Hive详解
Posted 阿德小仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive详解相关的知识,希望对你有一定的参考价值。
目录
5.1.3 查询语句中创建表并加载数据(As Select)
5.1.4 创建表时通过 Location 指定加载数据路径
6.1.7 比较运算符(Between/In/ Is Null)
第1章 Hive基本概念
1.1 什么是Hive
1)hive简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张表,并提供类SQL 查询功能。
- Hive本质:将HQL转化为Mapreduce程序
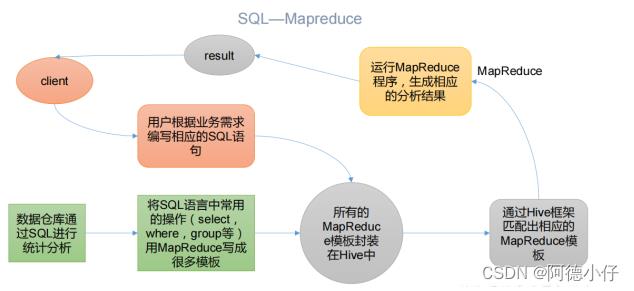
(1)Hive 处理的数据存储在 HDFS
(2)Hive 分析数据底层的实现是 MapReduce
(3)执行程序运行在 Yarn 上
1.2 Hive的优缺点
1.2.1 优点
(1)操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写 MapReduce,减少开发人员的学习成本。
(3)Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求 不高的场合。
(4)Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
(5)Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函 数。
1.2.2 缺点
1)Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更
高的算法却无法实现。
2)Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗
1.3 Hive架构原理
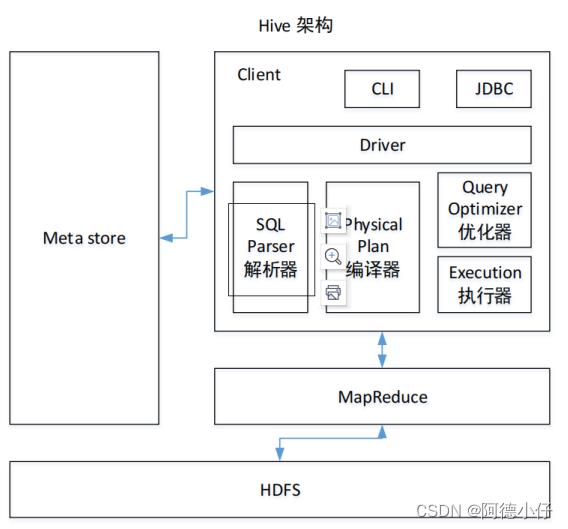
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 mysql 存储 Metastore
3)Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4)驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第 三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。
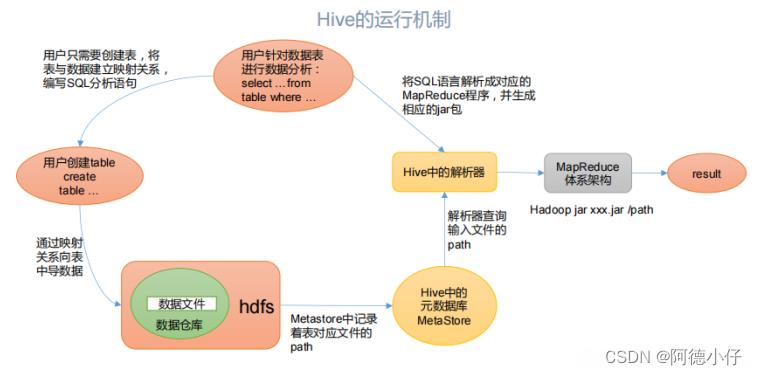
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
1.4 Hive和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
1.4.1 查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
1.4.2 数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修 改数据。
1.4.3 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导 致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此 在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。 当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
1.4.4 数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
第2章 Hive安装
2.1 Hive的安装地址
1.Hive官网地址:
http://hive.apache.org/
2.文档查看地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3.下载地址:
http://archive.apache.org/dist/hive/
4.github 地址
https://github.com/apache/hive
2.2 Hive安装部署
1.Hive安装以及配置
(1)把apache-hive-1.2.1-bin.tar.gz上传到linux的/usr/local/packages目录下
(2)解压 apache-hive-1.2.1-bin.tar.gz 到/usr/local/soft/目录下面
| [root@master packages]# tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local/soft/ |
(3)修改 apache-hive-1.2.1-bin.tar.gz 的名称为 hive
| [root@master soft]# mv apache-hive-1.2.1-bin/ hive |
(4)修改/usr/local/soft/hive/conf 目录下的 hive-env.sh.template 名称为 hive-env.sh
| [root@master conf]# mv hive-env.sh.template hive-env.sh |
(5)配置 hive-env.sh 文件
(a)配置 HADOOP_HOME 路径
| export HADOOP_HOME=/usr/local/soft/hadoop-2.7.6 |
(b)配置 HIVE_CONF_DIR 路径
| export HIVE_CONF_DIR=/usr/local/soft/hive/conf |
(c)配置 JAVA_HOM 路径
| export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 |
(6)配置hive的环境变量
| export HIVE_HOME=/usr/local/soft/hive export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH |

- Hive基本启动
(1)启动Hive
| [root@master conf]# hive |

(2)查看数据库
| hive> show databases; |

(3)打开默认数据库
| hive> use default; |
(4)显示 default 数据库中的表
| hive> show tables; |

(5)创建一张表
| hive> create table student(id int,name string,gender string); |

(6)查看表的结构
| hive> desc student; |

(7)向表中插入数据
| hive> insert into student values(2012003,"lyj","0"); |
(8)查询表中数据
| hive> select * from student; |
(9)退出 hive
| hive> quit; |
说明:(查看 hive 在 hdfs 中的结构)
数据库:在 hdfs 中表现为$hive.metastore.warehouse.dir目录下一个文件夹
表:在 hdfs 中表现所属 db 目录下一个文件夹,文件夹中存放该表中的具体数据
2.3 将本地文件导入Hive案例
将本地/usr/local/soft/data/student.txt 这个目录下的数据导入到 hive 的 student(id int, name string,gender string)表中。
- 数据准备
在/usr/local/soft/data/这个目录下准备数据
(1)在/usr/local/soft/目录下创建 data
| [root@master soft]# mkdir data |
(2)在/usr/local/soft/data目录下创建 student.txt 文件并添加数据
| [root@master data]# touch student.txt [root@master data]# vi student.txt 2012003,lyj,0 2121001,lzh,1 2121002,wkh,1 2121003,jy ,0 2121004,syx,0 |
注意:以 "," 键间隔。
- Hive实际操作
(1)启动 hive
| [root@master data]# hive |
(2)显示数据库
| hive> show databases; |
(3)使用 default 数据库
| hive> use default; |
(4)显示 default 数据库中的表
| hive> show tables; |
(5)删除已创建的 student 表
| hive> drop table student; |
注意:没有表就忽略。
(6)创建 student 表, 并声明文件分隔符’,’
| create table student( id int, name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; |
(7)加载/usr/local/soft/data/student.txt 文件到 student 数据库表中。
| hive> load data local inpath '/usr/local/soft/data/student.txt' into table student; |

(8)Hive 查询结果
| hive> select * from student limit 10; OK 2012003 lyj 2121001 lzh 2121002 wkh 2121003 jy 2121004 syx 2121005 ntt 2121006 gyl 2121007 hcr 2121008 xhy |
- 遇到的问题
再打开一个客户端窗口启动 hive,会产生 java.sql.SQLException 异常。
| [root@master data]# hive Logging initialized using configuration in jar:file:/usr/local/soft/hive/lib/hive-common-1.2.1.jar!/hive-log4j.propertie Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.jav a:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136) Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java: 1523) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init> (RetryingMetaStoreClient.java:86) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaSt oreClient.java:132) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaSt oreCli 以上是关于Hive详解的主要内容,如果未能解决你的问题,请参考以下文章 |