Oracle 数据泵导入导出(expdp/impdp)
Posted 莫娇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle 数据泵导入导出(expdp/impdp)相关的知识,希望对你有一定的参考价值。
--参考http://www.lanstonwu.com/using-datapump-export-and-import-data/
--参考http://www.cnblogs.com/wbzhao/archive/2012/04/06/2434702.html
一、前期准备
1.以SSH远程登录服务器,找到指定目录下创建数据泵中间文件(.DMP)存放的目录:

/*rmdir /home/oracle/pump_dir --删除空目录*/
2.以管理员sys创建逻辑目录
create or replace directory pump_dir as \'/home/oracle/pump_dir\';
3.给user用户赋予在指定目录的操作权限,最好以sys等管理员授权
grant read,write on directory pump_dir to user;
4.查看管理理员目录
select * from dba_directories;
/*drop directory pump_dir;--删除目录*/
二、导出数据
--------------------- !!! 大写的分割线 !!! ---------------------
使用 \'/as sysdba\' 模式的前提是设置操作系统环境变量ORACLE_SID
export ORACLE_SID=instance_name
--------------------------------------------------------------
1.全库导出(full)
a.expdp parfile=expdp_full_20170525.txt
--expdp_full_20170525.txt
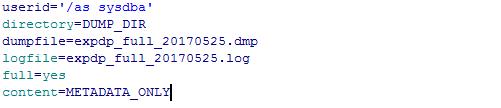
b.expdp sysdba/pwd directory=DUMP_DIR dumpfile=expdp_full_20170525.dmp logfile=expdp_full_20170525.log full=y content=METADATA_ONLY
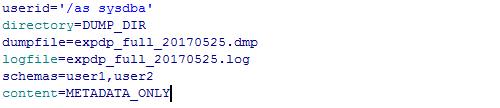
2.用户模式导出(schemas)
3.表模式导出(tables)
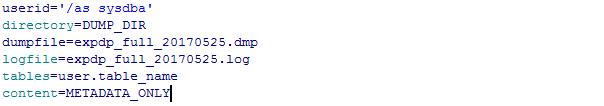
4.限定条件导出(query)

三、导入数据
/*导入数据时要确认导入的用户是否存在,是否有权限访问表空间、是否具有读写directory的权限*/
1.指定用户导入,只导入结构(content=METADATA_ONLY);若目标库user1,user2已存在,则源库和目标库user1,user2的表空间要一致,不然会报错;
impdp parfile=impdp_20170525.txt
--参数文件impdp_20170525.txt

2.将用户1的数据导入用户2 (以此类推,还可以重定义表[remap_table]、表空间[remap_tablespace]导入)
impdp parfile=impdp_20170525.txt
--参数文件impdp_20170525.txt

--/*对于后面的user2,目标库中可以有也可以没有,如果没有系统会自动建立这个用户*/这个暂时还没有试验过,有空可以试试
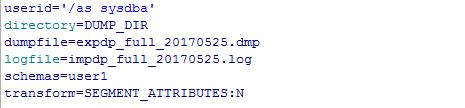
3.将用户数据导入用户默认表空间
四、导入远程数据库数据
/*由于物理空间不足或数据量太大传输不便,可以在目标端使用db_link连接,导入远程数据库数据*/
1.源端用户赋权限;
grant datapump_exp_full_database to USER1;
2.目标库用户赋权限;
grant datapump_imp_full_database to USER2;
3.目标库创建连接远程目标数据库DBLINK
CREATE PUBLIC DATABASE LINK TO_TEST
CONNECT TO USER1 IDENTIFIED BY password
USING \'(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.x.x.x)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = db_name)
)
)\';
4.导入数据
impdp USER1/password NETWORK_LINK=TO_TEST REMAP_SCHEMA=USER1:USER2 TABLE_EXISTS_ACTION=TRUNCATE TABLES=USER1.TABLE_NAMEL DIRECTORY=IMPDP_DIR LOGFILE=USER1.TABLE_NAME.log CONTENT=DATA_ONLY PARALLEL=4
五、参数介绍
1.USERID:命令行的第一个参数
2.DIRECTORY:转储文件和日志文件存放的目录
3.DUMPFILE:目标转储文件
4.LOGFILE:日志文件
5.FULL:指定全库导出
FULL={Y | N}
6.CONTENT:指定要导出的数据,默认为ALL
CONTENT={ALL|DATA_ONLY|METADATA_ONLY}
ALL:导出对象定义及所有数据
DATA_ONLY:只导出对象数据
METADATA_ONLY:只导出对象定义
7.SCHEMAS:指定执行方案模式导出,默认为当前用户模式
8.TABLES:指定表模式导出
9.TABLESPACES:按表空间模式导出
10.PARALLEL:并行,指定执行导出操作的并行进程个数,默认值为1
11.INCLUDE:指定导出时要包含的对象类型及相关对象
INCLUDE = object_type[:name_clause] [,… ]
eg:INCLUDE=TABLE:"IN(SELECT TABLE_NAME FROM CSB_BFB)"
12.EXCLUDE:指定导出执行时要排除的对象类型及相关对象
13.NETWORK_LINK:指定数据库链名,如果要将远程数据库对象导出到本地例程的转储文件中,必须设置该选项
14.TABLE_EXISTS_ACTION={skip|append|truncate|replace}
skip:如果已存在表,则跳过并处理下一个对象;
append:为表增加数据;truncate是截断表,然后为其增加新数据;
replace:删除已存在表,重新建表并追加数据;
以上是关于Oracle 数据泵导入导出(expdp/impdp)的主要内容,如果未能解决你的问题,请参考以下文章
100天精通Oracle-实战系列(第24天)Oracle 数据泵表导出导入
100天精通Oracle-实战系列(第24天)Oracle 数据泵表导出导入