Hadoop快速入门
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop快速入门相关的知识,希望对你有一定的参考价值。
传说中的Hadoop,我终于来对着你唱"征服"了,好可爱的小象,!J
总的来说,hadoop的思路比较简单(map-reduce),就是将任务分开进行,最后汇总。但这个思路实现起来,比较复杂,但相对于几年前Intel等硬件公司提出的网格运算等方式,显得更加开放。
你难任你难,哥就是头铁!
Tip:实践应用是核心,本文概念为主,有些部分可能会有些晦涩,直接跳过就好(不是特别重要)。
本文代码实践在:https://github.com/wanliwang/cayman/tree/master/cm-web的test->backupcode->hadoop部分。


提到列式(Column Family)数据库,就不得不提Google的BigTable,其开源版本就是我们熟知的HBASE。BigTable建立在谷歌的另两个系统GFS和Chubby之上,这三个系统和分布式计算编程模型MapReduce共同构成Google云计算的基础,Chubby解决主从自动切换的基础。接下来通过一个表格对比来引入Hadoop。
| Google云计算 | Hadoop中的对应 |
| 分布式文件系统GFS | HDFS,负责数据物理存储 |
| 分布式管理服务Chubby | Zookeeper,负责管理服务器 |
| 分布式计算框架MapReduce | MapReduce,负责计算 |
| 分布式数据库BigTable | HBase,负责存取数据 |
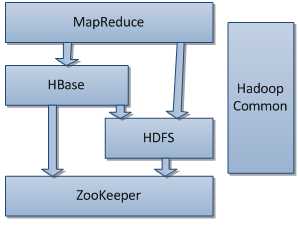
Hadoop是有Apache Lucene的作者Boug Cutting开发的,其主体结构如下图所示。

HDFS(Hadoop File System)
NameNode:整个文件系统的大脑,提供整个系统的目录信息并管理各个数据服务器。
DataNode:分布式文件系统中每一个文件被切割为若干数据块,每个数据块存储在不同服务器,这些就是数据服务器。
Block:每个被切分的数据块就是一段文件内容,其是基本的存储单位,被称为数据块,典型大小为64MB。
Tip:由于硬件错误是常态,HDFS是很多台Server的集合,因而错误检测和恢复是核心功能;其以流式读为主,做批量操作,关注数据访问的高吞吐量。
HDFS采用master/slave架构,一个HDFS集群由一个NameNode和若干DataNode组成,中心服务器NameNode负责管理文件系统的namespace和客户端对文件的访问。DataNode一般一个节点一个,负责管理节点上附带的存储。在内部,一个文件被分成一个或多个block,这些block存储在DataNode集合中。NameNode和DataNode均可运行在廉价的linux机器上,HDFS由java语言开发,跨平台好,总体结构示意图如下所示。
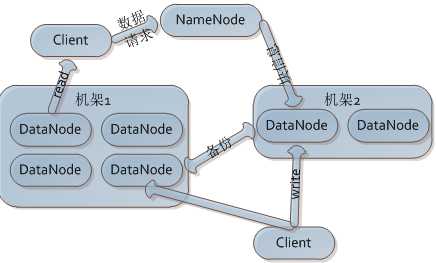
复制:采用rack-aware策略改进数据可靠性和网络带宽的利用;NameNode决定每个DataNode的Rack id;大多数情况,replication因子是3,简单来说就是将一个副本放在本地机架节点,一个副本放在同一机架另一个节点,最后一个放在不同机架;在读取时,会选择最近的副本;NameNode启动时会进入SafeMode状态,该状态时,NameNode不会进行数据块的复制,这是会检测DataNode的副本数量,如果满足要求则认为安全。
NameNode用于存储元数据,任何修改均被Editlog记录,通讯协议基于TCP/IP,可以通过java API调用。
安装Hadoop,步骤如下所示


1 1.安装jdk 2 2.安装hadoop集群情况(创建对应的hadoop应用,用于统一管理, useradd Hadoop, passwd hadoop) 3 node0: 192.168.181.136(NameNode/JobTracker) 4 node1: 192.168.181.132(DataNode/TaskTracker) 5 node2: 192.168.181.133(DataNode / TaskTracker) 6 node3: 192.168.181.134(DataNode / TaskTracker) 7 etc/hosts和hostname设置, 如192.168.181.136 node0, #hostname node0 8 下载hadoop-1.2.1.tar包,放在/home/hadoop,入后修改权限 9 #wget http://mirror.esocc.com/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz 10 #tar –zxvf Hadoop-1.2.1.tar 11 #chown –R Hadoop:Hadoop Hadoop-1.2.1 12 配置ssh无密码登录,在hadoop启动后,NameNode通过SSH(sSecureShell)来启动和停止各个Datanode上的各个守护进程,这就需要节点间执行指令无需密码,因此需要配置SSH运用无密码公钥认证的方法。 13 在本例中,node0为主节点,需要连接node1,2,3,需要确认每台机器安装ssh,并且datanode上的sshd服务启动。 14 #ssh-keygen –t rsa, 默认保存在/home/Hadoop/.ssh, 然后将其复制到每个机器的/home/Hadoop/.ssh/authorized_keys,命令如下,4台机器都需要(显得比较复杂,到时看看docker或者.sh脚本文件) 15 #su Hadoop 16 #cd /home/Hadoop 17 # ssh-keygen –t rsa 18 #cd .ssh 19 #cp id_rsa.pub authorized_keys 20 #ssh localhost 21 #ssh node0 22 在node0,1,2,3上交换公钥 23 #scp authorized_keys [email protected]:/tmp, 复制keys到node1的/tmp目录 24 #cat /tmp/authorized_keys>>/home/Hadoop/.ssh/authorized_keys 25 在node0上有了所有公钥后,在复制node0上key到其他机器 26 #scp /home/Hadoop/.ssh/authorized_key [email protected]:/home/hadoop/.ssh 27 #chmod 644 authorized_keys,设置文件权限并测试 28 将当前用户切换到hadoop,如果集群内机器环境一直,可以在一台机器配置好后,用scp命令将master上的hadoop复制到每一个slave 29 修改hadoop-1.2.1/conf,配置hadoop-env.sh文件,添加JAVA_HOME路径 30 配置conf/core-site.xml 31 <configuration> 32 <!-- NameNode的URI --> 33 <property> 34 <name>fs.default.name</name> 35 <value>hdfs://node0:49000</value> 36 </property> 37 <!-- hadoop时默认临时路径,如果在新增节点时DataNode无法启动,就删除此文件 --> 38 <property> 39 <name>hadoop.tmp.dir</name> 40 <value>/home/hadoop/hadoop-1.2.1/var</value> 41 </property> 42 <property> 43 <name>dfs.support.append</name> 44 <value>true</value> 45 </property> 46 <!-- 关闭权限检查,方便之后使用hadoop-eclipse插件访问hdfs --> 47 <property> 48 <name>dfs.permissions</name> 49 <value>false</value> 50 </property> 51 </configuration> 52 53 配置conf/mapred-site.xml 54 <configuration> 55 <!-- JobTracker的主机和端口 --> 56 <property> 57 <name>mapred.job.tracker</name> 58 <value>/node0:49001</value> 59 </property> 60 <!-- 目录需要提前创建,注意使用chown -R来修改权限,为0777 --> 61 <property> 62 <name>mapred.local.dir</name> 63 <value>/home/hadoop/hadoop-1.2.1/var</value> 64 </property> 65 </configuration> 66 67 配置hdfs-site.xml 68 <configuration> 69 <!-- dir是NameNode持久存储名字空间和事务日志的本地文件系统路径,当该值是一个逗号分隔的目录列表是,nametable数据将会被复制到所有目录中做冗余备份 --> 70 <property> 71 <name>dfs.name.dir</name> 72 <value>/home/hadoop/name1</value> 73 </property> 74 <property> 75 <name>dfs.data.dir</name> 76 <value>/home/hadoop/data1</value> 77 </property> 78 <!-- 数据备份数量 --> 79 <property> 80 <name>dfs.replication</name> 81 <value>3</value> 82 </property> 83 </configuration> 84 85 配置主从节点 86 conf/masters: node0 87 conf/slaves: node1,2,3 88 启动与测试 89 #hadoop namenode –format 90 #/home/hadoop/xxx/bin/start-all.sh
在分布式模式下,hadoop配置文件中不能使用ip,必须使用主机名,安装hadoop必须在所有节点上使用相同配置和安装路径,并用相同用户启动。Hadoop中的HDFS和Map-Reduce可以分别启动,NameNode和JobTracker可以部署到不同节点,但小集群一般在一起,注意元数据安全即可。
Hdfs常见操作,请见下表所示,在实践中,一般都是通过API调用,了解下就好
| 命令 | 诠释 | 命令 | 诠释 |
| #cat | Hadoop fs –cat uri输出内容 | #chgrp | 修改文件所属组 |
| #chmod | 修改文件去哪先 | #chown | 修改文件拥有者 |
| #put #copyFromLocal | 从本地文件系统复制到目标系统 | #get #getmerge #copToLocal | 复制文件到本地系统 Hadoop fs –get hdfs://host:port/user/Hadoop/file local file |
| #cp | 复制文件 | #du,#dus | 显示目录、文件大小 |
| #expunge | 清空回收站 | #ls, lsr | 显示文件信息 |
| #mv #movefromLocal | 移动文件 | #rm #rmr | 删除文件 |
| #mkdir | 创建目录 | #setrep | 改变文件副本系数 |
| #stat | 返回统计信息 hadoop fs –stat path | 其他 | #tail #touchz |
| #test | #text |
通过Java调用hdfs的示例如下所示,其实就是一个文件系统
1 public void hdfsOpertion() throws Exception { 2 Configuration conf = new Configuration(); 3 FileSystem hdfs = FileSystem.get(conf); // 获得HDFS文件系统对象 4 FileSystem local = FileSystem.getLocal(conf);// 获得本地文件系统 5 Path inputDir = new Path("in_xxx"); 6 Path hdfsFile = new Path("fs_xxx"); 7 8 try { 9 FileStatus[] inputFiles = local.listStatus(inputDir);// 获得目录文件列表 10 FSDataOutputStream out = hdfs.create(hdfsFile);// 生成hdfs输出流 11 for (int i = 0; i < inputFiles.length; i++) { 12 System.out.println(inputFiles[i].getPath().getName()); 13 FSDataInputStream in = local.open(inputFiles[i].getPath());// 打开本地输入流 14 byte[] buffer = new byte[256]; 15 int bytesRead = 0; 16 while ((bytesRead = in.read(buffer)) > 0) { 17 out.write(buffer, 0, bytesRead); 18 } 19 in.close(); 20 } 21 out.close(); 22 } catch (Exception ex) { 23 ex.printStackTrace(); 24 } 25 }

-
Map Reduce核心概念
Job: 用户的每一个计算请求就是一个作业
JobTracker:用户提交作业的服务器,同时它还负责各个作业任务的分配,管理所有的任务服务器。
Task:一个都需要拆分,交个多个服务器完成,拆分出来的执行单位就是任务
TaskTracker:就是任劳任怨的工人,负责执行具体的任务。
-
Map Reduce计算模型
在hadoop中,每一个MapReduce任务被初始化为一个Job,每个Job又被分为两个阶段:Map阶段、Reduce阶段。这两个阶段分别用两个函数表示,Map函数接受一个<key,value>输入,然后产生一个<key,value>的中间输出;之后hadoop会将具有相同中间key的value集合传给Reduce函数,之后Reduce处理后得到<key,value>形式输出。

在Java中接入Hadoop的配置与代码如下所示。
1 Maven: 2 <dependency> 3 <groupId>org.apache.hadoop</groupId> 4 <artifactId>hadoop-common</artifactId> 5 <version>${hadoop.version}</version> 6 </dependency> 7 <dependency> 8 <groupId>org.apache.hadoop</groupId> 9 <artifactId>hadoop-hdfs</artifactId> 10 <version>${hadoop.version}</version> 11 </dependency> 12 <dependency> 13 <groupId>org.apache.hadoop</groupId> 14 <artifactId>hadoop-mapreduce-client-core</artifactId> 15 <version>${hadoop.version}</version> 16 </dependency> 17 18 Code: 19 public class WordCountNew extends Configured implements Tool { 20 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { 21 private final static IntWritable one = new IntWritable(1); 22 private Text word = new Text(); 23 24 @Override 25 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) 26 throws IOException, InterruptedException { 27 String line = value.toString(); 28 // 字符串分解器 29 StringTokenizer tokenizer = new StringTokenizer(line); 30 while (tokenizer.hasMoreTokens()) { 31 word.set(tokenizer.nextToken()); 32 context.write(word, one); 33 } 34 } 35 } 36 37 public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { 38 @Override 39 protected void reduce(Text key, Iterable<IntWritable> values, 40 Reducer<Text, IntWritable, Text, IntWritable>.Context context) 41 throws IOException, InterruptedException { 42 int sum = 0; 43 for (IntWritable val : values) { 44 sum += val.get(); 45 } 46 context.write(key, new IntWritable(sum)); 47 } 48 } 49 50 @Override 51 public int run(String[] arg0) throws Exception { 52 Job job = new Job(getConf()); 53 job.setJarByClass(WordCountNew.class); 54 job.setJobName("wordcount"); 55 job.setOutputKeyClass(Text.class); 56 job.setOutputValueClass(IntWritable.class); 57 job.setMapperClass(Map.class); 58 job.setReducerClass(Reduce.class); 59 job.setInputFormatClass(TextInputFormat.class); 60 job.setOutputFormatClass(TextOutputFormat.class); 61 FileInputFormat.setInputPaths(job, new Path("xxx01.txt")); 62 FileOutputFormat.setOutputPath(job, new Path("xxx02.txt")); 63 boolean success = job.waitForCompletion(true); 64 return success ? 0 : 1; 65 }
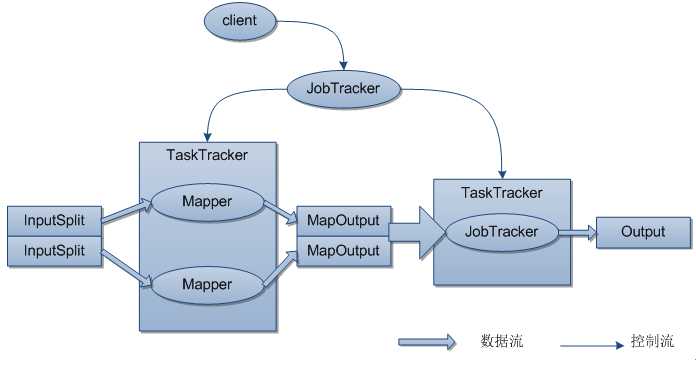
MapReduce的数据流和控制流

zookeeper主要用来解决分布式应用中经常遇到的数据管理的问题,如统一命名服务、状态同步服务、集群管理和分布式应用配置项的管理,Zookeeper典型的应用场景(配置文件的管理、集群管理、同步锁、Leader选举和队列管理等)。
Zookeeper配置安装的步骤如下所示
下载zookeeper包 修改zoo.cfg配置文件 initLimit=5 #Zookeeper中链接到Leader的Follower服务器初始化链接能忍耐的心跳间隔数:5*2000=10秒 syncLimit=2 #请求应答的时间长度2*2000=4秒 dataDir=/home/Hadoop/zookeeper server.1=node1:2888:3888 #用于选举时服务器相互通信的端口 server.2=node2:2888:3888 server.3=node3:2888:3888 配置myid文件,在dataDir目录,判断时哪个server 启动zookeeper,bin/zkServer.sh start
ZooKeeper数据模型,其会维护一个层次关系的数据结构,非常类似标准文件系统
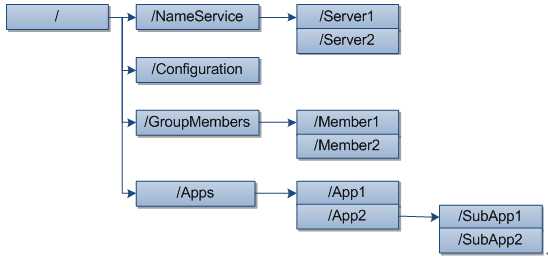
ZooKeeper的基础使用,其作为一个分布式服务框架,主要用于解决分布式集群的一致性问题,它提供类似文件系统目录节点树方式的数据存储,并会维护和监控数据的状态变化,其常见方法如下所示。
| 方法 | 诠释 |
| Stringcreate | 创建一个给点的目录节点path并设置数据 |
| Statexists | 判断某个path是否存在,并设置监控这个目录节点 |
| Delete | 参数path对应目录节点 |
| StatsetData,getData | 设置数据,获取数据 |
| addAuthInfo | 将自己授权信息发送给服务器 |
| StatsetACL,getACL | 设置目录节点访问权限,获取权限列表 |
java调用zookeeper的API示例如下
1 public void testName() throws Exception { 2 // 1.创建一个和服务器的链接 3 ZooKeeper zk = new ZooKeeper("localhost:" + CLIENT_PORT, CONNECT_TIMEOUT, new Watcher() { 4 @Override 5 public void process(WatchedEvent event) { 6 System.out.println(String.format("已经触发了%s事件", event.getType())); 7 } 8 }); 9 10 // 2.创建一个目录节点 11 zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); 12 // 3.创建子节点 13 zk.create("/testRootPath/testChildrenPathOne", "testChildrenPathOne".getBytes(), Ids.OPEN_ACL_UNSAFE, 14 CreateMode.PERSISTENT); 15 System.out.println(new String(zk.getData("/testRootPath", false, null))); 16 // 4.查找子目录列表 17 System.out.println(zk.getChildren("/testRootPath", true)); 18 // 5.修改子目录节点数据 19 zk.setData("/testRootPath/testChildrenPathOne", "modifyChildrenPathOne".getBytes(), -1); 20 System.out.println("目录节点状态:[" + zk.exists("/testRootPath", true) + "]"); 21 // 6.删除节点 22 zk.delete("/testRootPath/testChildrenPathOne", -1); 23 // 7.关闭链接 24 zk.close(); 25 }
ZooKeeper的典型应用场景
统一命名服务(Name Service):分布式应用,通常需要一整套的命名规则,一般使用树形命名,这儿和JNDI很相似。
配置管理:ZooKeeper统一管理配置信息,保存在对应目录,一旦变化,对应机器就会收到通知(观察者)。
集群管理:ZooKeeper不仅能维护当前集群中及其的服务状态,并能选出一个总管(Leader Election),从而避免单点故障,示例代码如下。
共享锁(Locks):共享锁在同一个进程容易实现,但再不同Server见不好实现,但Zookeeper却很容易实现,方式就是需要获取锁的Servere创建一个EPHEMERAL_SEQUENTIAL目录节点,然后调用getChildren方法获得当前目录节点列表中最小的目录节点,并判断,如果未自己建立,则获得锁,如果不是就调用exist方法监控节点变化,一直到自己创建的节点时最小,从而获得锁,释放很贱,只要删除前面自己创建的目录节点就OK。
队列管理(Queue Management):可以处理两类队列,一种是当成员齐聚时,队列才可用,否则一直等待,被称为同步队列;一种是按照FIFO方式进行入队和出队,例如实现生产-消费者模型。

HBase(逻辑结构)是BigTable的开源版,其建立在HDFS(物理结构)之上,提供高可靠性、高性能、列存储和可伸缩、实时读写的数据库系统。它结余NOSQL和RDBMS之间,仅能通过主键和主键range来检索数据,支持单行事务(可通过hive支持来实现多表join等复杂操作),主要用于存储非结构和半结构化的松散数据。与Hadoop一样,Hbase主要依靠横向扩展来提高计算和存储能力。
Hbase的表具有以下特点:
大:一个表可以有上亿行
面向列:面向列族的存储和权限控制,列族独立检索。
稀疏:对于空的列,并不占用空间,因此表可以设计的非常稀疏。
-
逻辑视图:HBase以表的形式存储数据,表由行和列组成,列划分为若干个列族row family,如下表所示。
| Row Key | Column-family1 | Column-family2 | |
| Column1 | Column1 | Column1 | Column2 |
| Key1 | t2:abc t1:bcd | t1:354 | |
| Key2 | t3:efy t1:uio | t2:tyi t1:456 | |
Row Key:检索数据的主键,访问HBase中的行,可以通过单个row key(字典序,数值型数据需要补0)访问;通过row key的range的访问;全表扫描。
列族:表中的每一列,都归属于列族,列族是表schema的一部分,必须在使用前定义,而列不是,关键理解。列名都以列族作为前缀,例如courses:history和courses:math都数据courses列族。
时间戳:通过row和column确定一个存储单元cell,每个cell保存同一份数据的多个版本,通过时间戳来索引。时间戳为64位证书,精确到毫秒,按时间倒序排列。为了避免版本过多,一般通过个数或时间来回收。
Cell:由{row key, column(=<family>+<label>),version}唯一确定的单元,cell中数据没有类型,以字节码存储。
-
物理存储:指如何将大表分布的存储在多台服务器。
特点:Table上所有行使用row key排列;Table在行方向上分割为多个HRegion;HRegion按大小分割,每个表已开始只有一个region,随着数据不断插入,region增大,当超过阈值是,会分裂成连个新的HRegion;HRegion是HBase中分布式存储和负载均衡最小单元,表示不同Region可以分布在不同RegionServer上;HRegion是分布式存储的最小单元,但不是最小存储单元,实际上,一个Region由多个Store组成,一个Store保存一个columns family,一个Store又由一个memStore和0-多个StoreFile(重点是StoreFile就是一个Hdfs中文件,通过压缩存储减少通信消耗,这儿就找到了对应关系,还可以细分,就不介绍了)组成。(脑海里有了大体的印象)
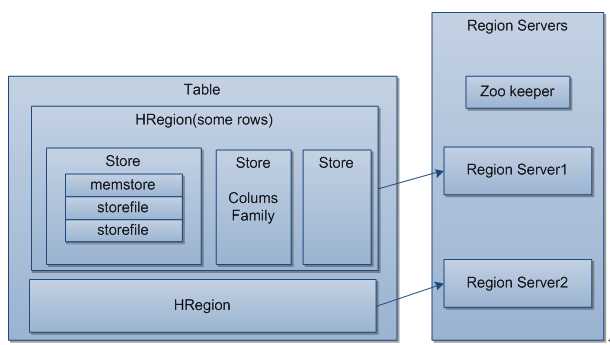
-
系统架构
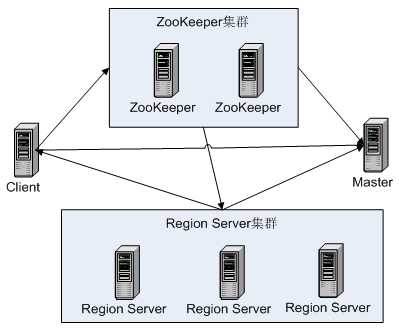
Client:包含访问HBase接口,client维护一些cahce来加快访问,比如region未知信息。
ZooKeeper:保证任何时候集群只有一个master;存储所有region寻址接口;实施监控Region Server状态,将其上下线消息实时通知给master;存储Hbase的schema,包含哪些table,每个table的column family;为region server分配region;负责Region server的负载均衡;发现失效的Region Server并重新分配其上Region,GFS上的垃圾文件回收;处理schema更新请求。
Region Server:维护Master分配给它的Region,处理这些Region的IO请求;切分在运行中变得过大的Region。
Tip:可以看到client访问HBase数据的过程并不需要master参与,寻址访问zookeeper和Region Server,数据读写访问Region Server,master只维护table和Region的元数据,负载低。
-
关键算法和流程
Region定位:大表使用三层类似B+树的结构来存储Region位置,第一次保存zookeeper中数据,持有RootRegion位置;第二层RootRegion是.META表的第一个Region,其中保存了其他Region的位置;第三层是个特殊的表,存储HBase中所有数据表的Region位置信息。
读写过程:HBase使用MemStore和StoreFile存储对表的更新。数据在更新时首先写入Log和MemStore,MemStore中的数据是排序的,当MemStore累计到一定阈值,会创建新MemStore,并将老MemStore添加到Flush队列,有单独线程写到磁盘,称为一个StoreFile,同时系统会在zookeeper记录一个Redo point,表示更新已经持久化。系统出现问题是,可以使用log来恢复check point之后的数据。(思路和传统数据库一致)
Region分配:任何时刻,一个region只能分配给一个server,master记录了当前可用的Server以及当前region的分配情况,当存在未分配region且有server有可用空间时,master就给这个server发送一个装载请求,分配该region。
Region Server的上下线:master通过zookeeper来跟踪region server状态,当某个server启动时,会在zookeeper的server目录建立代表自己的文件,并获得该文件独占锁,由于master订阅了该目录的变更小心,因此当文件出现增删时,可以接到通知。下线时,断开与zookeeper会话,释放独占锁,这时master会发现并删除对应目录文件,并将原有region分配给其他server。
master的上下线:从zookeeper获取唯一master锁,阻止其他人称为master;扫描zookeeper上server目录,获得region server列表;与每个server通信,获得Region分配的情况;扫描META.region集合,计算得到当前未分配的region,放入待分配列表。
-
安装与配置
1 下载文件wget xxxx/hbase.tar.gz, tar zxvf habse.xxx 2 修改配置文件hbase-env.sh 3 #export JAVA_HOME=user/local/java 4 #export HBASE_CLASSPATH=/home/Hadoop/Hadoop.xx/conf 5 #export HBASE_MANAGES_ZK=false 6 修改hbase-site.xml 7 <configuration> 8 <property> 9 <name>hbase.rootdir</name> 10 <value>hdfs://node0:49000/hbase</value> 11 </property> 12 <property> 13 <name>hbase.cluster.distributed</name> 14 <value>true</value> 15 </property> 16 <property> 17 <name>hbase.tmp.dir</name> 18 <value>/home/hadoop/hbase</value> 19 </property> 20 </configuration> 21 指定Hbase的regionServers 22 最后在系统上设置最大文件数限制和进程数限制/etc/security/limits/conf 23 #hadoop-nofile 3268 24 #hadoop soft/hard nproc 32000
-
常见操作
比如创建一个如下表格
| #name | #grad | #course:math | #course:art |
| Xionger | 1 | 62 | 60 |
| xiongda | 2 | 100 | 98 |
1 create‘scores‘, ‘grade‘, ‘course‘ #创建scores表,列族为grade,course 2 list #查看有哪些表 3 describe ‘scores‘ #查看表构造 4 put ‘scores‘, ‘xionger‘,‘course:math;, ‘62‘ #插入一条数据 5 get ‘score‘ , ‘xionger‘ #获得熊二成绩 6 scan ‘scores‘#扫描表中所有数据 7 scan ‘scores‘, {columns=>[‘course:‘]} #获得courses列族数据
Tip:
终于完成了,帅,这部分内容之后重点在于既有的集成解决方案,包括docker上的部署等。
此外,有空考虑区块链方面的学习,同时把数据结构好好再学习下,感觉还是不太OK。,比如B+树。
参考资料:
-
皮雄军. NoSQL数据库技术实战[M]. 北京:清华大学出版社, 2015.
以上是关于Hadoop快速入门的主要内容,如果未能解决你的问题,请参考以下文章