DDD单根 聚合根 实体 值对象
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DDD单根 聚合根 实体 值对象相关的知识,希望对你有一定的参考价值。
前言
2004年Eric Evans 发表Domain-Driven Design –Tackling Complexity in the Heart of Software (领域驱动设计),简称Evans DDD。快二十年的时间,领域驱动设计在不断地发展,后微服务时代强调的东西,在国外大家都热衷于领域驱动设计解决业务复杂度,在国内吧,我发现除了大厂以外,你和他说,完全不明白,可能很多人对于什么是面向对象开发,都不明白,什么才是真正的面向对象开发;也是在学习中成长着,我建议是从 《设计模式-可复用面向对象软件的基础》 《领域驱动设计:软件核心复杂性应对之道》《实现领域驱动设计》《解构领域驱动设计》 等等这些书看着走,多在项目中实践,就会明白它想给我们创建一个怎样的软件,如何用领域驱动设计应对当今这些复杂的业务逻辑。
首先都是思想(不是技术),我们要明白;所以它很抽象,很难总结出一套方法解构论,就是很抽象,抽象的东西理解起来就很困难,这就是为什么国内一直 想用,但非常难;其实到 解构领域驱动设计 这本书 21 年出版的,我渐渐地发现吧,已经在往“八股文”方向套了;要不然你看前两本书 全是概念,除了大神还可以摸索出来,但是一般人使用了反而更拉。
可以推荐大家 一个学习ddd的网站的,国内的。
什么是DDD
领域驱动设计(Domain-Driven Design,简称DDD)
业务初期,我们的功能大都非常简单,普通的CRUD就能满足,此时系统是清晰的。随着迭代的不断演化,业务逻辑变得越来越复杂,我们的系统也越来越冗杂。模块彼此关联,谁都很难说清模块的具体功能意图是啥。修改一个功能时,往往光回溯该功能需要的修改点就需要很长时间,更别提修改带来的不可预知的影响面。
原型 实体 值对象 ,构成聚合根,都在一个领域里面的。 主要是将领域划边界,方法和领域共存, 然后控制出 领域里面的行为 (方法) 其实将业务服务打的更散,放到对象中, 后面的变化不断应对,后期维护是相当快的。 贫血模型 和充血模型, 这个概念后面说一下。
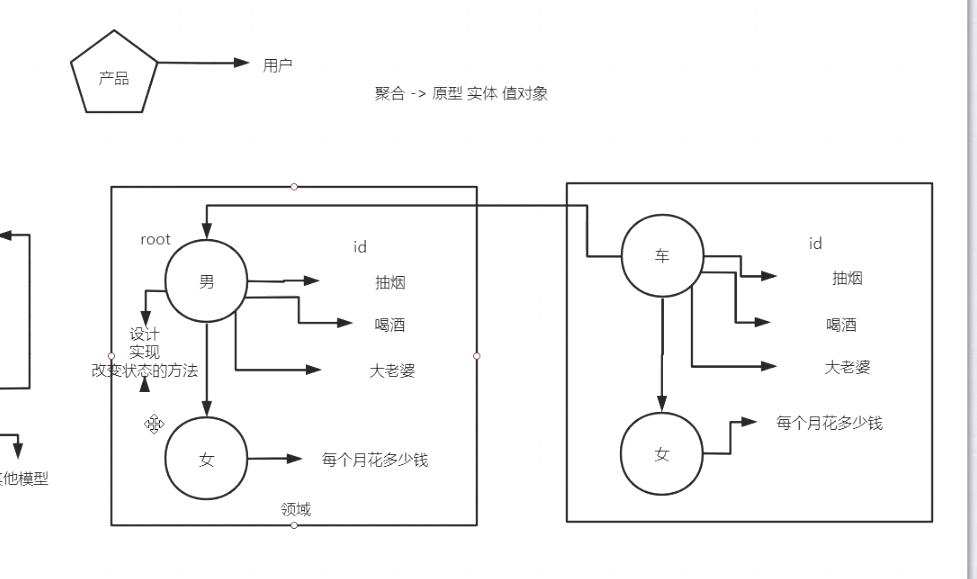
在刚开始开发的时候,我们是这么设计的,随着我们的业务不断发展,我们的项目不断扩大,同时我们的表也是一个订单大表,包含了非常多字段。在我们维护代码时,牵一发而动全身,很可能只是想改下商品的功能,却影响到了创单核心路径。虽然我们可以通过测试保证功能完备性,但当我们在订单领域有大量需求同时并行开发时,改动重叠、恶性循环、疲于奔命修改各种问题。
上述问题,归根到底在于系统架构不清晰,划分出来的模块内聚度低、高耦合。
订单商品模块,假设我们随着数据库区设计:
首先建立模型:
class goods
String id;//主键
String skuId;//唯一识别号
String goodsName;
Bigdecimal price;
Category category;//分类
List<Specification> specifications;//规格
...
class Order
String id;//主键
String orderNo;//订单号
List<OrderItem> orderItems;//订单明细
BigDecimal orderAmount;//总金额
...
class OrderItem
String id;
Goods goods;//关联商品
BigDecimal snapshotPrice;//下单时的价格
考虑到了订单要保存下单时候的价格(当然,这是常识)但这么设计却存在诸多的问题。在分布式系统中,商品和订单这两个模块必然不在同一个模块,也就意味着不在同一个网段中。上述的类设计中直接将Product的列表存储到了Order中,也就是一对多的外键关联。这会导致,每次访问订单的商品列表,都需要发起n次远程调用。
反思设计,其实我们发现,订单BC的Product和商品BC的Product其实并不是同一个entity,在商品模块中,我们更关注商品的规格,种类,实时价格,这最直接地反映了我们想要买什么的欲望。而当生成订单后,我们只关心这个商品买的时候价格是多少,不会关心这个商品之后的价格变动,还有他的名称,仅仅是方便我们在订单的商品列表中定位这个商品。
重点是,领域设计思路需要去脱离数据库的桎梏,最高的预期是根据界限去完成数据库设计,最次。。不需要数据库来绑架我们的系统设计。业务才是王道,一个架构师的核心价值不仅仅体现在框架的应用上,最关键在于能够将我们的系统设计安排得明明白白。
如何改造
class OrderItem
String id;
String productId;//只记录一个id用于必要的时候发起command操作
String skuId;
String productName;
...
BigDecimal snapshotPrice;//下单时的价格
做了一定的冗余,这使得即使商品模块的商品,名称发生了微调,也不会被订单模块知晓。这么做也有它的业务含义,用户会声称:我买的时候他的确就叫这个名字。记录productId和skuId的用意不是为了查询操作,而是方便申请售后一类的命令操作(command)。
在这个例子中,Order 和 goods都是entity,而OrderItem则是value object(想想之前的定义,OrderItem作为一个类,的确是描述了Order这个entity的一个属性集合)。关于标识,我的理解是有两层含义,第一个是作为数据本身存储于数据库,主键id是一个标识,第二是作为领域对象本身,orderNo是一个标识,对于人而言,身份证是一个标识。而OrderItem中的productId,id不能称之为标识,因为整个OrderItem对象是依托于Order存在的,Order不存在,则OrderItem没有意义。
单根 聚合根
在《解构领域驱动设计》 这本书中 是将聚合作为边界的象征,作为所有领域的入口。
聚合(aggregate)是一种边界’它可以封装_到多个实体与值对象’并维持该 边界范围之内的业务完整性°聚合至少包含_个实体’且只有实体才能作为聚合根(aggregateroot)。 工厂(鱼ctory)和资源库(repository)(参见第17章)负责管理聚合的生命周期。前者负责聚合的 创建’用于封装复杂或者可能变化的创建逻辑;后者负责从存放资源的位置(数据库、内存或者其 他Web资源)获取、添加、删除或者修改聚合。
要访问聚合只能通过聚合根的资源库,这就隐式地划定了边界和 入口,有效控制了聚合内所有类型的领域对象。若聚合的创建逻辑较为复杂或存在可变性’可引入工 厂来创建聚合内的领域对象·
聚台的定义与特征
Eric Evans阐释了何谓聚合(aggregate)模式:“将实体和值对象划分为聚合并围绕着聚合定义 边界。选择-个实体作为每个聚合的根’并允许外部对象仅能持有聚合根的引用。作为_个整体来 定义聚合的属性和不变量’并将执行职责赋予聚合根或指定的框架机制°”这一定义说明了聚合的 基本特征。
聚合是包含了实体和值对象的—个边界。 聚合内包含的实体和值对象形成-棵树’只有实体才能作为这棵树的根°这个根称为聚合 根(aggegateroot)’这个实体称为根实体(rootentity)° □外部对象只允许持有聚合根的引用, 以起到边界的控制作用。 □聚合作为_个完整的领域概念整体’其内部会维护这个领域概念的完整性,体现业务上 不变量约束° □由聚合根统_对外提供履行该领域概念职责的行为方法,实现内部各个对象之间的行为 协作。
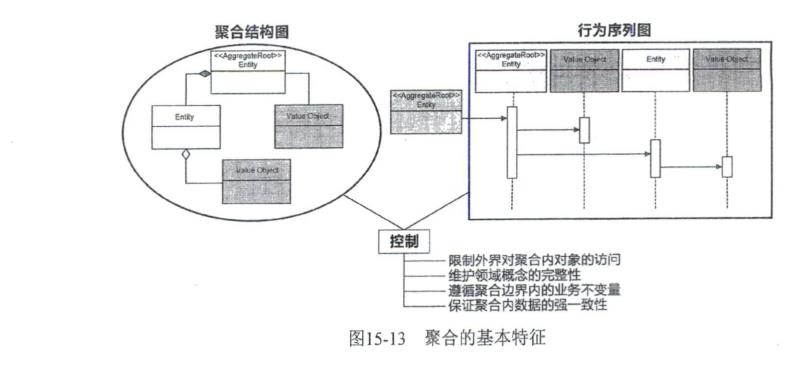
类似于

四种领域模型
失血模型
贫血模型
充血模型
胀血模型
修改商品为例来举例模型的概念
class goods
String id;
String skuId;//唯一识别号
String goodsName;
失血模型**:略过,可以理解为所有的操作都是直接操作数据库。
贫血模型:
class GoodsDao
@Autowired
JdbcTemplate jdbcTemplate;
public void updateName(String name,String id)
jdbcTemplate.excute("update goods u set u.goods_name = ? where id=?",name,id);
class UserService
@Autowired
UserDao userDao;
void updateName(String name,String id)
userDao.updateName(goodsName,id);
贫血模型中,dao是一类sql的集合,在项目中的表现就是写了一堆sql脚本,与之对应的service层,则是作为Transaction Script的入口。观察仔细的话,会发现整个过程中user对象都没出现过。
充血模型
interface UserRepository extends JpaRepository<Goods,String>
//springdata-jpa自动扩展出save findOne findAll方法
class UserService
@Autowoird
UserRepository userRepository;
void updateName(String name,String id)
Goods goods = goodsRepository.findOne(id);
goods.setName(name);
goodsRepository.save(user);
充血模型中,整个修改操作是“隐性”的,对内存中goods对象的修改直接影响到了数据库最终的结果,不需要关心数据库操作,只需要关注领域对象goods本身。Repository模式就是在于此,屏蔽了数据库的实现。与贫血模型中goods对象恰恰相反,整个流程没有出现sql语句。
涨血模型:
没有具体的实现,可以这么理解:
void updateName(String name,String id)
Goods goods = new Goods(id);
goods.setName(name);
goods.save();
我们在Repository模式中重点关注充血模型。
实体 值对象
在领域驱动模型中,战术模型:
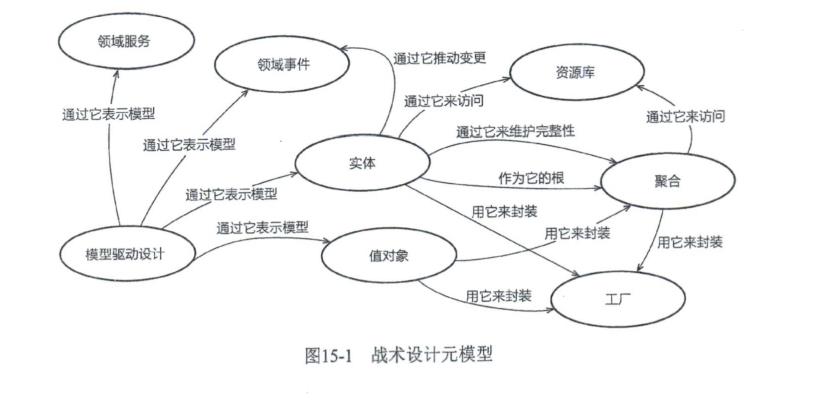
实体
实体(entity)这个词被我们广泛使用’甚至过分使用。设计数据库时,我们用到实体, Len Silverston就说:“实体是一个重要的概念,企业希望建立和存储的信息都是关于实体的信息。’’在分解系统的组成部分时’我们用到实体’EdwardCrawley等人就说:“实体也称为部件、模块、 例程、配件等’就是用来构成全体的各个小块°”
一个典型的实体应该具备3个要素:
身份标识;
属性;
领域行为°
根据ID的共同特征’可以定义一个通用的接口:

通用类型和领域类型ID的区别仅在于值是否代表丁业务含义。作为实体的身份标识,它们都 具有业务价值
实体的属性用来说明主体的静态特征,并持有数据与状态。通常,我们会依据粒度的粗细将 属性分为原子属性与组合属性。定义为开发语言内建类型的属性就是原子属性’如整型、布尔型、 字符串类型等,表述了不可再分的属性概念。
领域行为
实体拥有领域行为,可以更好地说明其作为主体的动态特征。
值对象
值对象(valueohject)通常作为实体的属性,也就是亚里士多德提到的分量、性质、关系、场 所、时间、位置姿态等范畴。正如Eirc Evans所说,“当我们只关心一个模型元素的属性时,应把 它归类为值对象°我们应该使这个模型元素能够表示出其属性的意义,并为它提供相关功能。值对 象应该是不可变的。不要为它分配任何标识′而且不要把它设计成像实体那么复杂 。“
值对象与实体的本质区别
一个领域概念到底该用值对象还是实体类型,第一个判断依据是看业务的参与者对它的相等
判断是依据值还是依据身份标识°—前者是值对象’后者是实体。
值对象具有的特性:
对象创建以后其状态就不能修改;
对象的所有字段都是final类型;
对象是正确创建的(创建期间没有this引用溢出)。
领域行为 : 值对象的名称容易让人误会它只该拥有值’不应拥有领域行为。
实际上,只要采用了对象建 模范式,无论实体对象还是值对象,都需要遵循面向对象设计的基本原则,如信息专家模式,将操 作自身数据的行为分配给它。EircEvans之所以将其命名为值对象,是为了强调对它的领域概念身 份的确认,即关注重点在于值。

微服务架构中的DDD应用
在微服务架构中,我们提倡的是低耦合,高内聚,那么需要达到低耦合高内聚这个目标,我们需要去如何应用DDD领域的概念去完成呢?
在DDD领域中,提供了我们一个非常有意思的东西,叫做界限上下文.界限上下文是怎么来的,我们肯定需要知道,我们要理解一个领域的概念。
以服务端而言,我们需要来界定领域,这时候我们需要来对需求文档进行分析:
根据需求划分出初步的领域和限界上下文,以及上下文之间的关系;
进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象;
对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根;
为聚合根设计仓储,并思考实体或值对象的创建方式;
在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构。
领域
现实世界中,领域包含了问题域和解系统。一般认为软件是对现实世界的部分模拟。在DDD中,解系统可以映射为一个个限界上下文,限界上下文就是软件对于问题域的一个特定的、有限的解决方案。
那么我们的服务端假设只有两个领域--一个是订单,一个是商品,那么我们可以把商品领域进行进一步的细分:
假设商品需求如下(事实上这个和用户角色进行了挂钩,我们先不用去太在意这个,先来理解下领域):
买方商品--可见购买商品,购买者可以看到所有商品(进行价格排序)。
卖方商品--可以去上架商品,上架成功之后购买者就能够看到商品。
供应商商品--可以给销售者提供商品,销售者的商品需要在销售列表中可被选择。
在每一个边界就形成了界限上下文。
在进行上下文划分之后,我们还需要进一步梳理上下文之间的关系。
康威(梅尔·康威)定律任何组织在设计一套系统(广义概念上的系统)时,所交付的设计方案在结构上都与该组织的沟通结构保持一致。
康威定律告诉我们,系统结构应尽量的与组织结构保持一致。这里,我们认为团队结构(无论是内部组织还是团队间组织)就是组织结构,限界上下文就是系统的业务结构。因此,团队结构应该和限界上下文保持一致。
拓展:墨菲定律--每当你觉得可能会发生的时候,这件事一定会发生。
通过我们界限上下文的划分,我们可以开始对商品服务内部进行处理:
import com.dn.goods.bussiness.buyer. ;//买方上下文
import com.dn.goods.bussiness.seller.;//卖方上下文
import com.dn.goods.bussiness.supplier.*;//供应商上下文
整个DDD领域驱动设计,国内还不够成熟,对于小型的项目,我觉得可以使用来作为实验,因为很多时候,你在说撒,可能别个都不懂,这就很尴尬了,更不用说是开发东西了。
以上是关于DDD单根 聚合根 实体 值对象的主要内容,如果未能解决你的问题,请参考以下文章