Python - 使用多处理并行处理受 CPU 限制的任务
Posted crazy_itman
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python - 使用多处理并行处理受 CPU 限制的任务相关的知识,希望对你有一定的参考价值。
多元处理(英语:Multiprocessing),也译为多进程、多处理器处理、 多重处理,指在一个单一电脑系统中,使用二个或二个以上的中央处理器,以及能够将计算工作分配给这些处理器。拥有这个能力的电脑系统,也被称为是多元处理器系统(Multiprocessing system)。当系统拥有多个处理器时,在同一时间中,可能有数个程序在执行。有时候,运行并发性程序,也会被称为是多元处理。只是当使用在软件时,通常会称为多元程序(multi-programming),或多任务处理(multitasking)。多元处理主要用于指超过一个以上处理器的电脑硬件架构的计算能力。在对称多处理(Symmetric multiprocessing)架构中,每个处理器的地位都平等,拥有同样的权限可以使用系统资源。在非对称式架构中,处理器之间的地位并不平等,系统资源以不同方式来分配给特定处理器。非对称架构,可分成非对称多处理(Asymmetric multiprocessing)系统、非均匀访存模型系统、与集群多处理系统。
什么是多线程软件?
所有软件都在“进程空间”中运行。这是内存中分配给运行程序的空间。像 Windows 和 Linux 这样的现代操作系统有一个内核管理器来管理这个进程空间并为每个进程或软件片段安排时间。操作系统 (OS) 可以调度的最小进程时间单位通常称为“线程” 。通常发生的情况是一段软件在单个线程的进程空间中运行。这称为单线程应用程序。这样做的缺点是软件不能真正完成某些高级任务,或者同时处理多行逻辑(特别是如果它在磁盘上做一些非常密集的事情,加载一些大的东西,你仍然希望程序对用户输入做出反应)。特别注意(相关但不是线程思想的核心):在处理多项任务时,很多事情并不是同时发生的。这不完全正确。现代处理器(CPU 芯片)有“流水线”、预取、分支的方法,并有多个 cpu 内核来并行运行。但是,OS 调度程序实际上只是非常快速地调度东西,在不同线程之间来回切换(其中一些可能确实在 CPU 级别并行/同时发生)。较旧的操作系统使用一种称为协作多任务处理的概念。这是一个令人讨厌的情况,在这种情况下,更旧版本的 Windows(想想 Win 3.1)可能会被冻结,因为每个进程(或应用程序)都必须放弃其执行时间片以将其交给其他程序,因此它们可以继续。同样,这一切都发生得非常快,以产生一切都在同时发生的错觉。后来的操作系统开始使用今天很常见的东西,被称为抢占式多任务处理。这是一个操作系统有自己的任务调度器/管理器的系统,它控制所有内存和进程空间、线程、时间片等……程序不做决定。他们有一定的时间,仅此而已。如果他们挂起,操作系统将强制进程耗尽内存并将其关闭。
多线程应用程序允许调度多个线程。软件进程会告诉操作系统创建多个线程,因为它会做一些其他的事情,需要在自己的进程空间中运行,向其他进程报告,等等。进度条就是一个很好的经典例子。它允许您继续使用程序做事,继续工作,同时您会看到进度条正在做它的事情。这是通过一个线程处理进度条而另一个线程处理您的用户输入和更新 UI 来实现的;他们必须小心合作。多线程变得非常棘手,您必须非常小心以确保您的程序是线程安全的(例如同时访问共享数据/内存)。
Python - 使用多处理并行处理受 CPU 限制的任务
线程不适合 CPU 密集型任务,应该使用多处理。在这里,我想用基准数字来证明这一点,同时也表明在 Python 中创建多个进程与创建多个线程一样简单。
首先,让我们选择一个简单的计算用于基准测试。我不希望它完全是人为的,所以我将使用因式分解的简化版本——将数字分解为其质因数。这是一个非常幼稚且未优化的函数,它接受一个数字并返回一个因子列表:
def factorize_naive(n):""" A naive factorization method. Take integer 'n', return list offactors."""if n < 2:return []factors = []p = 2while True:if n == 1:return factorsr = n % pif r == 0:factors.append(p)n = n / pelif p * p >= n:factors.append(n)return factorselif p > 2:# Advance in steps of 2 over odd numbersp += 2else:# If p == 2, get to 3p += 1assert False, "unreachable"
现在,作为基准测试的基础,我将使用以下串行(单线程)因子分解器,它接受要分解的数字列表,并返回一个将数字映射到其因子列表的字典:
def serial_factorizer(nums):return n: factorize_naive(n) for n in nums
线程版本如下。它还需要一个要分解的数字列表,以及要创建的线程数量。然后它将列表分成块并将每个块分配给一个单独的线程:
def threaded_factorizer(nums, nthreads):def worker(nums, outdict):""" The worker function, invoked in a thread. 'nums' is alist of numbers to factor. The results are placed inoutdict."""for n in nums:outdict[n] = factorize_naive(n)# Each thread will get 'chunksize' nums and its own output dictchunksize = int(math.ceil(len(nums) / float(nthreads)))threads = []outs = [ for i in range(nthreads)]for i in range(nthreads):# Create each thread, passing it its chunk of numbers to factor# and output dict.t = threading.Thread(target=worker,args=(nums[chunksize * i:chunksize * (i + 1)],outs[i]))threads.append(t)t.start()# Wait for all threads to finishfor t in threads:t.join()# Merge all partial output dicts into a single dict and return itreturn k: v for out_d in outs for k, v in out_d.iteritems()
请注意,主线程和工作线程之间的接口非常简单。每个工作线程都有一些工作要做,之后它就简单地返回。因此,主线程唯一要做的就是用合适的参数启动nthreads 个线程,然后等待它们完成。
我使用 2、4 和 8 个线程运行了串行与线程分解器的基准测试。基准是分解一组恒定的大数,以最小化由于随机机会引起的差异。所有测试都在我的 Ubuntu 10.04 笔记本电脑上运行,该笔记本电脑配备英特尔酷睿 i7-2820MQ CPU(4 个物理内核,超线程)。
以下是结果:
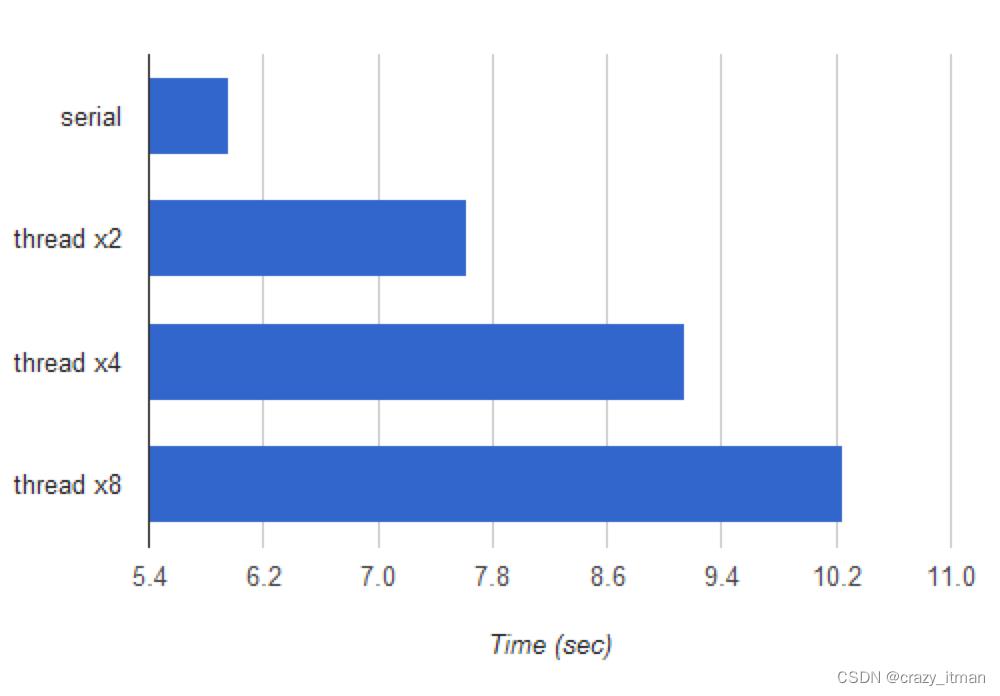
水平轴是以秒为单位的时间,因此较短的条形意味着更快的执行。是的,将计算拆分为多个线程实际上比串行实现要慢,而且使用的线程越多,速度就越慢。
如果您不熟悉 Python 线程的实现方式和 GIL(全局解释器锁),这可能有点令人惊讶。要理解为什么会发生这种情况,您最好阅读Dave Beazley关于该主题的文章和演示文稿。他的作品非常全面且易于理解,我认为在这里完全没有必要重复其中的任何内容(结论除外)。
现在让我们做同样的事情,只是使用进程而不是线程。Python 出色的多处理模块使进程像线程一样易于启动和管理。事实上,它提供了与线程模块非常相似的 API。这是多进程分解器:
def mp_factorizer(nums, nprocs):def worker(nums, out_q):""" The worker function, invoked in a process. 'nums' is alist of numbers to factor. The results are placed ina dictionary that's pushed to a queue."""outdict =for n in nums:outdict[n] = factorize_naive(n)out_q.put(outdict)# Each process will get 'chunksize' nums and a queue to put his out# dict intoout_q = Queue()chunksize = int(math.ceil(len(nums) / float(nprocs)))procs = []for i in range(nprocs):p = multiprocessing.Process(target=worker,args=(nums[chunksize * i:chunksize * (i + 1)],out_q))procs.append(p)p.start()# Collect all results into a single result dict. We know how many dicts# with results to expect.resultdict =for i in range(nprocs):resultdict.update(out_q.get())# Wait for all worker processes to finishfor p in procs:p.join()return resultdict
这里与线程解决方案唯一真正的区别是输出从工作线程传回主线程/进程的方式。使用multiprocessing,我们不能简单地将 dict 传递给子进程并期望它的修改在另一个进程中可见。有几种方法可以解决这个问题。一种是使用来自multiprocessing.managers.SyncManager的同步字典。我选择的是简单地创建一个Queue,并让每个工作进程将结果字典放入其中。mp_factorizer然后可以将所有结果收集到一个字典中,然后加入进程(请注意,如多处理文档中所述,加入应该在进程写入的队列中的所有结果都被消耗之后调用)。
我运行了相同的基准测试,将mp_factorizer的运行时间添加到图表中:
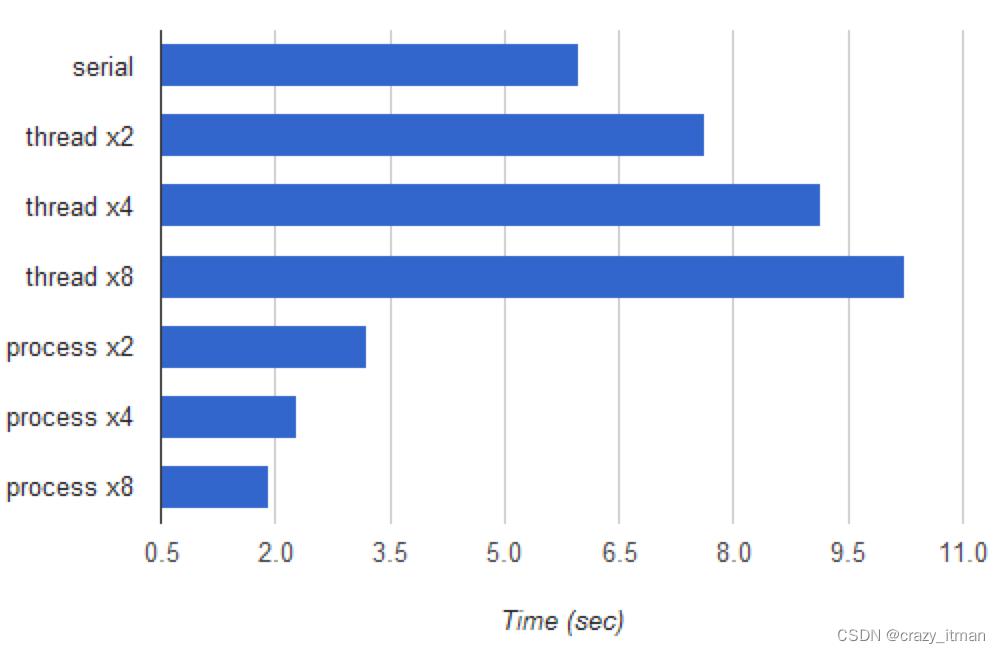
如您所见,有很好的加速。最快的多进程版本(拆分为 8 个进程)运行速度是串行版本的 3.1 倍。虽然我的 CPU 只有 4 个物理内核(每个内核中的一对硬件“线程”共享大量执行资源),但 8 进程版本运行速度更快,这可能是由于操作系统没有分配在“繁重”任务之间优化 CPU。加速与 4 倍相去甚远的另一个原因是工作在子流程之间的分配不均。有些数字的因式分解速度比其他数字快得多,目前没有人关注工作人员之间的负载平衡任务。这些是值得探索的有趣主题,但超出了本文的范围。对于我们的需求,最好的建议是运行基准测试并根据结果决定最佳并行化策略。
这篇文章的目标有两个。第一,提供一个简单的演示,说明 Python 线程如何不利于加速受 CPU 限制的计算(它们实际上非常适合减慢它们的速度!),而多处理确实以并行方式使用多核 CPU,正如预期的那样. 第二,展示多处理使编写并行代码与使用线程一样简单。在进程之间同步对象比在线程之间同步对象需要做更多的工作,但除此之外代码非常相似。如果你问我,对象同步更困难是件好事,因为共享的对象越少越好。这就是为什么多进程编程通常被认为比多线程编程更安全且更不容易出错的主要原因。
以上是关于Python - 使用多处理并行处理受 CPU 限制的任务的主要内容,如果未能解决你的问题,请参考以下文章