Hive 表数据 加载 导出 查询
Posted 正义飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive 表数据 加载 导出 查询相关的知识,希望对你有一定的参考价值。
hadoop,spark,kafka交流群:224209501
1) 使用 load方式加载数据到Hive表中,注意分区加载数据的特殊性
2) 如何保存 HiveQL查询结果:保存到表中,保存到本地文件 (注意 指定 列 分隔符)
3) 常见的查询练习,如 group by、 having、join 、sort by、order by等。
1,加载数据到表的几种方式
1,加载本地数据文件到hive表中
load data local inpath '/opt/datas/emp.txt' into table db_1128.emp ;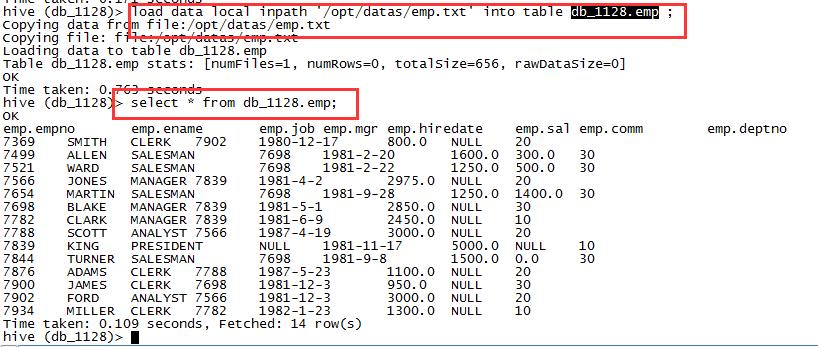
2,加载hdfs文件到hive表中
load data inpath '/user/hadoop/hivewarehouse/emp/emp.txt' into table db_1128.emp ;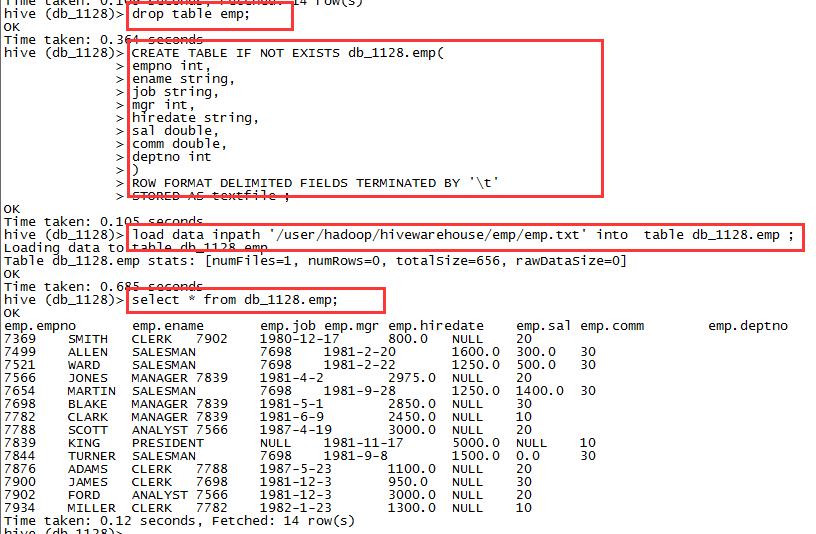
3,加载数据覆盖表中已有的数据
load data local inpath '/opt/datas/emp.txt' overwrite into table db_1128.emp ;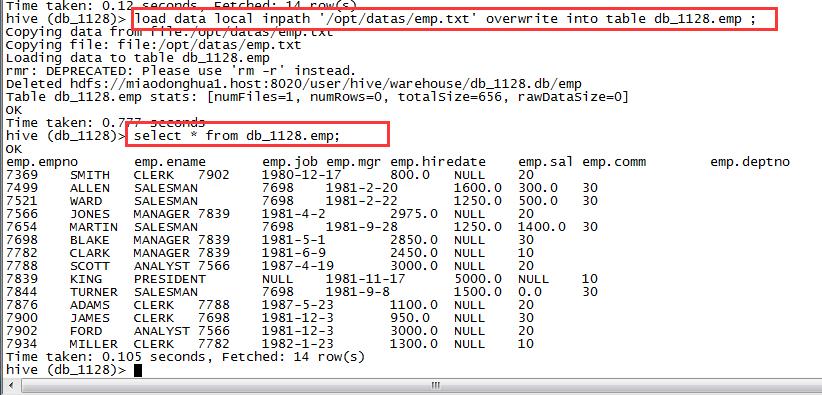
4,创建表时通过select加载
create table db_1128.emp_cs as select * from emp ;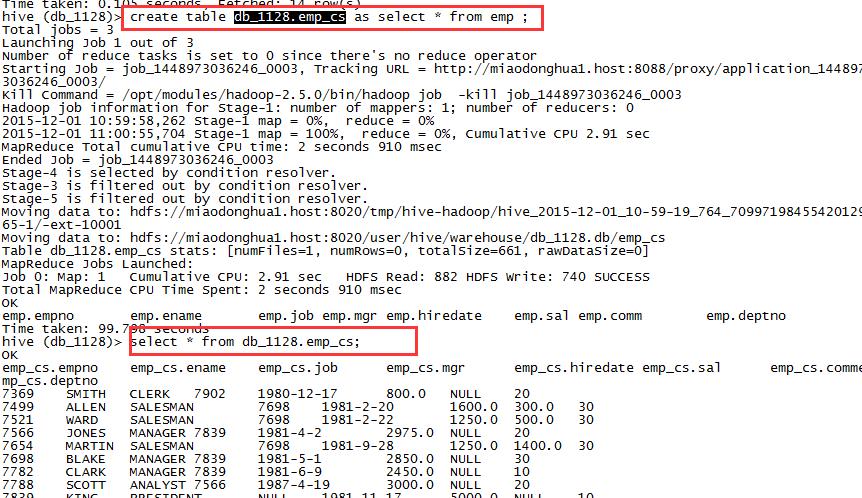
5,创建表时,通过insert加载数据
create table db_1128.emp_ins like db_1128.emp ;
insert into table db_1128.emp_ins select * from
db_1128.emp ;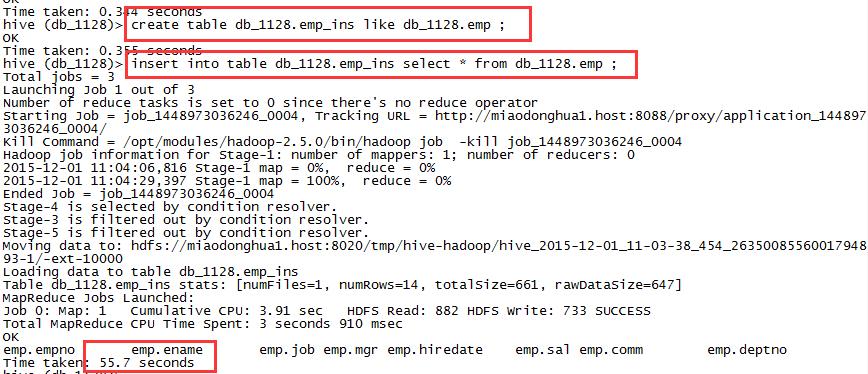
6,创建表时,通过location指定加载
创建目录并上传文件
dfs -mkdir -p /user/hadoop/hivewarehouse/emp;
dfs -put /opt/datas/emp.txt /user/hadoop/hivewarehouse/emp;创建内部表并制定加载路径:
CREATE TABLE IF NOT EXISTS db_1128.emp_spe(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
STORED AS textfile
LOCATION '/user/hadoop/hivewarehouse/emp';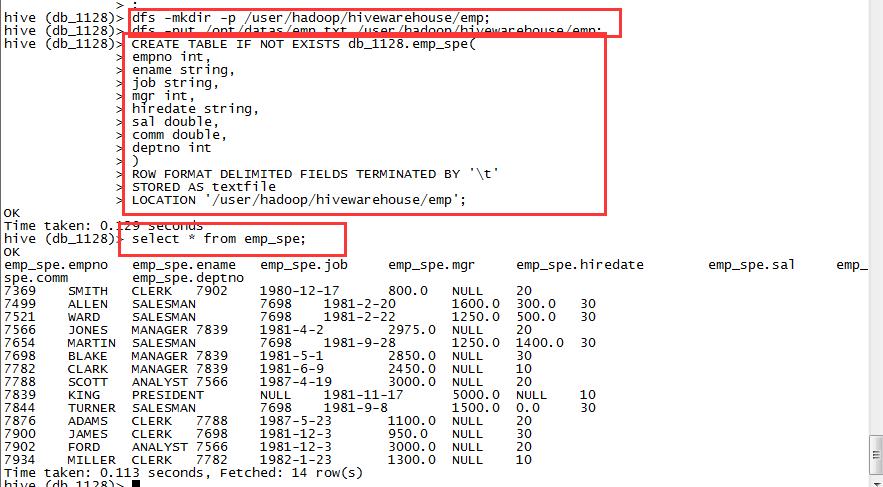
2,导出表数据的几种方式
现在对hive表中数据进行分析,分析完成以后,如何保存数据
select * from db_1128.emp ;1,保存到本地目录的文件中
insert overwrite local directory '/opt/datas/hive_exp_emp2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
select * from db_1128.emp ;
//查看数据
!cat /opt/datas/hive_exp_emp2/000000_0;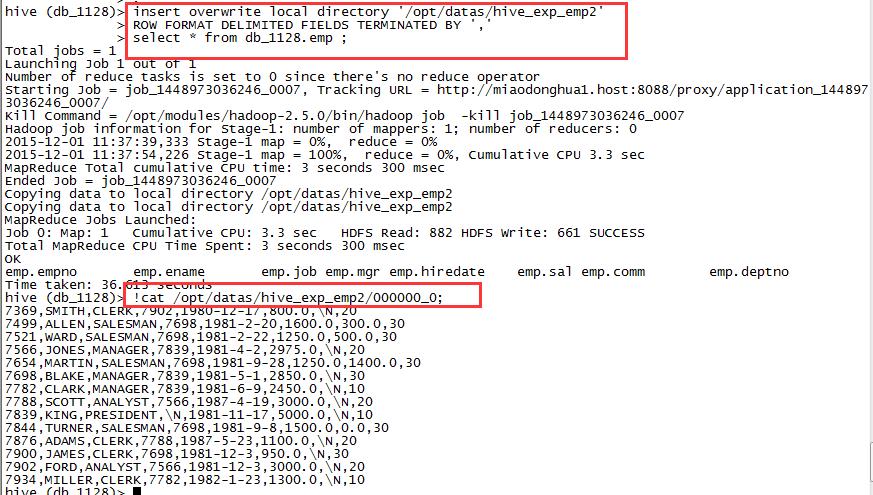
2,保存数据到HDFs文件系统上
insert overwrite directory '/user/beifeng/hive/hive_exp_emp'
select * from db_1128.emp ;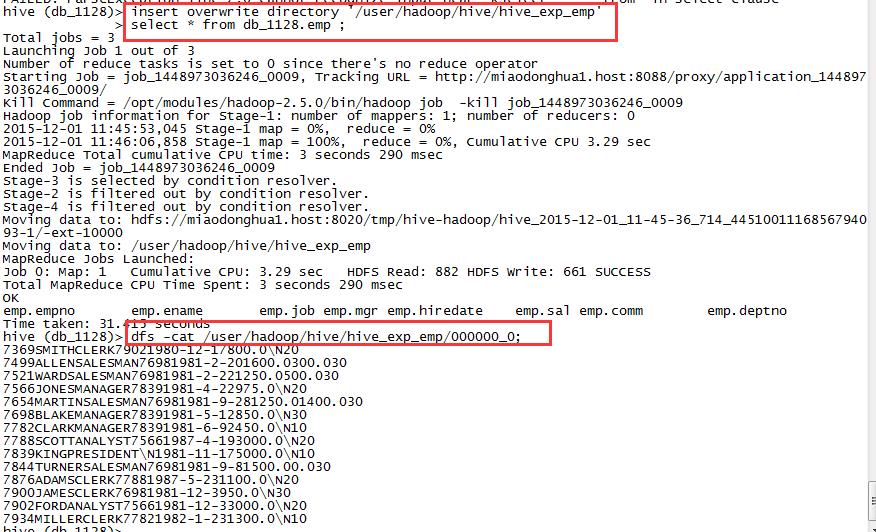
3,在shell中将数据重定向到文件中
bin/hive -e "select * from db_1128.emp ;" > /opt/datas/exp_emp_res.txt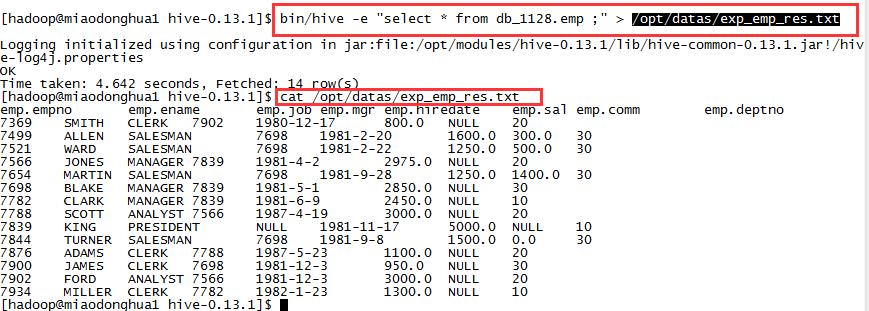
3,数据备份与还原
1,备份数据
EXPORT TABLE db_1128.emp TO '/user/hadoop/hive/datas/export/emp' ;
2,还原数据
先删除emp表。
drop table db_1128.emp;
show tables from db_1128;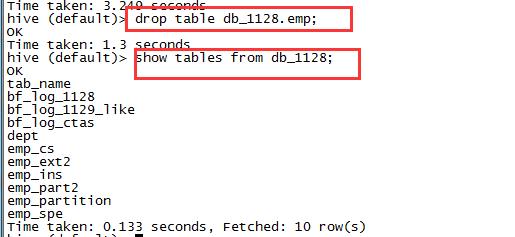
IMPORT FROM '/user/hadoop/hive/datas/export/emp' ;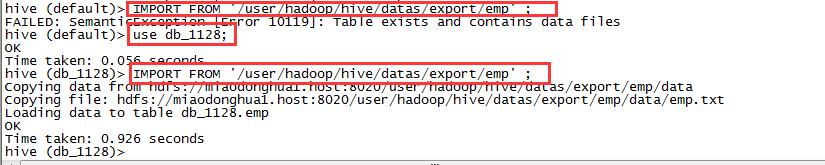
4,查询数据的操作
1,group by
计算每个部门的平均工资
select e.deptno,avg(sal) avg_sal from emp_ext e group by e.deptno ;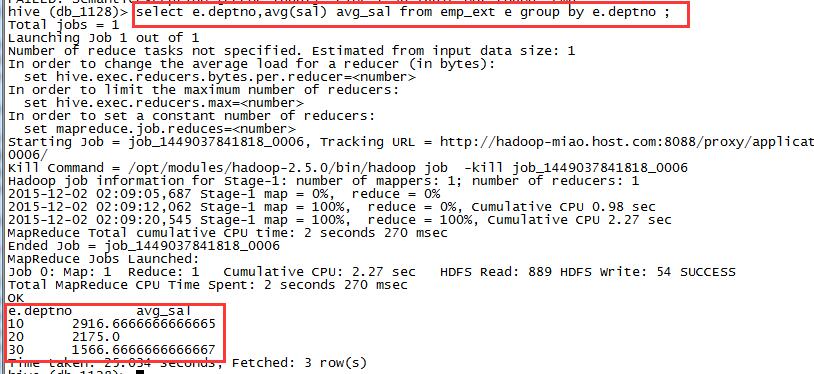
2,having
选出每个部门大于薪水两千的。对分组后进行筛选,where对分组钱进行筛选。
select e.deptno,avg(sal) avg_sal from emp_ext e group by e.deptno having avg_sal > 2000 ;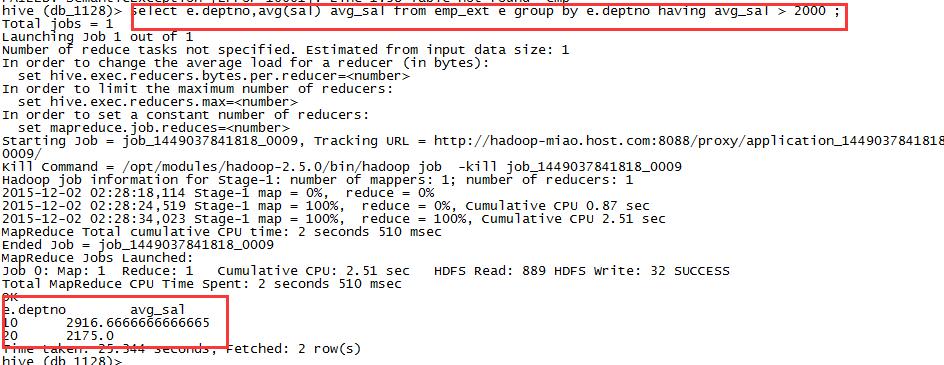
3,等值链接:join
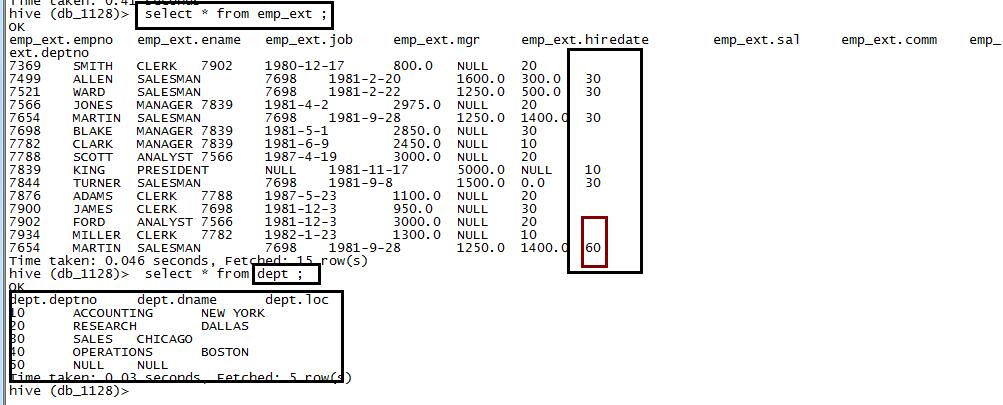
两表数据:
select
e.empno, e.ename, d.deptno, d.dname
from emp_ext e join dept d on e.deptno = d.deptno ; 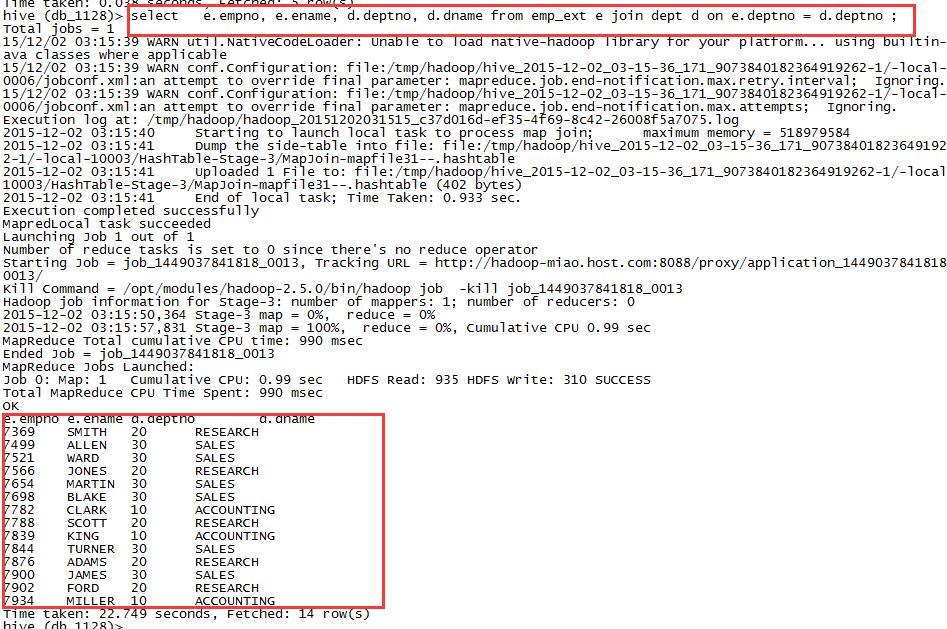
4,左连接:left join
select
e.empno, e.ename, d.deptno, d.dname
from emp_ext e left join dept d on e.deptno = d.deptno ;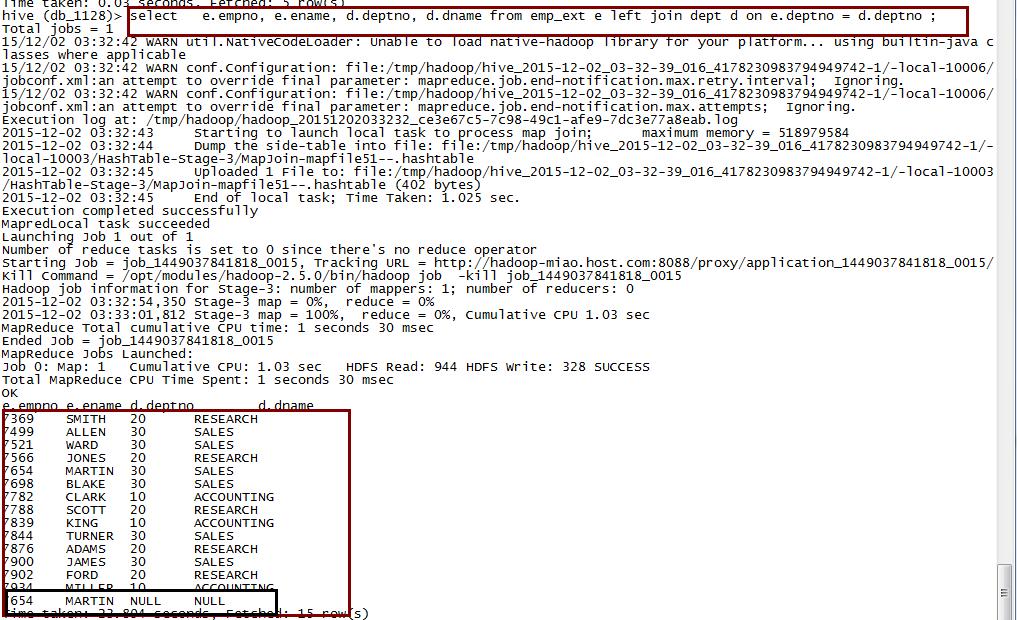
5,右连接:right join
select
e.empno, e.ename, d.deptno, d.dname
from emp_ext e right join dept d on e.deptno = d.deptno ;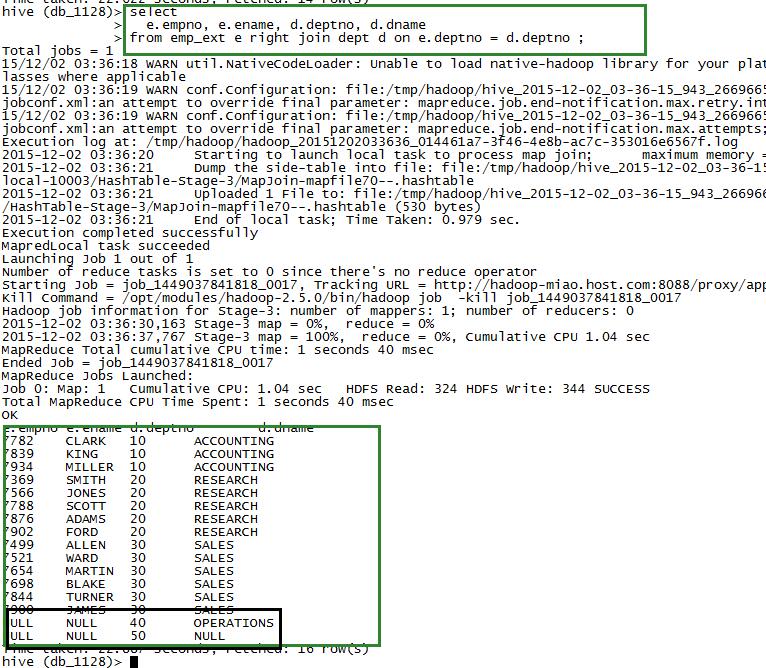
6,全连接:full join
select
e.empno, e.ename, d.deptno, d.dname
from emp_ext e full join dept d on e.deptno = d.deptno ; 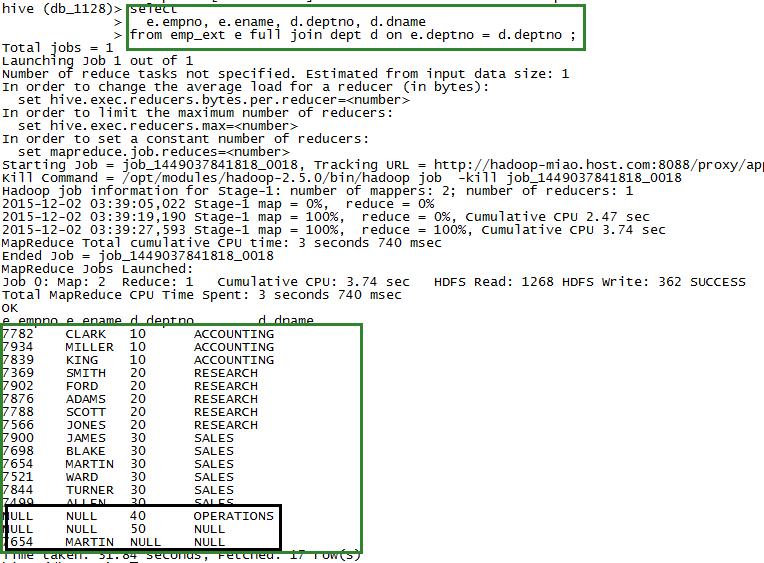
7,sort by
对每一个reduce内部的数据进行排序,全局结果集来说不是排序的
set mapreduce.job.reduces = 3 ;
insert overwrite local directory '/opt/datas/sortby-res'
select * from emp sort by empno desc ;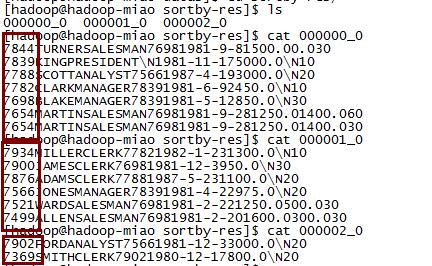
8,distribute by
作用类似于分区partitioner底层就是MapReduce中的分区,通常情况下与sort by 进行使用
insert overwrite local directory '/opt/datas/distby-res'
select * from emp_ext distribute by deptno sort by empno desc ;注意事项:
distribute by 必须要在sort by 前面
sort by是对每个reduce 里面的数据进行排序
9,cluster by
distribute by 和 sort by 字段相同时,使用cluster by 代替
insert overwrite local directory '/opt/datas/clusterby-res'
select * from emp_ext cluster by empno ;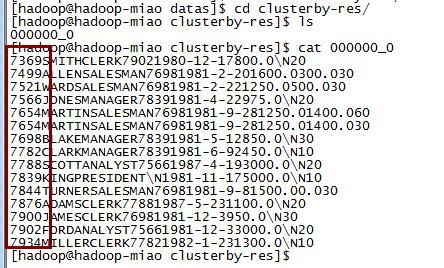
10,order by
全局排序,一个Reduce
select * from emp order by empno desc ;
select * from emp order by empno asc ;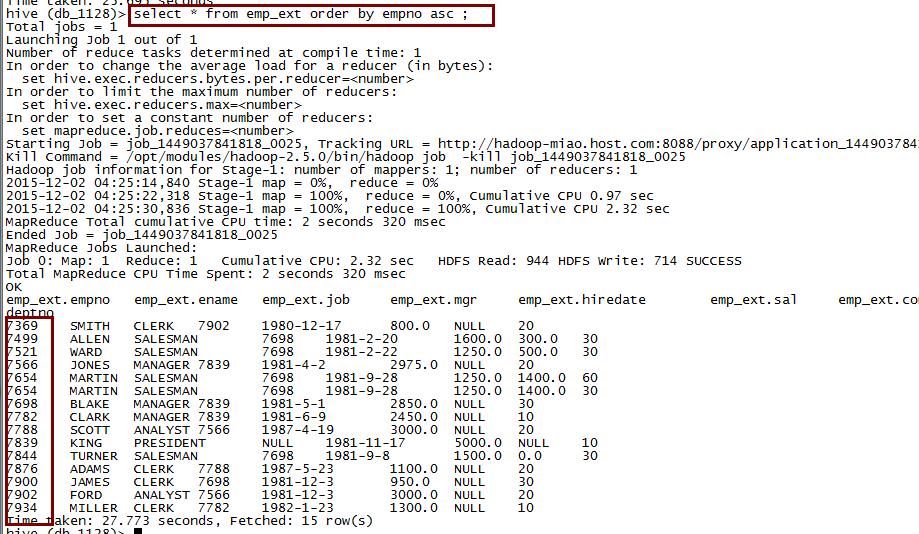
以上是关于Hive 表数据 加载 导出 查询的主要内容,如果未能解决你的问题,请参考以下文章