Syncretic Modality Collaborative Learning for Visible Infrared Person Re-Identification—建立融合模态,三模态共享
Posted JJxiao24
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Syncretic Modality Collaborative Learning for Visible Infrared Person Re-Identification—建立融合模态,三模态共享相关的知识,希望对你有一定的参考价值。
Syncretic Modality Collaborative Learning for Visible Infrared Person Re-Identification(融合模态协同学习在可见光-红外人重识别中的应用)
期刊合集:最近五年,包含顶刊,顶会,学报>>网址
文章来源:ICCV2021
研究背景
由于不同摄像机之间存在较大的类内变化和图像模态的巨大差异,可见-红外行人重识别(Vi-ReID)具有挑战性。现有的方法主要集中在通过学习身份分类器来捕获跨模态共享表示。然而,不同光谱相机拍摄的异构行人图像在图像风格上存在明显差异,导致特征表示的判别能力较差。本文探讨了两种模态之间的相关性,并提出了一种新的融合模态协作学习模型(SMCL)来弥合跨模态差距,具体来说,就是通过自动构造一种融合异构图像特征的新模态,以引导模态不变表示的生成。后续还将挑战增强同质性学习(CEHL)和辅助分布相似学习(ADSL)相结合,将异质特征投射到统一空间,扩大了类间差异,增强了识别能力。所提出的方法在SYSU-MM01数据集上实现了67.39%的rank1准确率和61.78%的mAP。
论文分析
近期,Li等引入了辅助X模态作为模态不变特征生成的辅助。Ye等提出了一种同质增强灰度模态,增强了对颜色变化的鲁棒性。但是上述方法都忽略了一个问题:中间模态中的特征的分布,如果仅靠可见光的图像来建立新的模态图像,就会出现以下两个问题:1. 中间模态的特征分布只与可见光模态相关,与红外模态无关;2. 红外图像和可见光图像的表征在学习嵌入空间上仍有很大差距,并没有解决模态差异较大的事实。
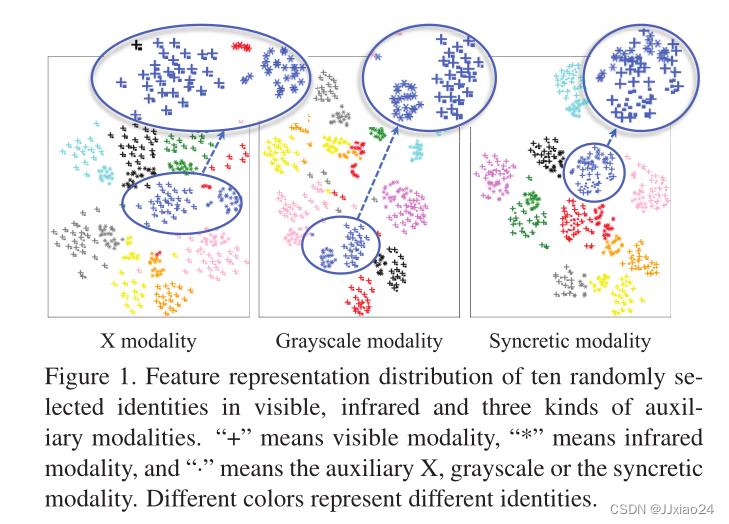
为了解决这个问题,本文引入了融合模态协同学习模型(SMCL)来提高异构行人图像特征分布的相似性。融合模态的图像是由可见光和红外图像自我生成的,因此保留了它们共同的表征,三种形态的相互作用促成了形态共享的行人特征的生成。具体而言,由于红外图像缺乏颜色信息且难以区分,通过对红外图像的身份分类器施加压力来进行挑战增强同质性学习(CEHL),从而增强嵌入式表示的识别能力。此外,还设计了辅助分布相似学习(ADSL),通过三个方向约束来最小化数据分布中心之间的距离。最后,还引入了增量训练(IT)策略:首先进行表示学习来粗略地限制跨模态特征分布,然后执行度量学习来进一步缩小模态差异。
论文贡献点如下:
(1) 通过构建一个结合可见光和红外图像信息的自生成模态,为VI-REID任务提出了一种新的融合模态协同学习模型,三种模态的联合学习使网络具有较高的辨识性,能够捕获模态不变表示。
(2) 引入挑战增强同质性学习(CEHL)来增加红外图像分类器的难度,从而促使网络获得更多的鉴别特征以进行正确的分类。此外,利用辅助分布相似学习(ADSL),通过三向距离抑制来缩小跨模态差距。
SMCL网络框架
采用ResNet-50模型作为骨干网络,使用Adam作为优化器,利用余弦相似度来测量异质特征的距离。
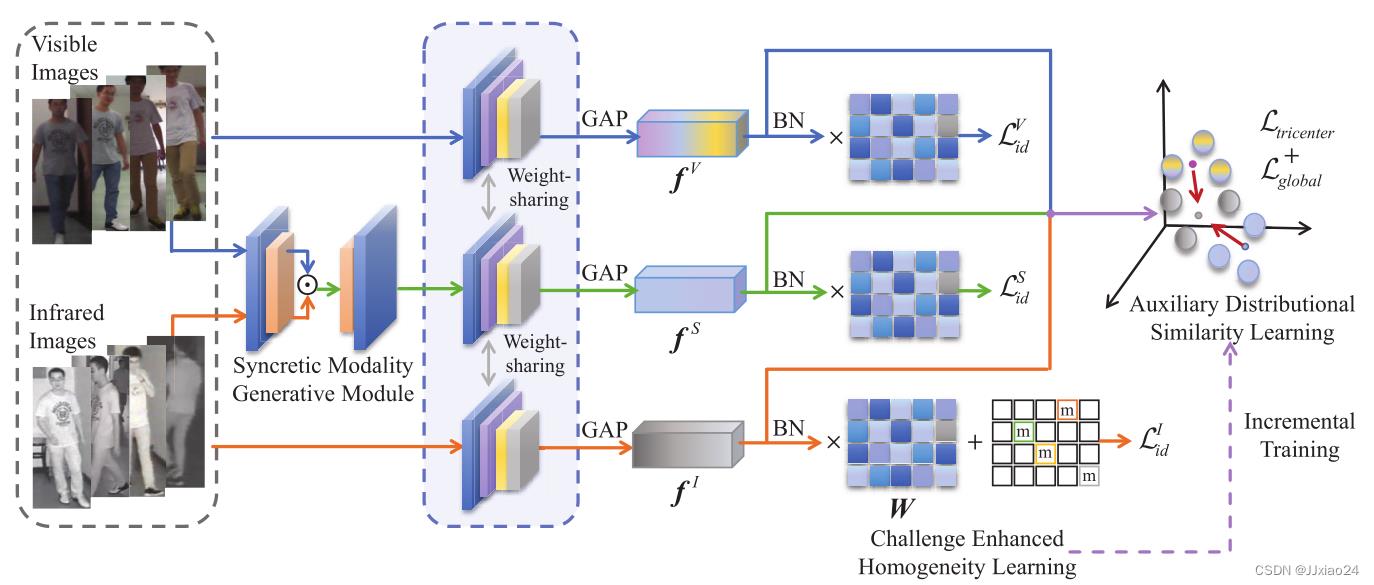
1、Syncretic Modality Generative Module(融合模态生成模块)
融合模态生成模块显示如下:
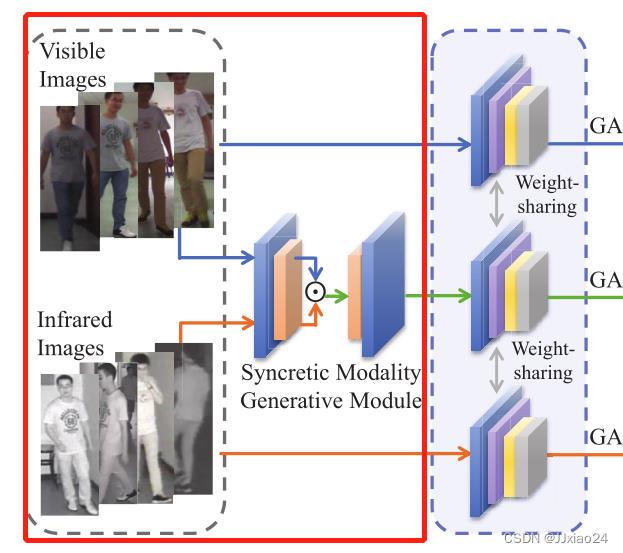
首先,将异构图像发送到由两个1×1卷积层组成的轻量级网络,进行的是像素到像素的特征融合的操作,在第一卷积层之后构建了融合模态,表示如下:
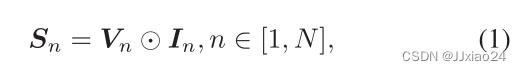
然后,提供了一个ReLU激活层,以提高融合模态表示的非线性能力。通过第二次1×1卷积运算,融合模态的特征大小与红外和可见光图像的特征大小一致,可以发送到参数共享的CNN进行三模态共享特征学习。
2、Challenge Enhanced Homogeneity Learning(挑战增强同质性学习)
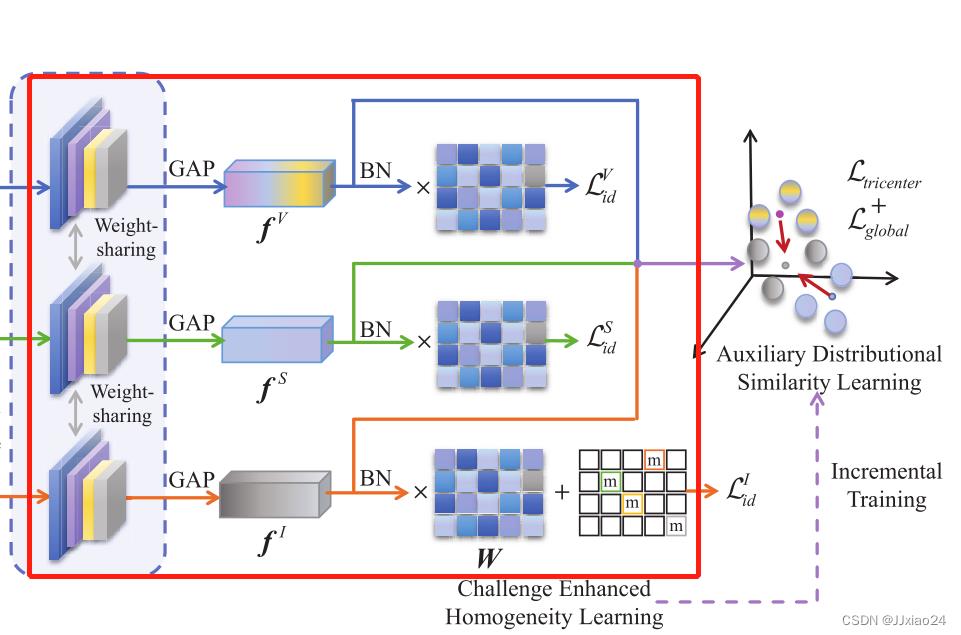
为了获得模态共享的身份识别表示,文章引入CEHL在一致空间上投射跨模态表示。依次通过CNN、全局平均池化(GAP)和批量归一化(BN)操作,将特征向量输入到全连通层进行身份分类。
使用Softmax损失进行判别表示学习,如下。
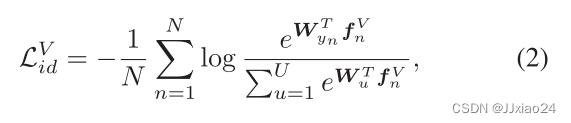
VI-REID的关键挑战主要在于红外图像和可见光图像之间缺乏均匀表示。因为由于标准的Softmax损失分类器对红外图像的鉴别能力较弱,所以文章为了增强身份分类器的能力,对分类器增加了难度,并设计了一个改进的softmax损失,表示如下:
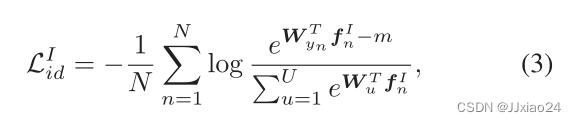
其中m是对分类器设置的难度。通过认为设置难度刺激网络进一步学习特定身份的特征,以进行正确的分类,同时,训练阶段融合模态的联合(Weight-sharing)带来了更多的模态共享信息,从而提高了类内跨模态的相似度。完整的同一性损失可以写成:
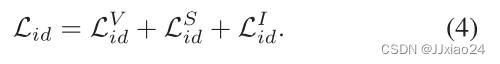
3、Auxiliary Distributional Similarity Learning( 辅助分布相似学习)
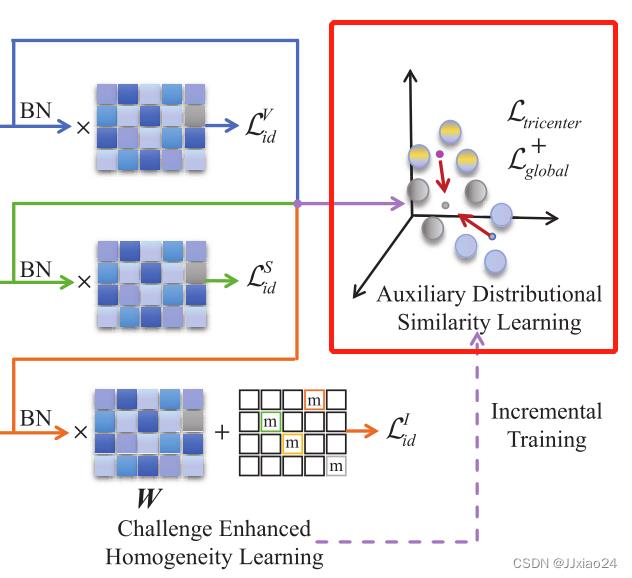
为了增强跨模态类内相似度和扩大模态类间差异,需要考虑三种模态之间的相关性,设计一个基于三向中心的约束损失和一个全局中心约束损失。利用融合模式的特征分布中心作为锚点,如上图所示,假设一个小批中有P个身份的P × K张图像,其中每个身份包含K张图像。那么融合模态中身份的特征分布中心可以表示为:
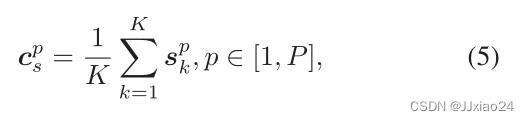
其中spk为GAP输出的第k张图像的特征向量。
引入的三向中心的约束损失来处里各个锚点与中心之间的距离:
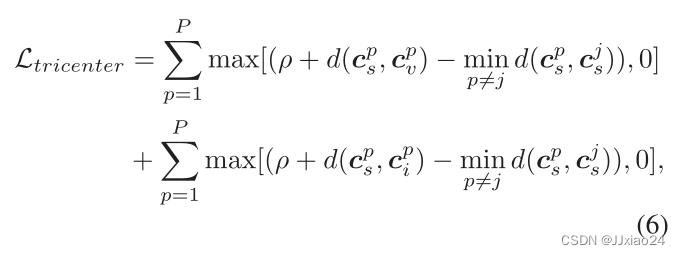
其中Cpv和Cpi是第p个身份的可见光和红外特征的中心,p和j代表一个小批中的不同身份。
这样做的目就是为了拉近同一身份的不同模态中心之间的距离(欧拉距离:d),推开不同身份的融合模态中心,从而抑制跨模态的变化,同时保证高度的可辨性。
为了避免造成以融合模态为中心的局部最优,设计了局部中心约束损失(Lglobal),直接用来抑制可见光特征和红外特征之间的中心距离,可表示为:
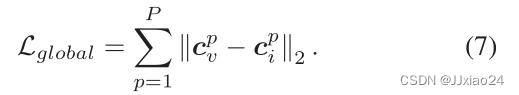
对于相同身份的特征,不仅以融合模态的特征为中介,促进跨模态分布的相似性,而且增加了对异构图像的直接限制;对于不同身份的特征,利用融合模态的中心来扩大特征距离。ADSL的损失可以写成:
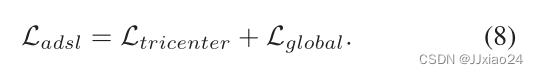
通过对SMCL模型的分析,总的损失就可以表示为:
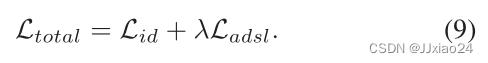
4. Incremental Training Strategy(增量训练策略)

由于异构图像在初始状态下是随机分布的,联合训练可能会导致两种学习方式的梯度下降方向不一致,直接会影响学习的效率。为了提高效率,提出了增量训练策略:CEHL在训练的初始阶段对同一行人的特征进行粗聚类,随后进行CEHL的协同学习,通过ADSL缩小了特征距离,增强了跨模态类内表示的相似性。
所提出的IT策略可以处理由粗到细的异构图像分布,从而增强了嵌入特征的鉴别能力。
实验结果
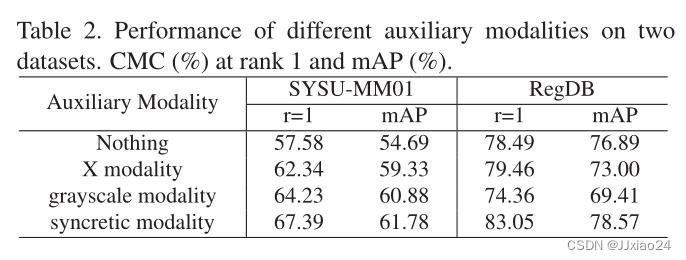
通过消融实验可以得出,辅助模态的加入,可以很好的诱导模态共享表示的生成 ,而从表中可以看到,在sysu-mm01数据集上,灰度模态的性能是要优于X模态的,而融合模态更是优于另外两种模态,说明灰度图像能映射出更多的异构特征;在RegDB数据集上,结果是相反的。
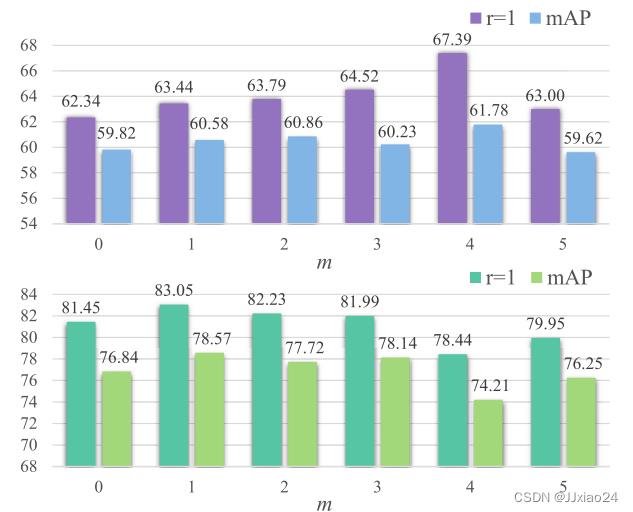
通过对上表的分析,通过稍微设置分类器难度m可以获得更好的性能,但随着m的依次增大,性能会下降。在SYSU-MM01数据集上,因为有了很多的光照、身体姿态的影响,模态类内差异较大,所以必须引入难度m监督学习,而RegDB不用。
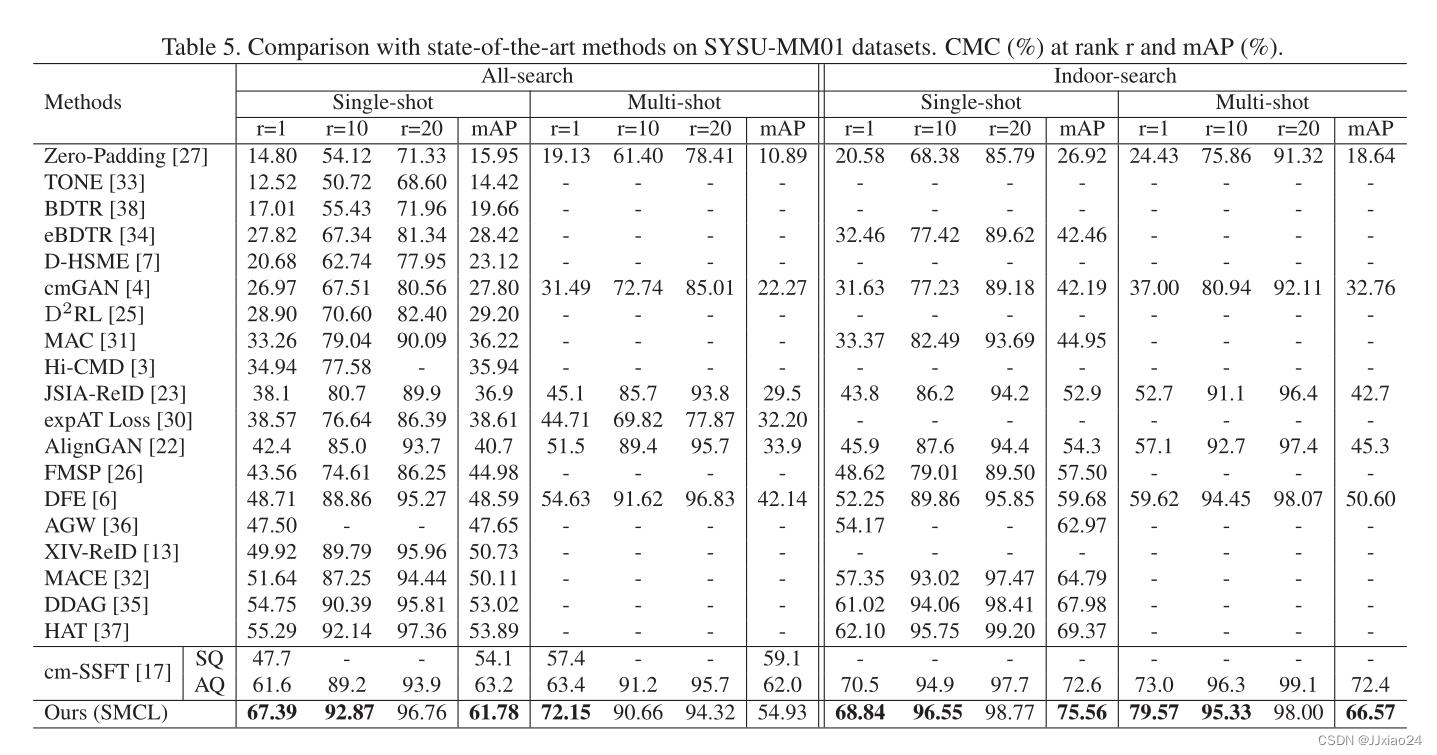
上图为在SYSU-MM01数据集上的效果。
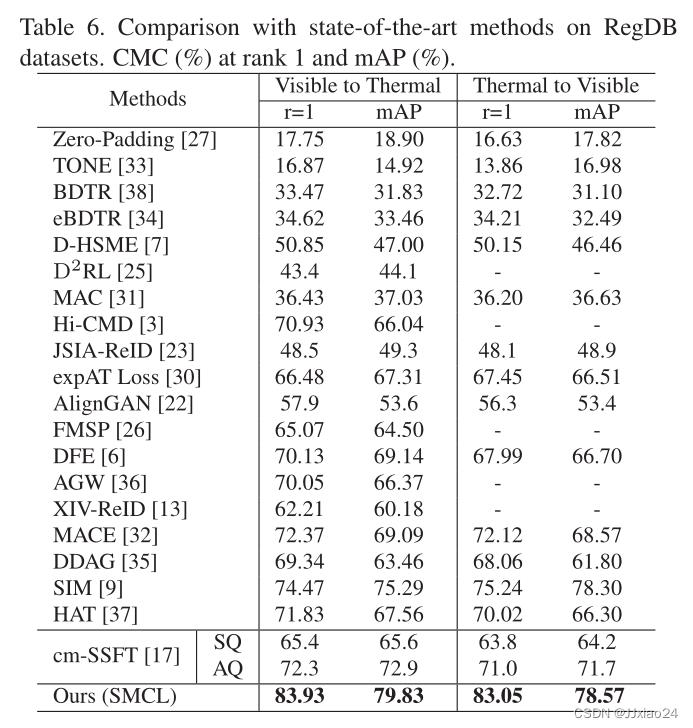
上图为在RegDB数据集上的效果。
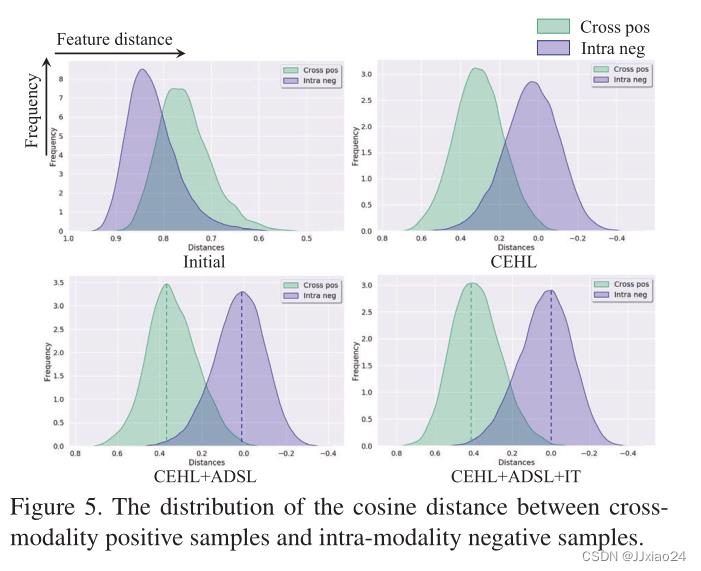
通过增加CEHL+ADSL+IT等三个组件,特征距离会变得越来越远,就可以达到扩大阴性样本之间的距离,减少阳性样本之间的差异,从而提高检索的精度。
结论
在本文中,提出的融合模态协作学习(SMCL)模型来学习VIREID的模态不变身份判别表示。融合模态的自生成特征保留了可见光和红外图像的重要信息,通过挑战增强的同质性学习和辅助的分布式相似学习,可以引导网络在公共空间上投射异构图像。在SYSU-MM01和RegDB数据集上的大量实验证明了SMCL模型的优越性能。
以上是关于Syncretic Modality Collaborative Learning for Visible Infrared Person Re-Identification—建立融合模态,三模态共享的主要内容,如果未能解决你的问题,请参考以下文章