大数据存储系统三
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据存储系统三相关的知识,希望对你有一定的参考价值。
目录
一、Document Store
1.数据模型
1.1 Json
1.2 Google Protocol Buffer
2.MongoDB
2.1 API and Query Model
2.2 Architecture
二、图存储系统
1.图数据模型
2.Neo4j
3.RDF和Sparql
(本文为陈世敏老师课程笔记)
-----------------------------------------------------
一、Document Store
1.数据模型
1.1 Json
特点:整体是一个object,可以嵌套数组且数组每个元素还可以object,完全动态不需要事先声明。

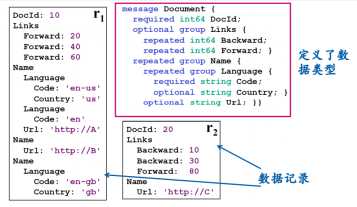
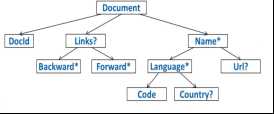
1.2 Google Protocol Buffer
google推出,最初用来做网络协议,可以进行压缩编码和解码,需要预先定义。嵌套关系用语法树表达。
required: 出现1次
repeated: 出现0到多次
optional: 出现0到1次

2.MongoDB
2.1 API and Query Model
JSON是基本数据类型,存储为BSON二进制表示,一个database包含多个collections, 每个collection包含多个documents(<16MB)。
一个database包含多个collections, 每个collection包含多个documents.
Database ~ 关系型中的数据库概念
Collection ~ 关系型中的table概念
Document ~ 关系型中的记录概念
不支持join




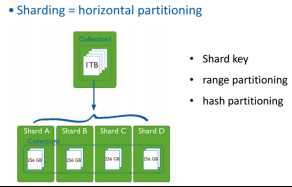
2.2 Architecture
左单机,右分布式。
ACID:
只能保证单个记录修改时候的一致性,没有transaction概念。
并发控制可在document-level/collection-level二选一实现。
Journaling每隔一段时间进行备份,采用write concern界定什么时候认为写完成,有不同的write concern等级:
+Unacknowledged-写请求发送了,就认为完成
+Acknowledged-MongoDB应答了收到写请求,就认为完成
+Journaled-MongoDB把写请求记录在硬盘上的日志中,认为完成
前两种并不能保证掉电后写请求仍然有效。
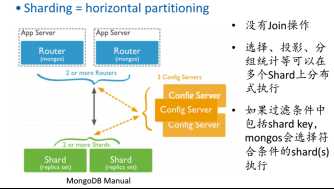
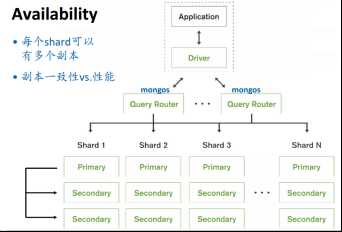
二、图存储系统
1.图数据模型
G=(V,E)
2.Neo4j
2.1 数据存储
自定义结构在本地硬盘存储图,而不是在数据库中,开源Java实现。
+顶点:称为node
+边:称为relationship
+顶点和边上可以存储多个key-value值:称为property
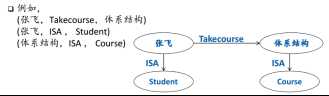
2.2 Cypher举例
Node:(name:type, {property_key:value, key:value})
(张飞:Student,{name:“张飞”,major : “计算机”, year: 2013})
(体系结构:Course,{name:“体系结构”})
Relationship:
-[name:type, {property_key:value, key:value}]->
-[:Takecourse,{year:2014, grade:85}]->
Cypher Create:
CREATE (张飞:Student,{name:“张飞”, major : “计算机”, year: 2013}) 创建点
CREATE (体系结构:Course,{name:“体系结构”}) 创建点
CREATE (张飞)-[:Takecourse,{year:2014, grade:85}]->(体系结构)

Cypher Match:
(a)-[*]->(b) 有路径从a到b
(a)-[*3..5]->(b) 有路径从a到b,路径最短3步,最长5步


2.3 Neo4j系统结构
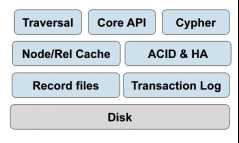
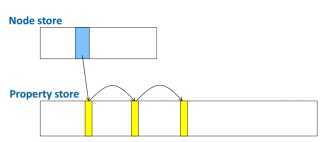
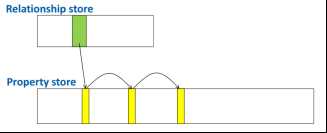
2.4 文件存储
+Node.Relationship.Property 都放在一起存储,有unique id
+relationship 同一个node的relationship是双向链表,指针为relationship id,node 存储第一个的id,每个relationship可能有多个 property。
+Property 是单项链表,链表第一个存在与对应的node/relationship中
+Neo4j对node.relathionship.property缓冲,property以key-value形式附加在node/relationship上
ACID:
定义了transaction概念,采用类似snapshot isolation机制,一个transaction首先保存起来,直到transaction.finish()尝试真正修 改。采用多副本,主副本把transaction log发送到从副本,从副本replay log执行同样操作。
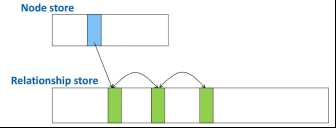
3.RDF和Sparql
Resource Description Framework:w3c标准,广泛用于语义网络。每个RDF记录是三元组(subject, predicate, object)。
Sparql 是RDF的查询语言 ?前缀代表变量,注意“.”

以上是关于大数据存储系统三的主要内容,如果未能解决你的问题,请参考以下文章