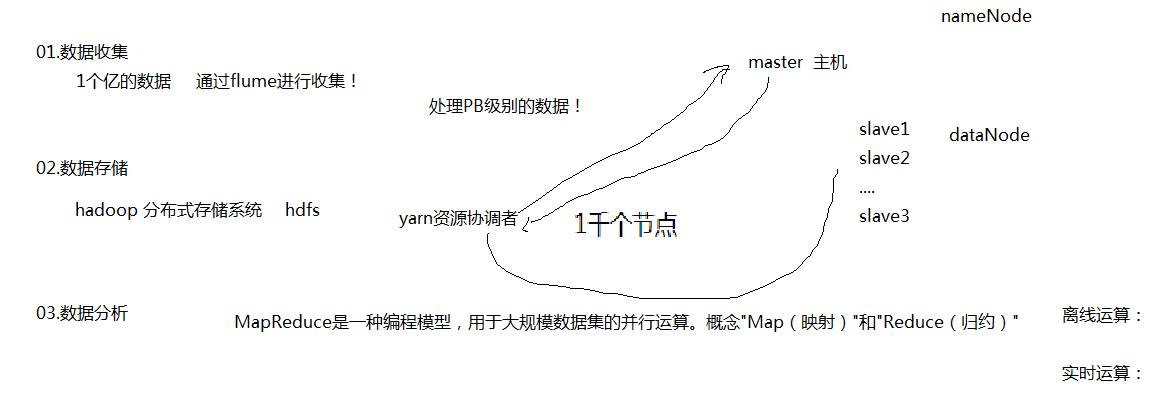
大数据
Posted Hei-po
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据相关的知识,希望对你有一定的参考价值。
1.1 数据流模型
一、Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
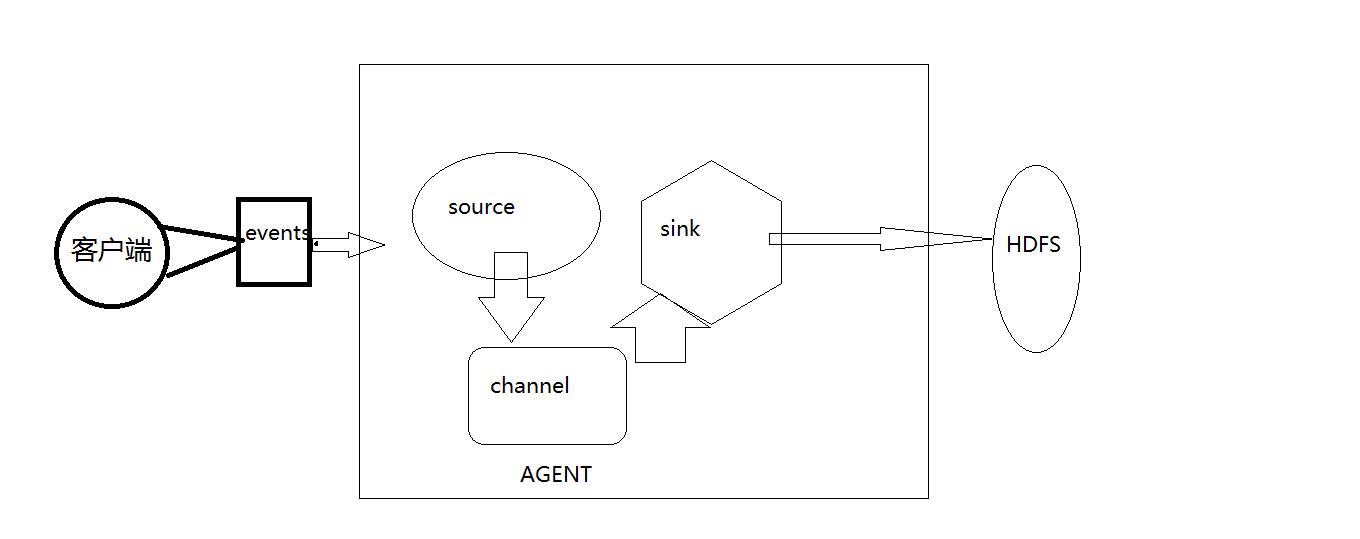
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source,比如上图中的Web Server生成。当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
很直白的设计,其中值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。
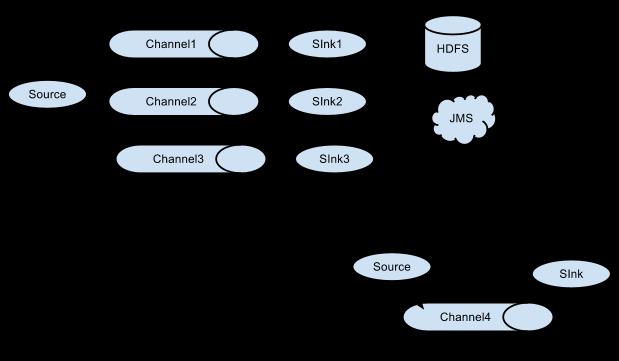
如果你以为Flume就这些能耐那就大错特错了。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes。如下图所示:
1.2 高可靠性
作为生产环境运行的软件,高可靠性是必须的。
从单agent来看,Flume使用基于事务的数据传递方式来保证事件传递的可靠性。Source和Sink被封装进一个事务。事件被存放在Channel中直到该事件被处理,Channel中的事件才会被移除。这是Flume提供的点到点的可靠机制。
从多级流来看,前一个agent的sink和后一个agent的source同样有它们的事务来保障数据的可靠性。
1.3 可恢复性
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
2、配置示例
省略。。。
http://m.blog.csdn.net/article/details?id=49849955
以上是关于大数据的主要内容,如果未能解决你的问题,请参考以下文章