Numpy笔记 · Permutation
Posted Laurence Geng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Numpy笔记 · Permutation相关的知识,希望对你有一定的参考价值。
Numpy中的Permutation(意为置换)是指对一个数据集以随机顺序重新排序(其实就是一个“打乱顺序的洗牌操作”),该函数为:
numpy.random.permutation
与Permutation相类似的是shuffle, 区别在于shuffle直接在原来的数组上进行操作,改变原来数组的顺序,无返回值。而permutation不直接在原来的数组上进行操作,而是返回一个新的打乱顺序的数组,并不改变原来的数组。
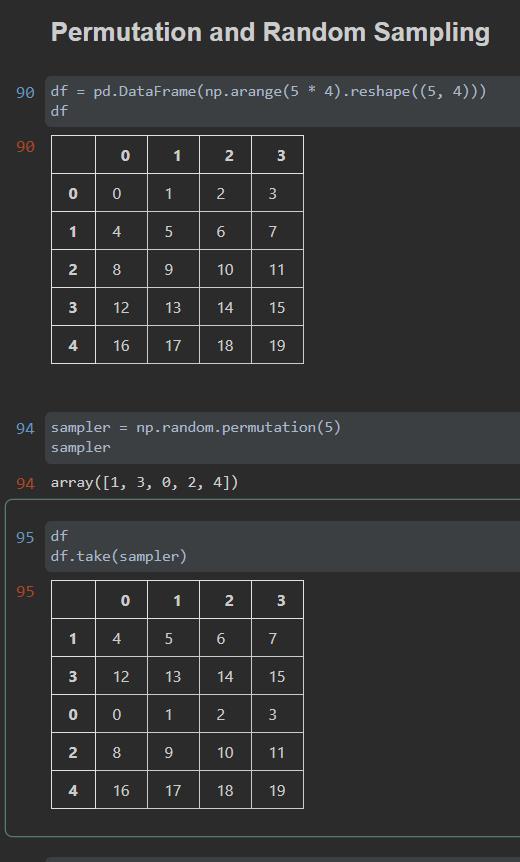
如下代码演示了Permutation函数的工作方式:首先生成一个20个元素的自增数列,并转置为一个5行4列的DataFrame,然后通过np.random.permutation(5)创建了一个数组,我们注意一下这个数组的特点:参数5决定了数组由5个元素组成,从0到4,但是元素顺序是随机的。把这个数组给到df的take方法,df的take方法将以数组中的元素的值作为新的索引重新进行排序,如下图所示,将Permutation数组[1, 3, 0, 2, 4]给到take方法,意味着:原来df(二维数组)中的第1行(从0行开始计)将作为第0行,故:4 5 6 7这一行成为了新df中的第0行,同理,原来df中的第3行将作为第1行,故:12 13 14 15这一行成为了新df中的第1行。
在Handson ML一书中,有一个Permutation的典型应用场景:进行训练数据集和测试数据集的切分,切分时,一个重要的原则是:选择的记录应该是随机的,所以我们可以利用permutation先生成随机的索引数组,然后按期望的比例划走训练记录和测试记录的索引子集,最后通过iloc方法基于这些索引将数据切分出去:
import numpy as np
def split_train_test(data, test_ratio):
# 顾名思义,返回的索引集合已经是shuffle过的了
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
以上是关于Numpy笔记 · Permutation的主要内容,如果未能解决你的问题,请参考以下文章