mitmproxy 抓包神器-3.抓取网站数据或图片
Posted 上海-悠悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mitmproxy 抓包神器-3.抓取网站数据或图片相关的知识,希望对你有一定的参考价值。
前言
Mitmproxy是一个免费的开源交互式的HTTPS代理。MITM即中间人攻击(Man-in-the-Middle Attack)。
mitmproxy 工具有以下三个组件构成
- mitmproxy 是具有 SSL/TLS 功能的交互式拦截侦听代理,具有用于HTTP/1,HTTP/2和WebSockets的控制台界面。
- mitmweb 是用于 mitmproxy 的基于 Web 的界面, 提供一个可视化界面帮助我们查看抓取的请求,可以修改返回内容。
- mitmdump 它是mitmproxy的命令行接口,利用它我们可以对接Python脚本,用Python实现监听后的处理。
Addons 插件开发
Mitmproxy 的插件机制是 mitmproxy 的一个非常强大的部分。事实上,mitmproxy自己的大部分功能都是在一套内置插件中定义的,实现了从 anticaching 和sticky cookies 到我们的登录Web应用程序的所有功能。
插件通过响应事件与 mitmproxy 进行交互,这允许它们勾入并改变 mitmprox的行为。它们通过选项进行配置,这些选项可以在mitmproxy的配置文件中设置,用户可以交互更改,也可以通过命令行传递。最后,它们可以公开命令,这允许用户直接或通过将它们绑定到交互工具中的键来调用它们的操作。
一个简单的Addons 插件示例
"""
Basic skeleton of a mitmproxy addon.
Run as follows: mitmproxy -s anatomy.py
"""
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [Counter()]
上面是一个简单的插件,它跟踪我们看到的流(或者更具体地说HTTP请求)的数量。
每当它看到一个新的流时,它都会使用mitmproxy的内部日志机制来宣布其计数。输出可以在交互工具的事件日志中找到,也可以在mitmdump的控制台上找到。
让它旋转一下,并通过将其加载到您选择的mitmproxy工具中,确保它完成了它应该做的事情。
我们将在示例中使用mitmdump 命令运行插件
mitmdump -s ./anatomy.py
以下是关于上述代码的一些注意事项:
- Mitmproxy获取插件全局列表的内容,并将其找到的内容加载到插件机制中。
- 插件只是对象——在本例中,我们的插件是Counter的一个实例。
- request 方法是一个事件的示例。插件只需为它们要处理的每个事件实现一个方法。API文档中记录了每个事件及其签名。
- 最后,ctx模块是一个 holdall 模块,它公开了一组常用于插件的标准对象。
我们可以将一个ctx对象作为每个事件的第一个参数传递,但我们发现将它作为一个可导入的全局对象公开更方便。在本例中,我们使用ctx.log对象进行日志记录。
有时,我们希望编写一个快速脚本,而不必经历创建类的麻烦。
插件机制有一个简写,允许将模块作为一个整体处理为插件对象。
这使我们可以将事件处理程序函数放置在模块范围中。例如,这里有一个完整的脚本,它为每个请求添加一个头:
"""An addon using the abbreviated scripting syntax."""
def request(flow):
flow.request.headers["myheader"] = "value"
抓取浏览器上的请求简单示例
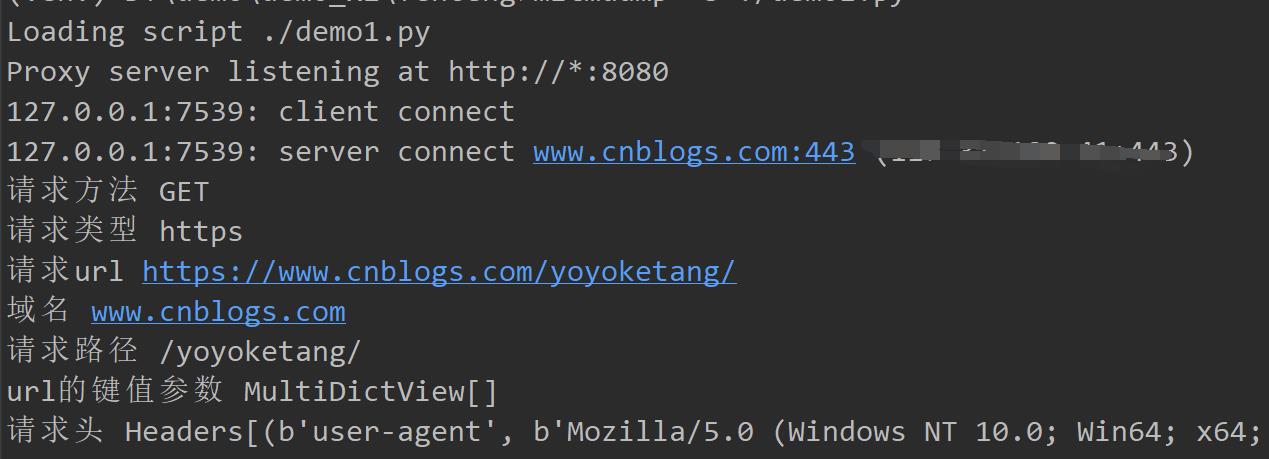
目标是抓取浏览器上的访问页面的请求,比如访问https://www.cnblogs.com/yoyoketang/ 我的博客地址,通过插件抓取请求
demo1.py 代码如下:
from mitmproxy import http
# 作者:上海-悠悠 微信号:283340479
def request(flow: http.HTTPFlow):
# 对url 过滤,仅抓取我的博客地址
if "https://www.cnblogs.com/yoyoketang/" == flow.request.url:
print('请求方法', flow.request.method)
print('请求类型', flow.request.scheme)
print('请求url', flow.request.url)
print('域名', flow.request.host)
print('请求路径', flow.request.path)
# 返回MultiDictView类型的数据,URL的键值参数
print('url的键值参数', flow.request.query)
print('请求头', flow.request.headers)
print('cookies', flow.request.cookies)
启动服务
>mitmdump -s ./demo1.py
Loading script ./demo1.py
Proxy server listening at http://*:8080
默认监听端口8080
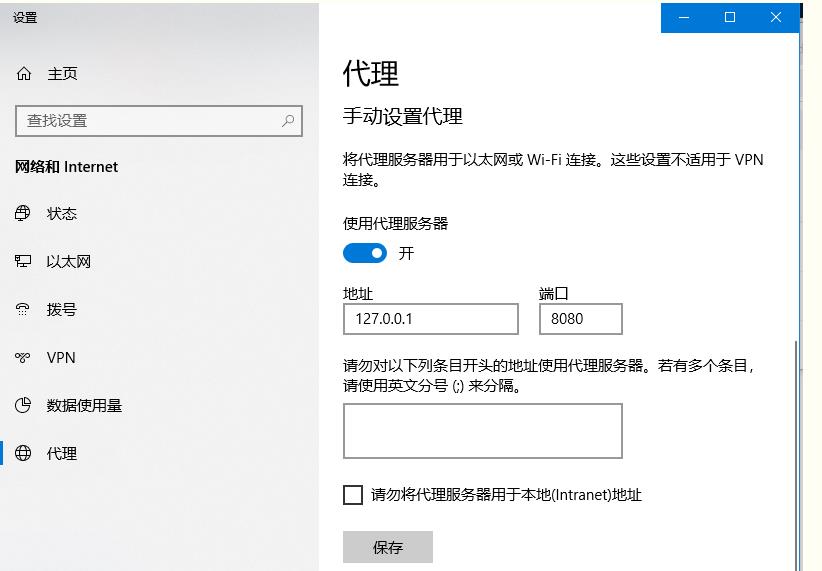
设置本机代理
浏览器上访问我的博客,就可以看到抓取请求了
爬取数据
爬取数据用到response 方法
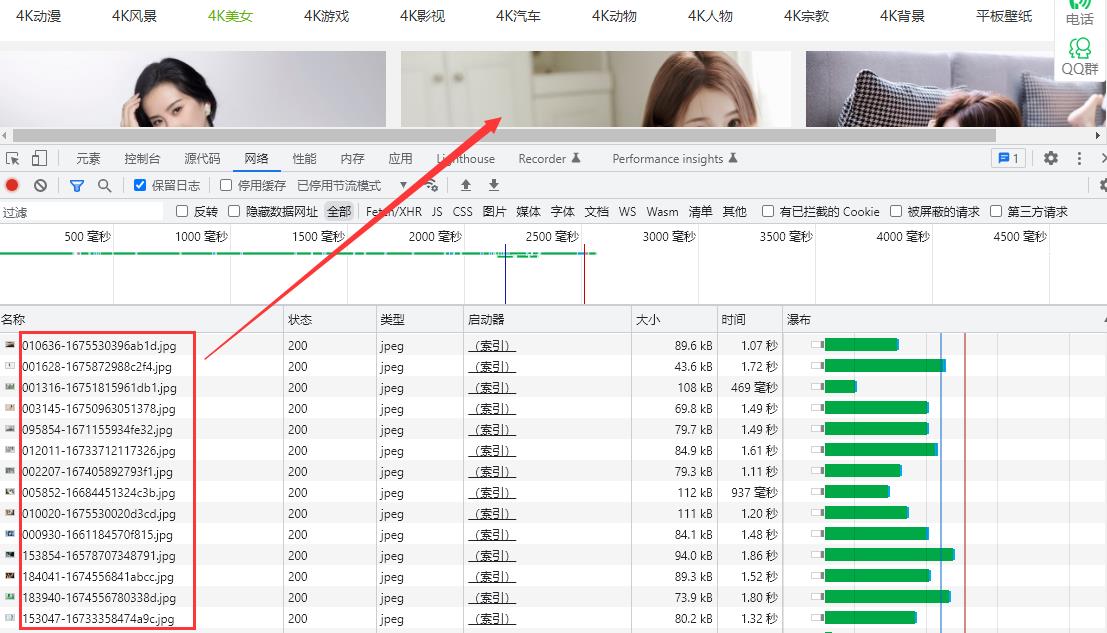
目标:收集网站打开时,加载的jpg图片,如下打开网站后,加载出来的图片
from mitmproxy import http
# 作者:上海-悠悠 微信号:283340479
def response(flow: http.HTTPFlow):
print('===========下载==============')
if "pic.netbian.com" == flow.request.host:
if flow.request.url.endswith('jpg'):
with open(flow.request.url[-18:].replace('/', ''), 'wb') as f:
f.write(flow.response.get_content())
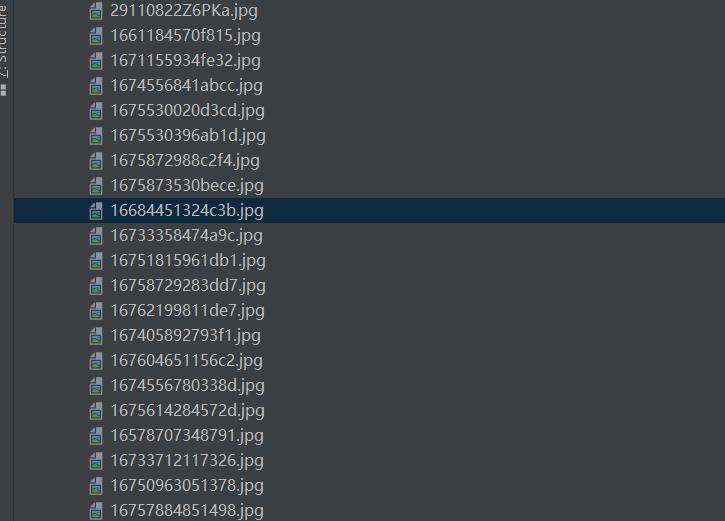
运行后收集到网页上加载的图片
除了爬取图片,也可以爬取页面上的其它数据。
如果想自动控制页面操作,可以结合selenium等前端自动化的工具。Mitmproxy 起到抓取网络请求的request 和 response 对象。
以上是关于mitmproxy 抓包神器-3.抓取网站数据或图片的主要内容,如果未能解决你的问题,请参考以下文章