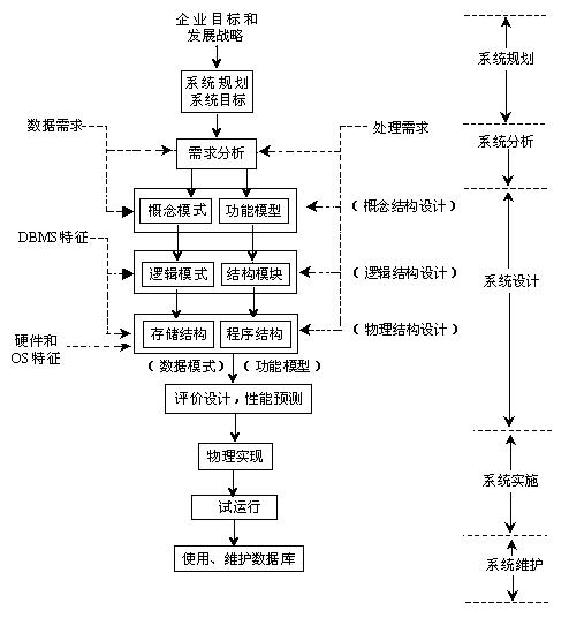
设计描述:
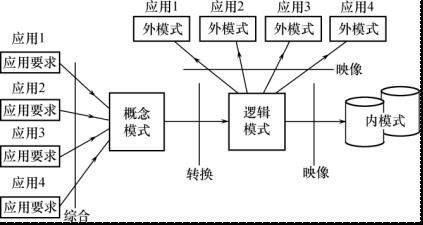
数据库设计不同阶段形成的数据库各级模式:
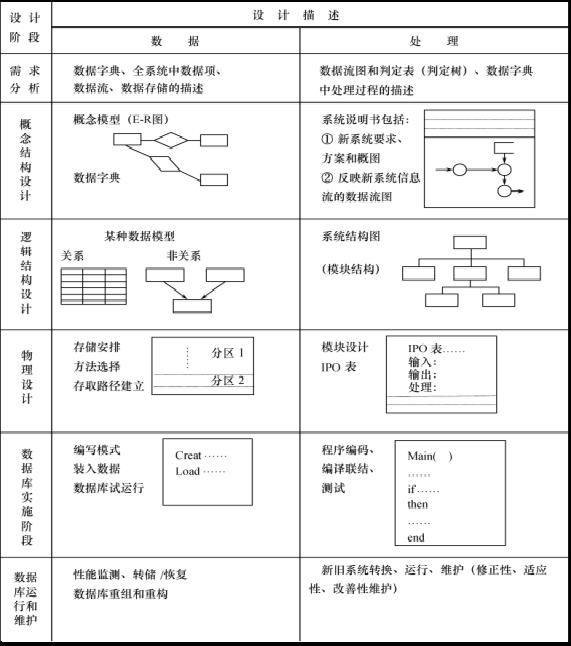
数据库设计的特点:
需求分析
分析和表达用户需求:
- 首先把任何一个系统都抽象为:
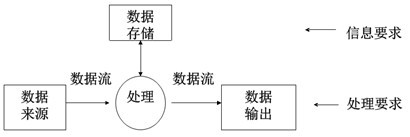
- 分解处理功能和数据:
- 分解处理功能:
- 将处理功能的具体内容分解为若干子功能
- 分解数据:
- 处理功能逐步分解同时,逐级分解所用数据,形成若干层次的数据流图
- 表达方法:
- 处理逻辑:用判定表或判定树来描述
- 数据:用数据字典来描述
- 分解处理功能:
- 将分析结果再次提交给用户,征得用户的认可
任务:
- 通过调查,收集与分析数据,获得用户对数据要求:
- 信息要求:
- 指用户需要从数据库中获得信息的内容与性质,再由信息要求导出数据要求
- 处理要求:
- 值用户要完成什么处理功能,对初一响应时间有什么要求,处理方式是批处理还是联机处理
- 安全性与完整性要求
- 信息要求:
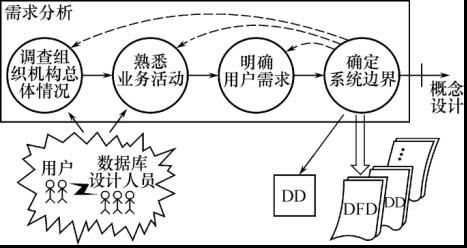
需求分析过程:
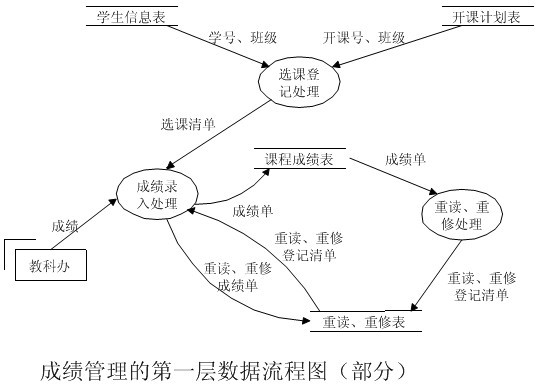
数据流图:
- 符号说明:

- 例子:
数据字典:
- 与数据流图的区别
- 数据流图 -- 表达了数据和处理的关系
- 数据字典 -- 则是系统中各类数据描述的集合
-
组成:
- 数据项:
- 形式:
-
数据项描述 ={ 数据项名, 数据项含义说明, 别名, 数据类型, 长度, 取值范围, 取值含义, 其他数据项的逻辑关系, 数据项之间的联系 }
-
- 例子:数据项,以“学号”为例:
- 数据项: 学号
- 含义说明:唯一标识每个学生
- 别名: 学生编号
- 类型: 字符型
- 长度: 8
- 取值范围:00000000至99999999
- 取值含义:前两位标别该学生所在年级, 后六位按顺序编号
- 形式:
- 数据结构:
- 形式:
- 数据结构描述 ={ 数据结构名, 含义说明, 组成: { 数据项或数据结构 } }
- 例子:数据结构,以“学生”为例学生”是该系统中的一个核心数据结构:
- 数据结构: 学生
- 含义说明: 是学籍管理子系统的主体数据结构, 定义了一个学生的有关信息
- 组成: 学号,姓名,性别,年龄,所在系,年级
- 形式:
- 数据流:
- 形式:
- 数据流描述 ={ 数据流名, 说明, 数据流来源, 数据流去向, 组成: {数据结构}, 平均流量, 高峰期流量 }
- 例子数据流,“体检结果”可如下描述:
- 数据流: 体检结果
- 说明: 学生参加体格检查的最终结果
- 数据流来源:体检
- 数据流去向:批准
- 组成: ……
- 平均流量: ……
- 高峰期流量:……
- 形式:
- 数据存储:
- 形式:
- 数据存储描述 ={ 数据存储名, 说明, 编号, 输入的数据流, 输出的数据流, 组成: {数据结构}, 数据量, 存取频度, 存取方式 }
- 例子:数据存储,“学生登记表”可如下描述:
- 数据存储: 学生登记表
- 说明:记录学生的基本情况
- 流入数据流:……
- 流出数据流:……
- 组成: ……
- 数据量: 每年3000张
- 存取方式: 随机存取
- 形式:
- 处理过程:
- 形式:
- 处理过程描述 ={ 处理过程名, 说明, 输入:{ 数据流 }, 输出: {数据流}, 处理: { 处理过程 }}
- 例子:处理过程“分配宿舍”可如下描述:
- 处理过程:分配宿舍
- 说明: 为所有新生分配学生宿舍
- 输入: 学生,宿舍
- 输出: 宿舍安排
- 处理: 在新生报到后,为所有新生分配学生宿舍. 要求同一间宿舍只能安排同一性别的学生, 同一个学生只能安排在一个宿舍中. 每个学生的居住面积不小于3平方米. 安排新生宿舍其处理时间应不超过15分钟
- 形式:
概念结构设计
特点:
- 能真实、充分地反映现实世界
- 易于理解
- 易于更改
- 易于向关系、网状、层次等各种数据模型转换
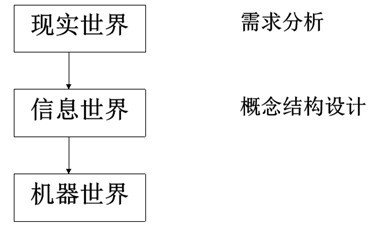
四类方法:
- 自顶向下:
- 定义:
- 即首先定义全局概念结构的框架,然后逐步细化
- 图解:
- 定义:
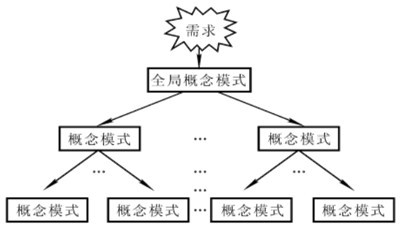
- 自底向上:
- 定义:
- 即首先定义个局部应用的概念结构,然后将他们集合起来,得到全局概念
- 步骤:
- 第1步:抽象数据并设计局部视图
- 第2步:集成局部视图,得到全局概念结构
- 图解:
- 定义:
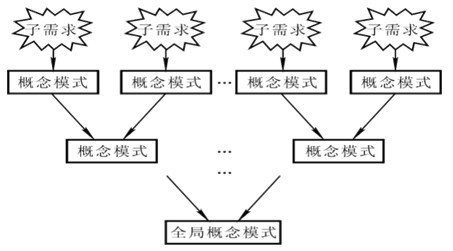
- 逐步扩展:
- 定义:
- 首先定义最重要的核心概念结构,然后向外扩充,以滚球的方法逐步生成其他概念结构,直至总体概念结构
- 图解:
- 定义:
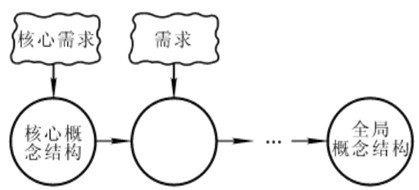
- 混合策略:
- 定义:
- 即将自顶向下和自底向上相结合,用自顶向下策略设计一个全局概念结构框架,以它为骨架集成由底向上策略中设计的个局部概念结构
- 图解:
- 定义:
三种常用抽象:
- 分类(Classification):
- 定义某一类概念作为现实世界中一组对象的类型
- 抽象了对象值和型之间的“is member of”的语义
- 图例:
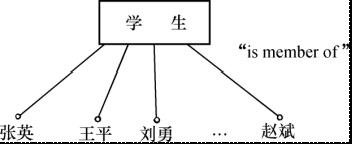
- 聚集(Aggregation):
- 定义某一类型的组成成分
- 抽象了对象内部类型和成分之间“is part of”的语义
- 复杂的聚集,某一类型的成分仍是一个聚集
- 图例:
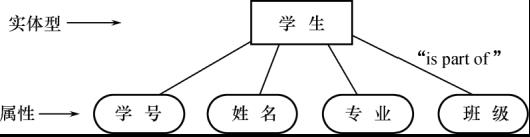
- 概括(Generalization):
- 定义类型之间的一种子集联系
- 抽象了类型之间的“is subset of”的语义
- 继承性:
E-R图:
- 任务:
- 将各局部应用涉及的数据分别从数据字典中抽取出来
- 参照数据流图,标定各局部应用中的实体、实体的属性、标识实体的码
- 确定实体之间的联系及其类型(1:1,1:n,m:n)
- 两条准则:
- 属性不能再具有需要描述的性质.即属性必须是不可分的数据项,不能再由另一些属性组成
- 属性不能与其他实体具有联系.联系只发生在实体之间
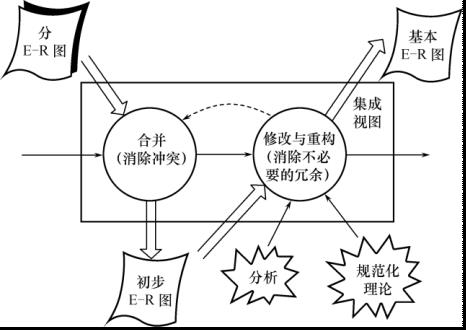
视图集成:
- 分类:
- 一次集成 一次集成多个分E-R图
- 通常用于局部视图比较简单时
- 逐步集成:
- 用累加的方式一次集成两个分E-R图
- 图解:
- 冲突:
- 两类属性冲突:
- 属性域冲突:
- 属性值的类型
- 取值范围
- 取值集合不同
- 属性取值单位冲突
- 属性域冲突:
- 两类命名:
- 冲突 同名异义: 不同意义的对象在不同的局部应用中具有相同的名字
- 异名同义(一义多名): 同一意义的对象在不同的局部应用中具有不同的名字
- 三类结构冲突:
- 同一对象在不同应用中具有不同的抽象
- 同一实体在不同分E-R图中所包含的属性个数和属性排列次序不完全相同
- 实体之间的联系在不同局部视图中呈现不同的类型
- 两类属性冲突:
- 基本任务:
- 消除不必要的冗余,设计生成基本E-R图
- 步骤:
- 合并分E-R图,生成初步E-R图:
- 消除冲突
- 属性冲突
- 命名冲突
- 结构冲突
- 修改与重构:
- 消除不必要的冗余,设计生成基本E-R图
- 分析方法
- 规范化理论
- 合并分E-R图,生成初步E-R图:
验证概念结构:
- 整体概念结构内部必须具有一致性,不存在互相矛盾的表达
- 整体概念结构能准确地反映原来的每个视图结构,包括属性、实体及实体间的联系
- 整体概念结构能满足需要分析阶段所确定的所有要求
逻辑结构设计
E-R图与关系模型转换:
- 转换内容:
- 将实体、实体的属性和实体之间的联系转换为关系模式
- 转换原则:
- 一个实体转换为一个关系模式
- 实体的属性即为关系的属性
- 实体的码即为关系的码
E-R图实体型间的联系有以下不同情况:
- 一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并:
- 转换为一个独立的关系模式
- 与某一端实体对应的关系模式合并
- 一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并:
- 转换为一个独立的关系模式
- 与n端对应的关系模式合并
- 一个m:n联系转换为一个关系模式
- 三个或三个以上实体间的一个多元联系转换为一个关系模式
- 具有相同码的关系模式可合并:
- 目的:减少系统中的关系个数
- 合并方法: 将其中一个关系模式的全部属性加入到另一个关系模式中,然后去掉其中的同义属性(可能同名也可能不同名),并适当调整属性的次序
优化数据模型方法:
- 确定数据依赖
- 对于各个关系模式之间的数据依赖进行极小化处理,消除冗余的联系.
- 确定各关系模式分别属于第几范式.
- 分析对于应用环境这些模式是否合适,确定是否要对它们进行合并或分解.
- 对关系模式进行必要的分解或合并
设计用户子模式:
- 使用更符合用户习惯的别名
- 针对不同级别的用户定义不同的外模式,以满足系统对安全性的要求.
- 简化用户对系统的使用
任务:
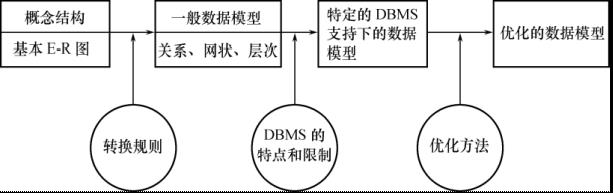
- 将概念结构转化为具体的数据模型
- 逻辑结构设计的步骤
- 将概念结构转化为一般的关系、网状、层次模型
- 将转化来的关系、网状、层次模型向特定DBMS支持下的数据模型转换
- 对数据模型进行优化
- 设计用户子模式
逻辑结构设计时3个步骤:
数据库物理设计
步骤:
- 确定数据库的物理结构,在关系数据库中主要指存取方法和存储结构
- 对物理结构进行评价,评价的重点是时间和空间效率
索引存取:
- 选择索引存取方法的一般规则:
- 如果一个(一组)属性经常在查询条件中出现,则考虑在这个(这组)属性上建立索引(组合索引)
- 如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引
- 如果一个(或一组)属性经常在连接操作的连接条件中出现,则考虑在这个(或这组)属性上建立索引
- 关系上定义的索引数过多会带来较多的额外开销:
- 维护索引的开销
- 查找索引的开销
聚簇:
- 用途:
- 大大提高按聚簇码进行查询的效率
- 节省存储空间
- 局限性:
- 聚簇只能提高某些特定应用的性能
- 建立与维护聚簇的开销相当大
- 适用范围:
- 既适用于单个关系独立聚簇,也适用于多个关系组合聚簇
- 当通过聚簇码进行访问或连接是该关系的主要应用,与聚簇码无关的其他访问很少或者是次要的时,可以使用聚簇
数据库实施
数据装载方法:
- 人工方法
- 计算机辅助数据入库
主要工作:
- 功能测试:实际运行数据库应用程序,执行对数据库的各种操作,测试应用程序的功能是否满足设计要求,如果不满足,对应用程序部分则要修改、调整,直到达到设计要求
- 性能测试:测量系统的性能指标,分析是否达到设计目标,如果测试的结果与设计目标不符,则要返回物理设计阶段,重新调整物理结构,修改系统参数,某些情况下甚至要返回逻辑设计阶段,修改逻辑结构
强调两点:
- 分期分批组织数据入库
- 重新设计物理结构甚至逻辑结构,会导致数据重新入库.
- 先输入小批量数据供调试用:
- 待试运行基本合格后再大批量输入数据
- 逐步增加数据量,逐步完成运行评价
- 由于数据入库工作量实在太大,费时、费力,所以应分期分批地组织数据入库
- 数据库的转储和恢复
- 在数据库试运行阶段,系统还不稳定,硬、软件故障随时都可能发生
- 系统的操作人员对新系统还不熟悉,误操作也不可避免
- 因此必须做好数据库的转储和恢复工作,尽量减少对数据库的破坏
数据库运行和维护
DBA维护数据库工作:
- 数据库的转储和恢复
- 数据库的安全性、完整性控制
- 数据库性能的监督、分析和改进
- 数据库的重组织和重构造
重组织:
- 形式:
- 全部重组织
- 部分重组织(只对频繁增、删的表进行重组织)
- 目标:
- 提高系统性能
- 工作:
- 按原设计要求:
- 重新安排存储位置
- 回收垃圾
- 减少指针链
- 数据库的重组织不会改变原设计的数据逻辑结构和物理结构
- 按原设计要求:
重构造:
- 根据新环境调整数据库的模式和内模式:
- 增加新的数据项
- 改变数据项的类型
- 改变数据库的容量
- 增加或删除索引
- 修改完整性约束条件
以上是关于SQL笔记 --- 数据库设计步骤(转)的主要内容,如果未能解决你的问题,请参考以下文章