Chapter 1 大数据处理框架概览
Posted 溱溱~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Chapter 1 大数据处理框架概览相关的知识,希望对你有一定的参考价值。
大数据及其带来的挑战
大数据具有 数据量大(Volume)、数据类型多样(Variety)、产生与处理速度快(Velocity)、价值高(Value) 的4V特性。
关系型数据库解决了关系型数据的存储与OLTP(On-line Transcation Processing,在线事务处理)问题,数据仓库解决了数据建模及OLAP(On-line Analytical Processing,在线分析处理)问题。
大数据处理框架
MapReduce分布式计算框架(Google):基于分治、归并和函数式编程思想;
Dryad分布式计算框架(微软):不同于MapReduce固定的数据处理流程,Dryad允许用户将任务处理组织成有向无环图(DAG,Directed Acyclic Graph)来获得更强的数据处理表达能力;
Spark分布式处理框架(UC Berkeley 的 AMPLab):基于内存,适合迭代计算的分布式处理框架,允许用户将可重用的数据缓存(cache)到内存中,同时利用内存进行中间数据的聚合,极大缩短了数据处理的时间。
这些大数据处理框架拥有共同的编程模型,即 MapReduce-like 模型,采用“分治-聚合”策略来对数据进行分布并行处理。
大数据应用及编程模型
MapReduce编程模型可以被简单地表示为:
map阶段:map<K1,V1> => list<K2,V2>
reduce阶段:reduce<K2,list(V2)> =>list<K3,V3>
大数据处理框架的四层架构
大数据处理框架大体可以分为4层结构:用户层、分布式数据并行处理层、资源管理与任务调度层、物理执行层。在用户层中,用户需要准备数据、开发用户代码、配置参数。分布式数据并行处理层根据用户代码和配置参数,将用户代码转换为逻辑处理流程(数据单元及数据依赖关系),然后将逻辑处理流程转换为物理执行计划(执行阶段及执行任务)。资源管理与任务调度层根据用户提供的资源来分配资源容器,并将任务(task)调度到合适的资源容器上运行。物理执行层实际运行具体的数据处理任务。
1)用户层
①输入数据
对于批式大数据处理框架,如Hadoop、Spark,用于在提交作业(job)之前,需要提前准备好输入数据,输入数据一般以分块(如以128MB为一块)的形式预先存储,可以存储在分布式文件系统(如Hadoop的分布式文件系统 HDFS)和分布式Key-Value 数据库(如HBase)上,也可以存放到关系数据库中。
对于流式大数据处理框架,如Spark Streaming和Apache Flink,输入数据可以来自网络流(socket)、消息队列(Kafka)等。数据以微批(多条数据形成一个微批,称为mini-batch)或者连续(一条接一条,称为coutinuous)的形式进入流式大数据处理框架。
对于大数据应用,数据的高效读取常常称为影响系统整体性能的重要因素。为了提高应用读取数据的性能,学术界研究了如何通过降低磁盘IO来提高性能。例如,PACMan 根据一定策略提前将task所需的部分数据缓存到内存中,以提高task 的执行性能。为了加速不同的大数据影响(如Hadoop、Spark等)之间的数据传递和共享,Tachyon构造了一个基于内存的分布式数据存储系统,用户可以将不同影响产生的中间数据缓存到 Alluxio中,而不是直接缓存到框架中,这样可以加速中间数据的写入和读取,同时也可降低框架的内存消耗。
②用户代码
在实际系统中,用户撰写用户代码后,大数据处理框架会生成一个 Driver程序,将用户代码提交给集群运行。在Hadoop MapReduce 中,Driver程序负责设定输入/输出数据类型,并向Hadoop MapReduce框架提交作业;在Spark中,Driver程序不仅可以产生数据、广播数据给各个task,而且可以收集task的运行结果,最后在Driver程序的内存中计算出最终结果。
③配置参数
一个大数据应用可以有很多配置参数,这些配置参数可以分为两大类:一类是与资源相关的配置参数,另一类是与数据流相关的配置参数。
2)分布式数据并行处理层
分布式数据并行处理层首先将用户提交的应用转换为较小的计算任务,然后通过调用底层的资源管理与任务调度层实行并行执行。
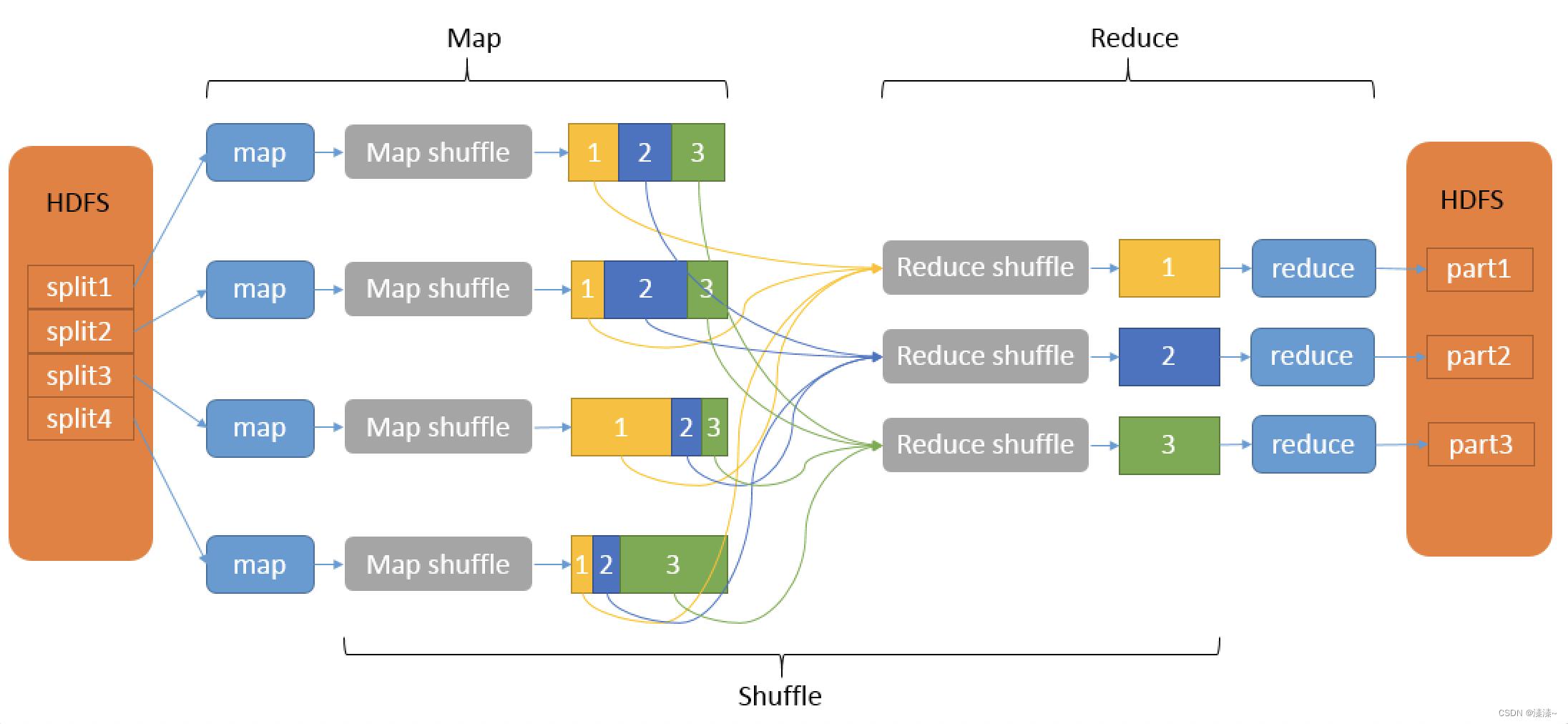
在Hadoop MapReduce中,这个转换过程是直接的。因为MapReduce具有固定的执行流程(map-Shuffle-reduce),可以直接将包含map/reduce函数的作业划分为map和reduce两个阶段。map阶段包含多个可以并行执行的map任务,reduce阶段包含多个可以并行执行的reduce任务。map任务负责将输入的分块数据进行map()处理,并将其输出结果写入缓冲区,然后将缓冲区中的数据进行分区、排序、聚合等操作,最后将数据输出到磁盘上的不同分区中。reduce任务首先将map任务输出的对应分区数据通过网络传输拷贝到本地内存中,内存空间不够时,会将内存数据排序后写入磁盘,然后经过归并、排序等阶段产生reduce()的输入数据,reduce()处理完输入数据后,将输出数据写入分布式文件系统中。
与Hadoop MapReduce不同,Spark上应用的转换过程包含两层:逻辑处理流程、执行阶段与执行任务划分。Spark首先根据用户代码中的数据操作语义和操作顺序,将代码转换为逻辑处理流程。逻辑处理流程包含多个数据单元和数据依赖,每个数据单元包含多个数据分块。然后,框架对逻辑处理流程进行划分,生成物理执行计划。该计划包含多个执行阶段(stage),每个阶段包含若干执行任务(task)。
为了将用户代码转化为逻辑处理流程,Spark和Dryad对输入/输出、中间数据进行了更具体的抽象处理。将这些数据用一个统一的数据结构表示。在Spark中,输入/输出、中间数据被表示成RDD(Resilient Distributed Datasets, 弹性分布式数据集)。在RDD上,可以执行多种数据操作,如简单的map(), 以及负责的 cogroup()、join() 等。一个RDD可以包含多个数据分区,parent RDD 和child RDD之间通过数据依赖关系关联,支持一对一和多对一等数据依赖关系,数据依赖关系的类型由数据操作的类型决定。
3)资源管理与任务调度层
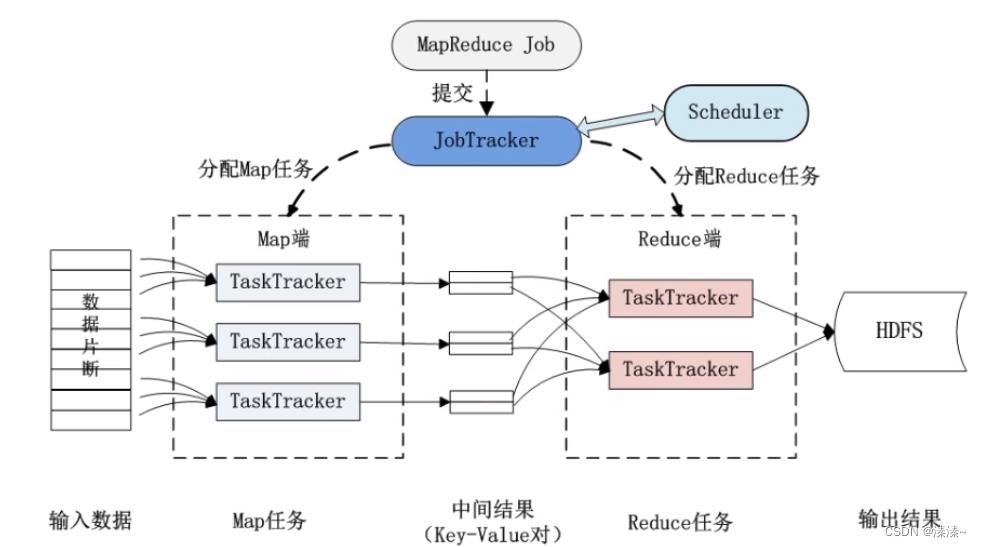
从系统架构上讲,大数据处理框架一般是主-从(Master-Worker)结构。主节点负责接收用户提交的应用,处理请求,管理应用运行的整个生命周期。从节点负责执行具体的数据处理任务(task),并在运行过程中向主节点汇报任务的执行状态。

Spark支持不同的部署模式,如Standalone模式、YARN部署模式和Mesos部署模式等。其中Standalone部署模式与Hadoop MapReduce部署模式基本类似,唯一区别是Hadoop MapReduce部署模式为每个task 启动一个JVM进程运行,而且是在task将要运行时启动JVM,而Spark是预先启动资源管理器(Executor JVM),然后当需要运行task的时,再在Executor JVM启动task线程运行。
在运行大数据应用前,大数据处理框架还需要对用户提交的应用(job)及其计算任务(task)进行调度。任务调度的主要目的是通过设置不同的策略来决定应用或任务获得资源的先后顺序。典型的任务调度器包含先进先出(FIFO)调度器、公平(Fair)调度器等。
4)物理执行层
在物理层执行时首先执行上游stage中的task,完成后执行下游stage中的task。在Hadoop MapReduce中,每个task对应一个进程,每个task以JVM(Java 虚拟机)的方式运行,每个task使用的内存就是JVM的堆内存用量。而在Spark中,每个task对应JVM中的一个线程,一个JVM可能同时运行多个task,因此每个JVM内存由多个task共享。
将task 执行过程中,主要消耗内存的数据分为以下3类:
(1) 框架执行过程中的中间数据。如map任务输出到内存中的数据以及reduce任务在shuffile阶段暂存到内存中的数据。
(2) 框架缓存数据。如用户调用cache()接口缓存到内存中的数据。
(3) 用户代码产生的中间结果。如用户代用map()、reduce()、combine()处理输入数据的时候产生的中间结果。
错误容忍机制
由于不能避免系统和用户代码的Bug、节点宕机、网络异常、磁盘损坏等软硬件可拿性问题,分布式文件系统在设计时一般都会考虑错误容忍机制,在实现时也会针对各种效情况采取相应措施。分布式大数据并行处理框架也不例外,设计了各种针对Master 节点失效、task执行失败等问题的错误容忍机制。然而,对于 task 的执行失败问题,框架的错误容忍机制比较简单,只是选择合适节点重新运行该task。对于某些可靠性问题引起的task执行失败,如内存溢出等,简单地重新运行task并不能解决问题,因为内存溢出的问题很有可能会重复出现。现有框架的另一个局限是,一般用户在出错时很难找到真正的出错原因,即使是十分熟悉框架运行细节的用户,在缺乏分析诊断工具的情况下,也难以快速找到出错原因。
参考文献
《大数据处理框架Apache Spark设计与实现》 作者:许利杰 方亚芬 ISBN:9787121391712
以上是关于Chapter 1 大数据处理框架概览的主要内容,如果未能解决你的问题,请参考以下文章