hadoop伪分布式集群搭建与安装(ubuntu系统)
Posted --->别先生<---
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop伪分布式集群搭建与安装(ubuntu系统)相关的知识,希望对你有一定的参考价值。
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip;
2:使用Xsheel软件远程链接自己的虚拟机,方便操作。输入自己ubuntu操作系统的账号密码之后就链接成功了;
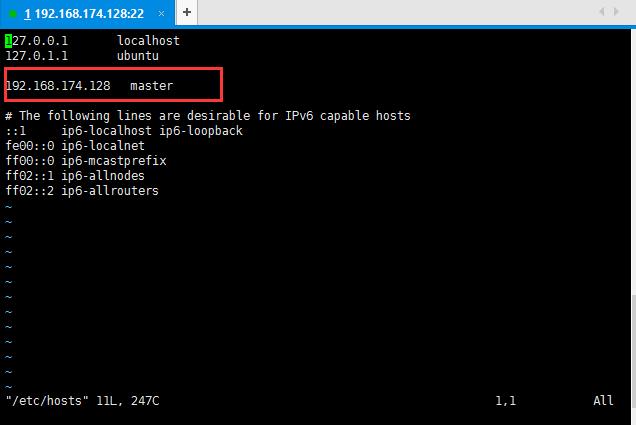
3:修改主机的名称vi /etc/hostname和域名和主机映射对应的关系 vi /etc/hosts,改过之后即生效,自己可以ping一下,我这里ip对应master,比如ping master之后发现可以ping通即可;
(centos操作系统修改主机名命令:vi /etc/sysconfig/network,修改内容为HOSTNAME=master)

4:修改过主机名称和主机名与ip对应的关系之后;开始上传jdk,使用filezilla这个工具将jdk文件以及其他文件上传到ubuntu操作系统中;
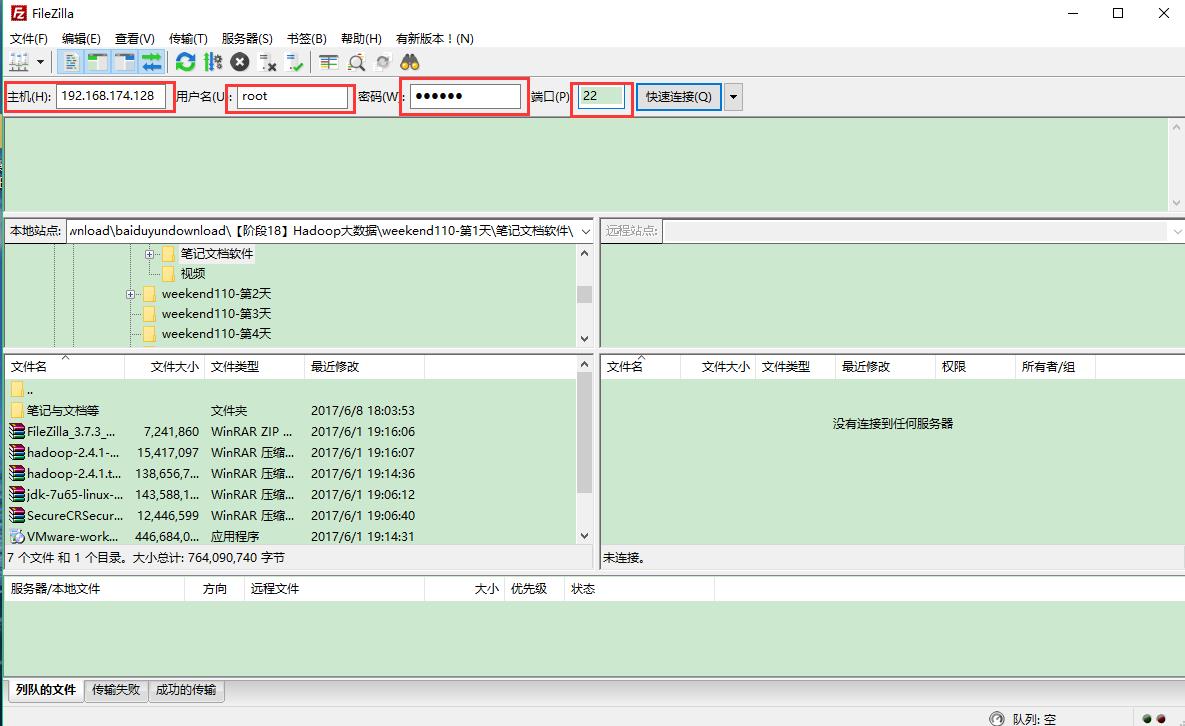
鼠标左击选中想要上传的文件拖到右边即可,如下所示:
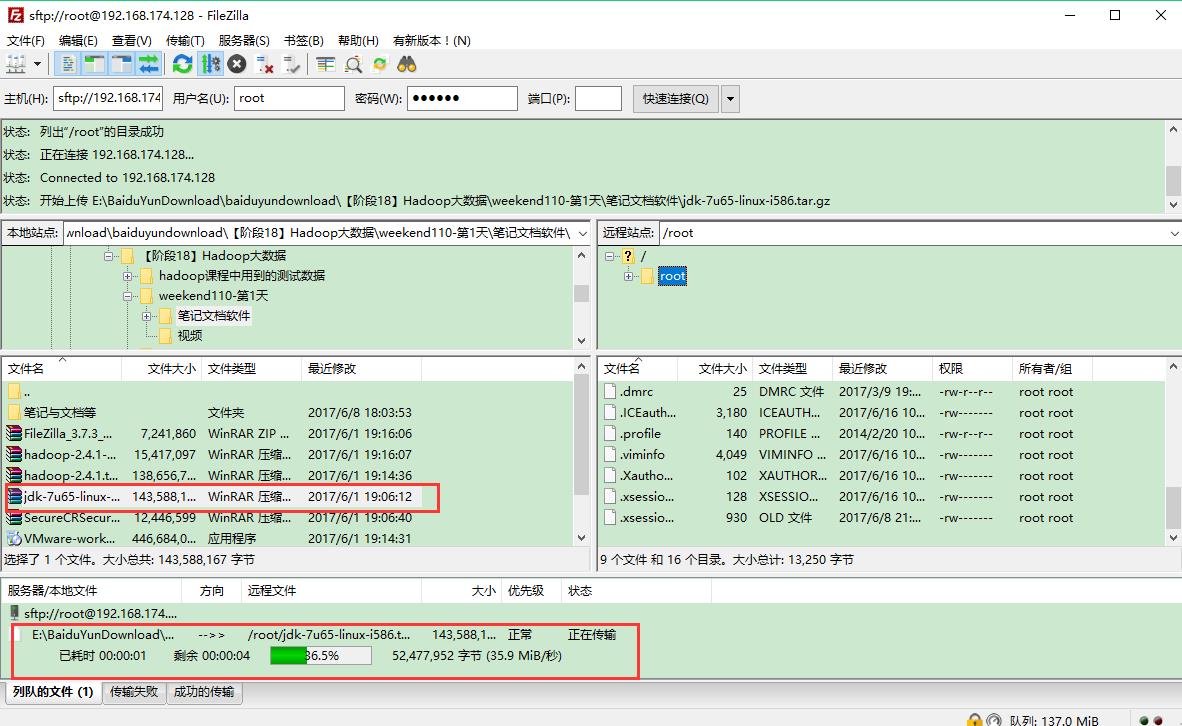
上传成功之后可以检查一下,这里默认上传到root目录下面;显示已经上传成功即可;

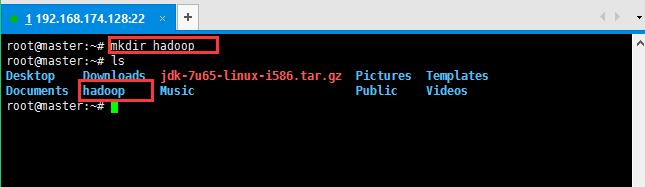
5:上传之后创建一个文件夹用于存放上传的文件或者压缩包;
记住-C是大写,小写的-c会报错,见下面的测试结果;


解压缩之后可以进到自己创建的hadoop目录下面看看效果,确定已经解压缩了;
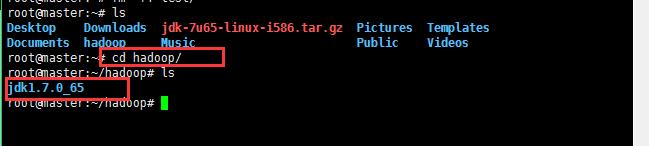
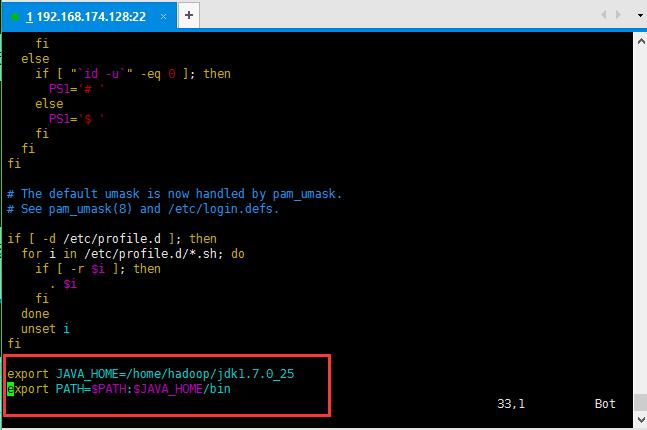
6:解压缩jdk之后开始将java添加到环境变量中(ubuntu操作系统中配置jdk的环境变量):

进去之后按shift+g到最后面,到最前面双击g,点击a/s/i这三个任意一个字母进入命令行模式,可以对配置文件进行修改;
配置的方式有很多种,这只是其中一种。
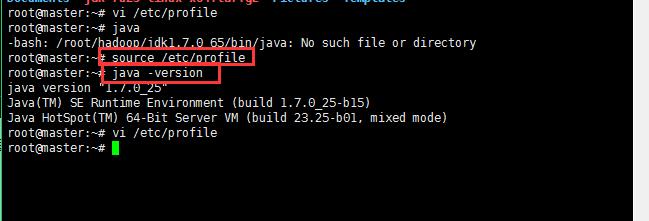
配置好jdk之后可以测试一下是否配置成功,如下图,如果没有使用source /etc/profile刷新配置是无法测试成功的;
使用source /etc/profile刷新配置之后查看java的版本即可以查看出来;
这里出了一点小插曲,我的linux版本的jdk第一次好像不能用,报了错,以为没配置好呢,后来才发现是jdk错了,所以这里都小心点;
7:开始上传hadoop和解压缩hadoop;上传和上传jdk一样的做法,这里不做多叙述;


查看hadoop的目录:hadoop-2.4.1/share/hadoop里面是核心jar包;

8:解压缩之后开始配置hadoop,找到如下所示的路径;
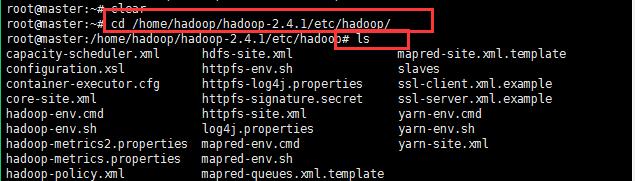
修改如下几个配置文件;详细修改见如下配置所示:
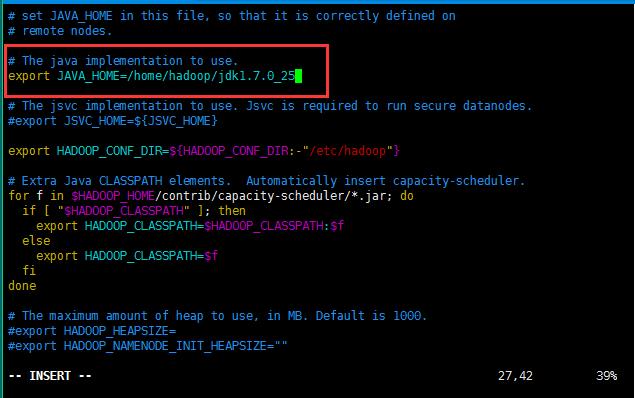
修改的第一个配置文件,hadoop-env.sh;

修改的内容如下所示:主要修改就是jdk的JAVA_HOME;如果忘记自己jdk的目录可以执行命令echo $JAVA_HOME复制一下结果即可;
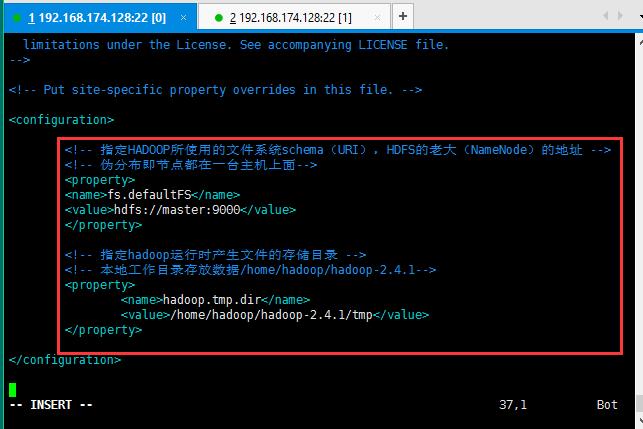
修改第二个配置文件:core-site.xml;

修改的内容如下所示:因为是伪分布式,所以节点配置直接配置主机名了;
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/tmp</value>
</property>
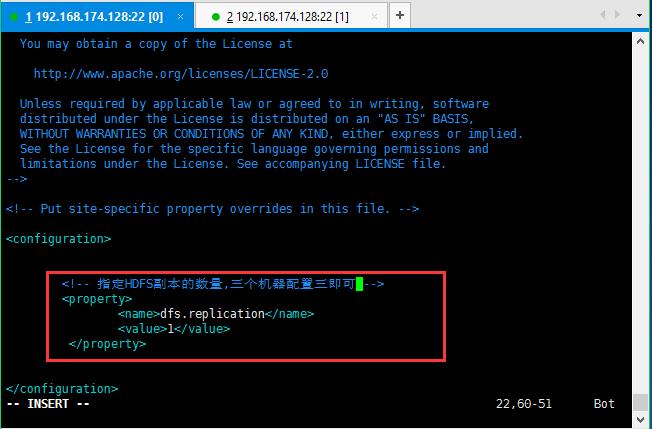
修改第三个配置文件:hdfs-site.xml

修改的内容如下所示:
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
修改第四个配置文件:首先将mapred-site.xml.template修改为mapred.site.xml,然后就将开始修改配置文件;

修改内容如下所示:
1 <!-- 指定mr运行在yarn上 --> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property>
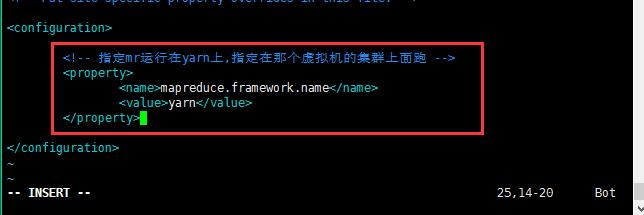
修改第五个配置文件:yarn-site.xml;

修改的内容如下所示:至此配置基本结束;
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
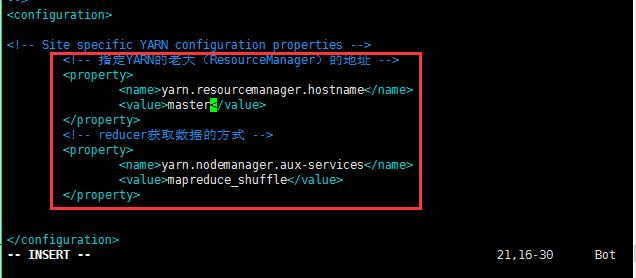
修改第六个配置文件:vi slaves

修改的内容即是自己的主机名称:

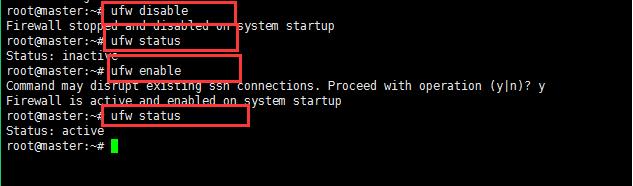
9:查看一下ubuntu下面的防火墙的状态和关闭开启防火墙:
下图所示分别是关闭防火墙,查看防火墙的状态,开始防火墙和查看防火墙的状态;
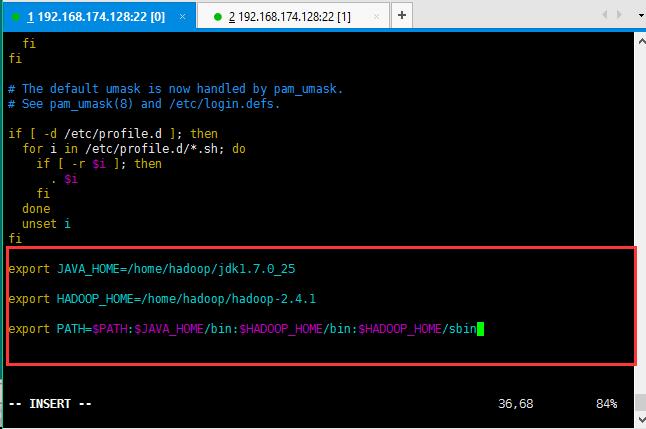
10:为了执行hadoop命令方便,同样配置一下hadoop的环境变量;同样vi /etc/profile ,配置如下所示:
配置保存之后记得source /etc/profile刷新配置;
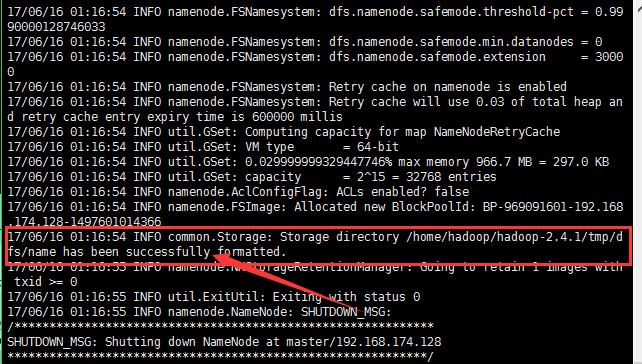
11:格式化namenode(是对namenode进行初始化)

执行格式化命令后看到successfully表示格式化成功;
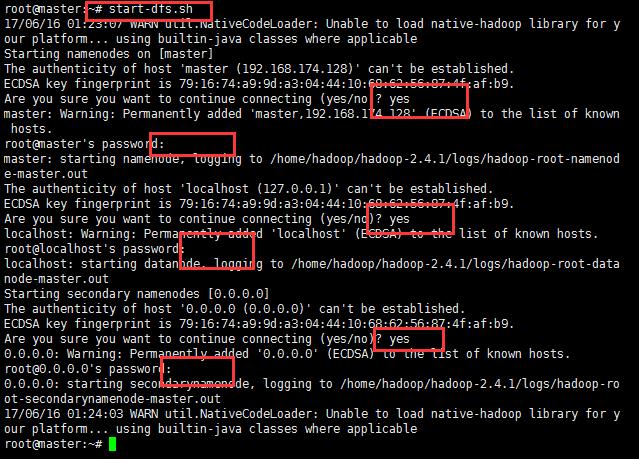
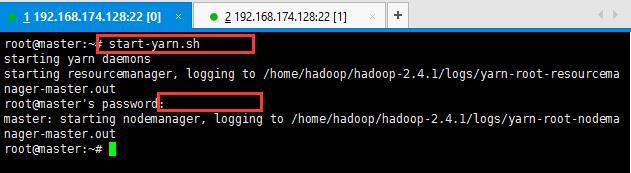
12:启动hadoop,先启动HDFS,sbin/start-dfs.sh;再启动YARN,sbin/start-yarn.sh;
启动过程中输出大概三次yes和密码;输入即可;
13:验证是否启动成功,使用jps命令验证;查看有几个进程;分别是启动start-dfs.sh和start-yarn.sh的效果;


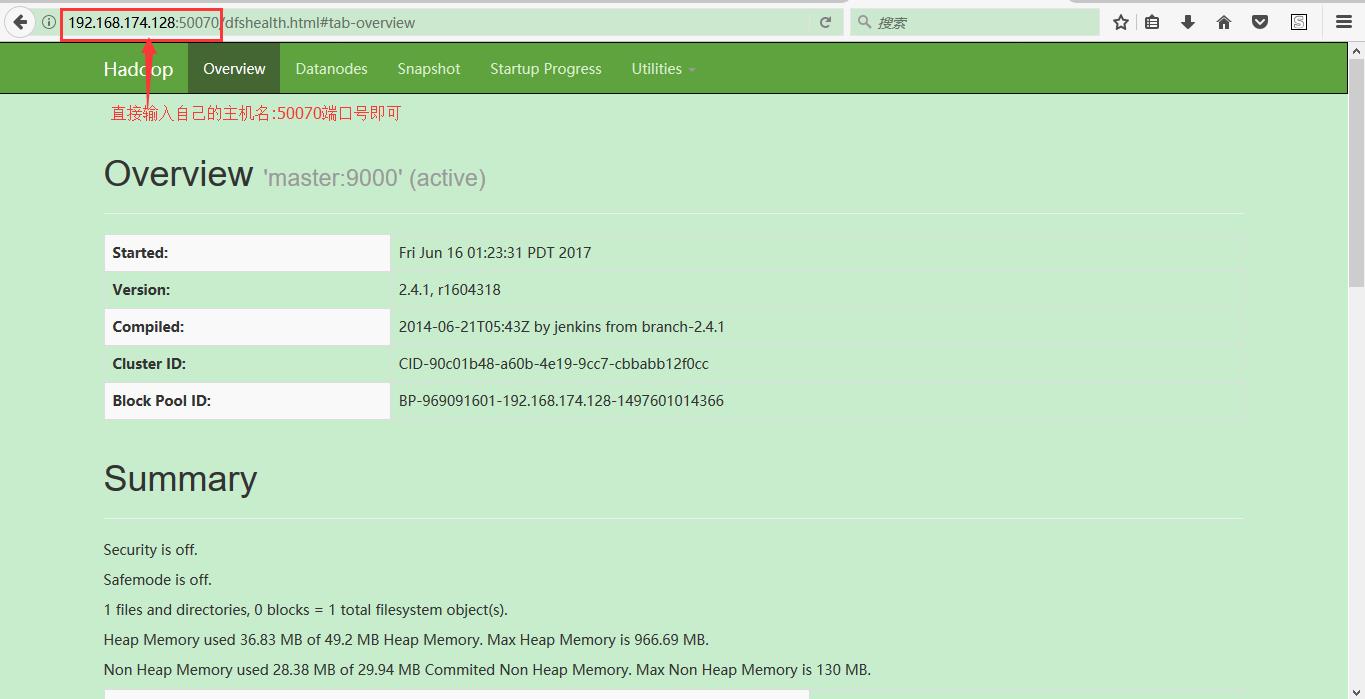
14:搭建好伪分布式集群之后可以在window访问集群的web服务;
注意:如果在window浏览器无法访问的时候(jps正常启动),这个时候估计是linux操作系统的防火墙的问题:
service iptables stop : 关闭防火墙
service iptables status : 查看防火墙的状态
service iptables start : 开启防火墙
15:简单测试一下,将一个文件上传到hdfs上面,如下所示:

假如你这样书写hadoop fs -put jdk-7u65-linux-i586.tar.gz hdfs://master:9000这个9000后面没有这个/那么你在浏览器是看不到任何文件的;

去web服务查看效果如下所示:就是刚刚上传的文件;

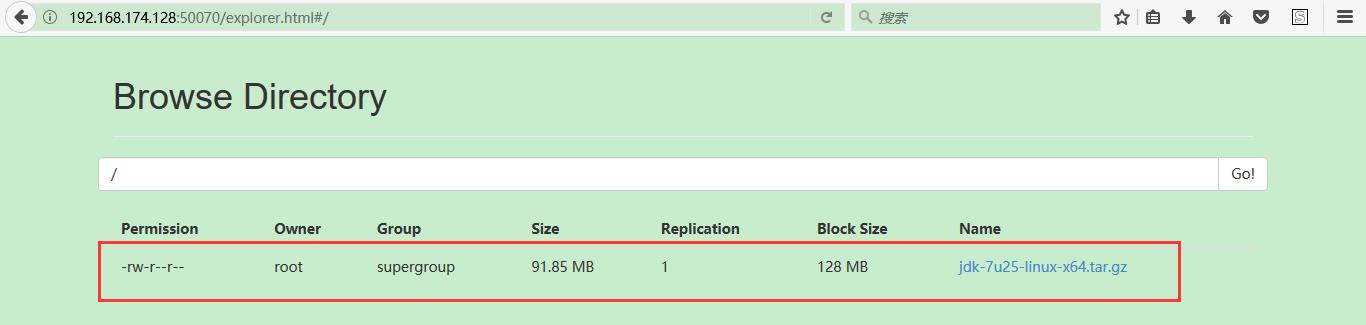
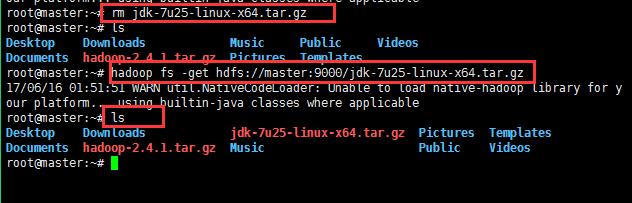
16:将文件从hdfs分布式集群中下载下来:
效果如下所示:
17:使用hadoop自带的mapreduce程序来测试mapreduce的效果:
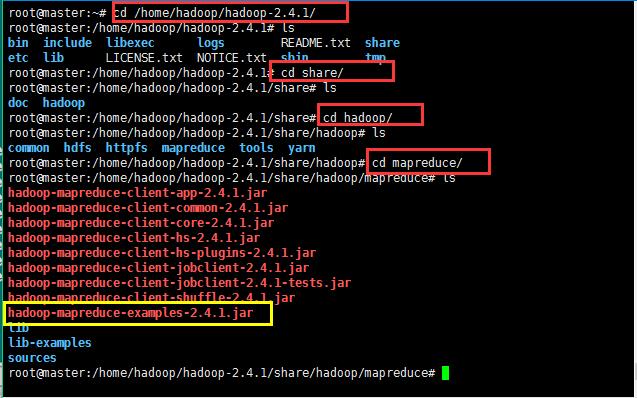
计算圆周率的程序;

简单使用一下mapreduce,以计算单词的个数为例;
创建一个count.txt用于测试里面的单词重复的次数:


因为数据是在集群上面跑的,所以文件要放到集群上面;
首先需要创建一个文件夹,用于存放文件;
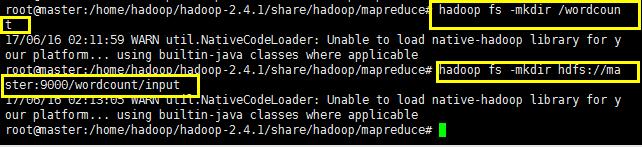
创建好的文件夹可以在web服务器里面查看,如下所示:
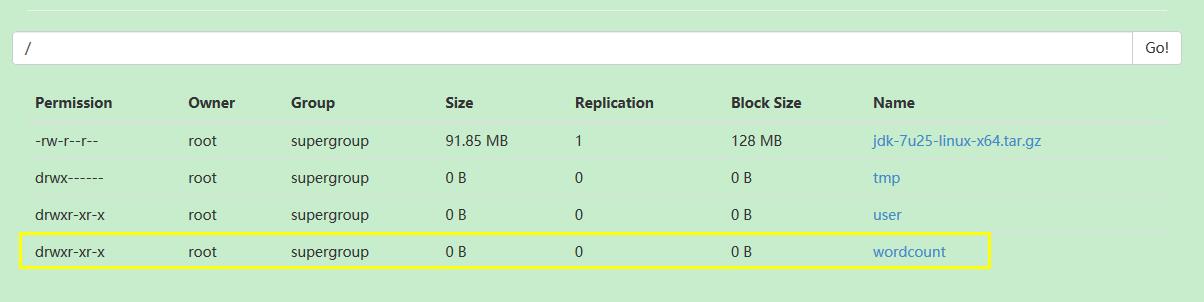
将新建的count.txt文件放到input文件夹里面,如下所示:

开始使用mapreduce的自带案例进行单词重读测试:

可以查询执行之后出现的结果:也可以直接去web服务器查看执行的结果;
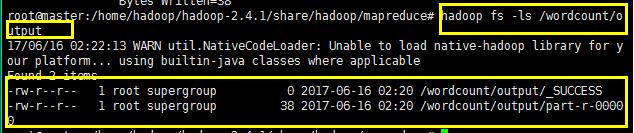
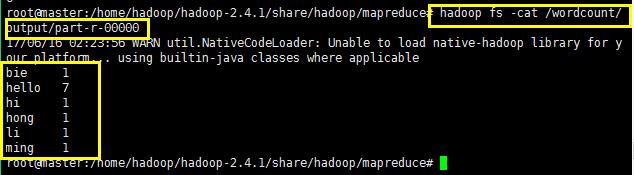
可以使用命令查看执行的结果,如下所示:
HDFS的大体实现的思想:
1:hdfs是通过分布式集群来存储文件,为客户端提供了一个便捷的访问方式,就是一个虚拟的目录结构
2:文件存储到hdfs集群中去的时候是被切分成block块的
3:文件的block存放在若干台datanode节点上的
4:hdfs文件系统中的文件于真实的block之间有映射关系,由namenode管理
5:每一个block在集群中会存储多个副本,好处是可以提高数据的可靠性,还可以提供访问的吞吐量;
18:hdfs常使用的命令:
1 hadoop fs 显示hadoop 的fs的功能 2 hadoop fs -ls / 列举某目录下面的文件夹 3 hadoop fs -lsr 列举某目录下面的文件夹及其文件夹里面的文件 4 hadoop fs -mkdir /user/hadoop 在user文件夹下面创建一个hadoop文件夹 5 hadoop fs -put a.txt /user/hadoop/ 将a.txt文件上传到user文件夹下面的hadoop文件夹下面 6 hadoop fs -get /user/hadoop/a.txt / 获取到user文件夹下面的hadoop文件夹下面的a.txt文件 7 hadoop fs -cp /原路径 /目标路径 拷贝文件,从原路径拷贝到目标路径 8 hadoop fs -mv /原路径 /目标路径 从原路径移动到目标路径 9 hadoop fs -cat /user/hadoop/a.txt 查看a.txt文件里面的内容 10 hadoop fs -rm /user/hadoop/a.txt 删除user文件夹下面的hadoop文件夹下面的a.txt文件 11 hadoop fs -rm -r /user/hadoop/a.txt 递归删除,文件夹和文件 12 hadoop fs -copyFromLocal /本地路径 /目的路径 与hadoop fs -put功能类似。 13 hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。 14 hadoop fs -chown 用户名:用户组名 /文件名 修改所属的用户和用户组,权限修改 15 hadoop fs -chmod 777 /文件名 文件的权限可读可写可执行的的权限修改 16 hadoop fs -df -h / 查看根目录下面的磁盘空间,可用和未用等等 17 hadoop fs -du -s -h / 查看某文件的大小 18 hadoop fs -du -s -h hdfs://主机名:9000/* 查看根目录下面的所有文件的大小
未完待续.......
19:免密钥登陆的配置(配置公钥和私钥):如果是伪分布式集群的搭建,那么我这里为了测试克隆了一台ubuntu,如果是分布式集群搭建,那么是三个ubuntu操作系统。所以这里简单演示如何配置免密钥登陆;
(1):master请求登陆slaver1;
(2):查看授权列表;
(3):用master的公钥加密一个随机字符串发送给master;
(4):master用自己的私钥解密slaver1过来的密文;
(5):将解密结果发送给slaver1;
(6):slaver1验证解密结果;
(7):通过master验证;
首先使用vi /etc/hostname(centOs操作系统vim /etc/sysconfig/network)将克隆的主机名修改一下:


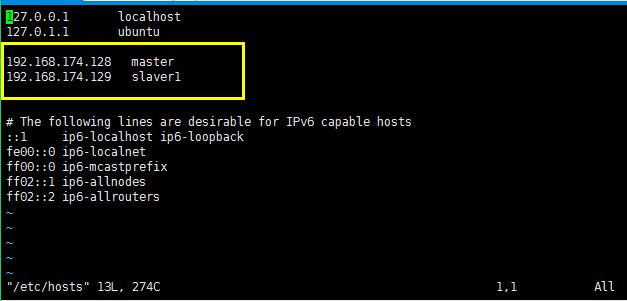
接着将vi /etc/hosts里面的域名和主机对应起来,这样就可以进行密码登陆:
两个ubuntu操作的hosts的配置都是如下图所示的:
修改完之后开始配置密钥,使用命令生成密钥:在master上使用ssh-keygen -t rsa命令之后一直回车即可;注意第一个enter键看一下自己的密钥对保存的路径:我的是/root/.ssh/id_rsa
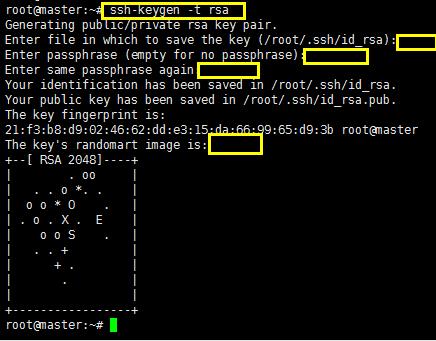
生成密钥之后找到密钥所在的路径,如下所示:

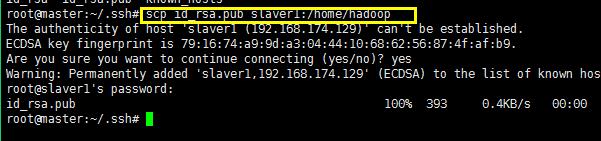
将密钥rsa.pub拷贝到slaver1的home目录下面的hadoop目录下面:(scp,ssh copy的缩写,远程拷贝文件或者目录)
或者ssh-copy-id 主机名称;这样操作直接将公钥拷贝到目的主机的authorized_keys中;
创建一个authorized_keys(touch authorized_keys创建这个文件)文件并且将权限修改为600之后将密钥添加到这个文件中:使用cat命令将密钥进行追加操作,由于我将master的密钥拷贝到/home/hadoop下面,所以注意路径:
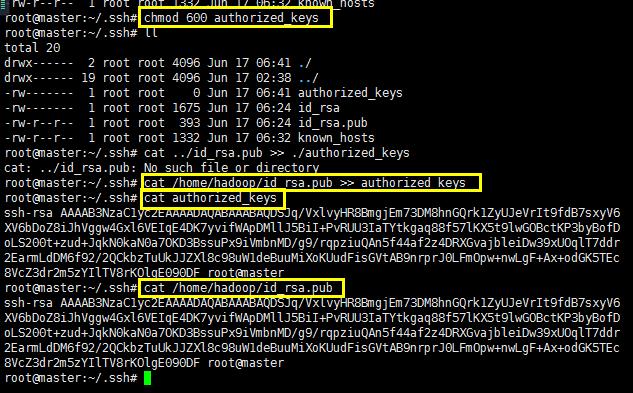
按照上面的操作完成就可以完成master免密钥登陆slaver1主机了;
20:解决伪分布式集群不需要密码解决方法是将自己的公钥加到自己的授权列表里面就可以完成自己登陆自己的免密钥登陆: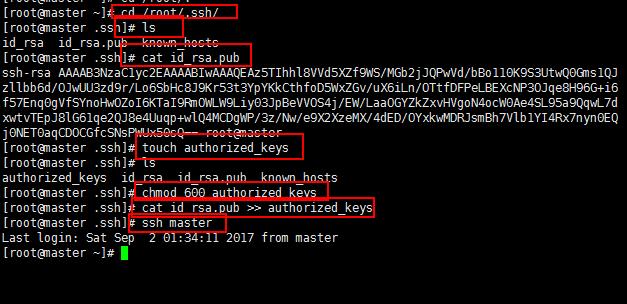
上面的操作完成以后,伪分布式集群登陆自己主机就不需要输入密码了:
至此,伪分布式集群搭建彻底结束。
一个良好的开始会鼓励你更加努力......
以上是关于hadoop伪分布式集群搭建与安装(ubuntu系统)的主要内容,如果未能解决你的问题,请参考以下文章