mysql 分区说明
Posted V青山绿水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 分区说明相关的知识,希望对你有一定的参考价值。
当 mysql的总记录数超过了100万后,性能会大幅下降,可以采用分区方案
分区允许根据指定的规则,跨文件系统分配单个表的多个部分。表的不同部分在不同的位置被存储为单独的表。
1.先看下innodb的数据结构
(1)共享表空间的数据结构

|
1
|
create table t3(id int)engine innodb; |
查看保存的文件t3.frm,ibdata1的文件,存放着所有的表额数据和索引
(2)独立表空间的数据结构

|
1
|
create table t2(id int)engine innodb; |
查看保存的文件
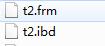
要对innodb进行分区操作,需要要设置innodb的表空间为独立表空间
如果以前不是独立表空间,在设置了innodb_file_per_table=1重启mysql后,使用alter table table_name engine=innodb;修改为独立表空间
2.分区的优势:
(1)与单个磁盘或文件系统分区相比,可以存储更多的数据
(2)很容易就能删除不用或者过时的数据
(3)一些查询可以得到极大的优化
(4)涉及到 SUM()/COUNT() 等聚合函数时,可以并行进行
(5)IO吞吐量更大
分区的限制
- 最大分区数目不能超过1024
- 如果含有唯一索引或者主键,则分区列必须包含在所有的唯一索引或者主键在内
- 不支持外键
- 不支持全文索引(fulltext)
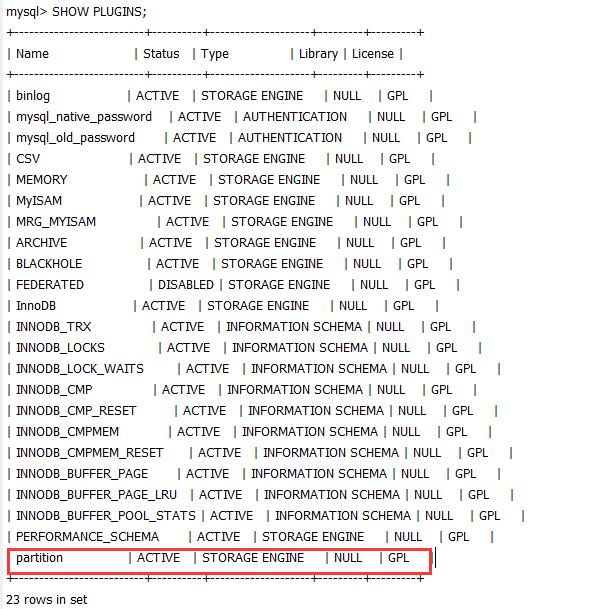
3.查看mysql是否支持分区
|
1
|
SHOW VARIABLES LIKE \'%partition%\' |

或者用
|
1
|
SHOW PLUGINS; |
4.分区类型
(1)RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区。
(2)LIST 分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
(3)HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包>含MySQL中有效的、产生非负整数值的任何表达式。
hash分区的目的是将数据均匀的分布到预先定义的各个分区中,保证各分区的数据量大致一致。
hash的分区函数页需要返回一个整数值。partitions子句中的值是一个非负整数,不加的partitions子句的话,默认为分区数为1。
(4)KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含>整数值。
(5)columns分区
mysql-5.5开始支持COLUMNS分区,COLUMNS分区可以直接使用非整形数据进行分区。COLUMNS分区支持以下数据类型:
所有整形,如INT SMALLINT TINYINT BIGINT。FLOAT和DECIMAL则不支持。
日期类型,如DATE和DATETIME。其余日期类型不支持。
字符串类型,如CHAR、VARCHAR、BINARY和VARBINARY。BLOB和TEXT类型不支持。
COLUMNS可以使用多个列进行分区。
eg:
|
1
2
3
4
5
|
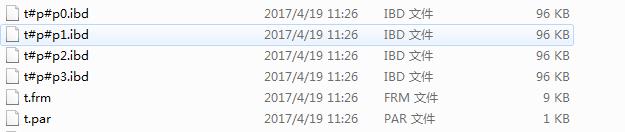
create table t( id int )engine innodb partition by hash(id) partitions 4; |
查看一个该表的文件结构
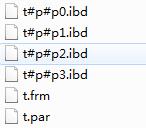
t表实现的分区,分成了4个分区
注:
HASH分区不能删除分区,所以不能使用DROP PARTITION操作进行分区删除操作
ALTER TABLE ... COALESCE PARTITION num来合并分区,num是减去的分区数量;
ALTER TABLE ... ADD PARTITION PARTITIONS num来增加分区,num是在原先基础上再增加的分区数量
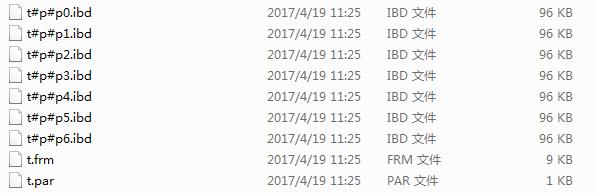
减去两个分区后,数据根据现有的分区进行了重新的分布
|
1
|
ALTER TABLE t ADD PARTITION PARTITIONS 3; |
|
1
|
ALTER TABLE t COALESCE PARTITION 3; |
以上是关于mysql 分区说明的主要内容,如果未能解决你的问题,请参考以下文章